C++ utils有栈协程内存管理
utils 协程
基于ucontext的协程(参考博主Zip-List随笔的拓展)
man 手册协程
In a System V-like environment, one has the type ucontext_t (defined in <ucontext.h> and described in getcontext(3)) and the four functions getcontext(3), setcontext(3), makecontext(), and swapcontext() that allow user-level context switching between multiple threads of control within a process.
允许在进程中进行用户级线程的切换
int getcontext(ucontext_t *ucp);
int setcontext(const ucontext_t *ucp);
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
int swapcontext(ucontext_t *restrict oucp, const ucontext_t *restrict ucp);The makecontext() function modifies the context pointed to by ucp (which was obtained from a call to getcontext(3)). Before invoking makecontext(), the caller must allocate a new stack for this context and assign its address to ucp->uc_stack, and define a successor context and assign its address to ucp->uc_link. When this context is later activated (using setcontext(3) or swapcontext()) the function func is called, and passed the series of integer (int) arguments that follow argc; the caller must specify the number of these arguments in argc. When this function returns, the successor context is activated. If the successor context pointer is NULL, the thread exits. The swapcontext() function saves the current context in the structure pointed to by oucp, and then activates the context pointed to by ucp.
typedef struct ucontext_t {
struct ucontext_t *uc_link; //
sigset_t uc_sigmask;
stack_t uc_stack; //协程必须有自己的栈,因为协程做到的是函数间跳转,记录栈地址(这里的协程指C++非对称协程,不使用系统主栈)
mcontext_t uc_mcontext;
...
} ucontext_t;uclink指向:当前的上下文被中断后(这个中断是人为的yield,也有可能是因为上下文的函数执行完毕了),要resumed的上下文。 按照next理解吧。
1 makecontext调用之前必须调用getcontext,getcontext()初始化这个ucontext_t,让他指向当前活跃的上下文
2 调用makecontext之前,调用者必须分配新的栈空间,且定义后续的上下文
3 调用makecontext时,绑定的func函数指针,函数指针的传参类似argc,argv的形式。
在哪里绑的?在ucp上,联想函数执行的情况,栈中存放函数地址和参数,只是协程的栈,函数地址,函数参数都要我们自己分配,而且分配了并没有立刻调用,协程的调用是我们自己控制的通过 swapcontext
4 当context被激活时,会调用func。函数执行完毕,执行后续的上下文,后续上下文NULL,协程结束。
5 swapcontext 保存当前上下文,恢复ucp对应的上下文,栈变了。ucp第一次进入就执行绑定的入口函数func,之后再在进入func函数
上次执行到哪里就继续。实现了函数间跳转,不再是线性的执行函数了,yield和resume语义把一个函数一份为2了
关于C++对称协程/非对称协程,有栈/无栈协程的划分,主要区别在于协程调度权限是否掌握在主循环中,调度权在各协程间公平转换的情况称为对称协程,不需要调用栈,即无栈协程,统一使用系统栈空间,CPU cache效率高,如C++协程库;而主循环掌握调度权的情况称为非对称协程,存在明显调度关系,各协程需要分配调度栈存放临时变量,属于有栈(stackful)协程,如Go中的goroutine,腾讯开源libco库等;详见:
libco: C++ libco 介绍与应用_蓝子娃娃的博客-CSDN博客_libco
C++无栈线程优势:c++无栈协程为什么会比有栈协程性能高? - 知乎 (zhihu.com)
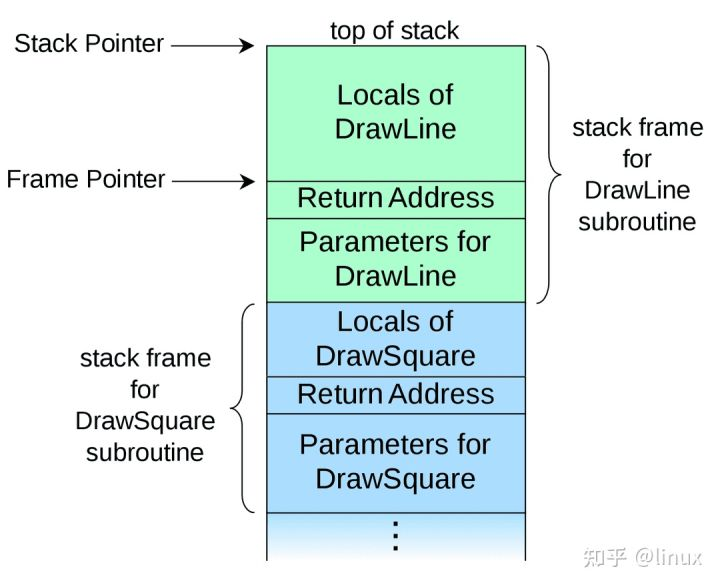
调用栈结构:
异步回调流程如下:
异步模式是注册回调返回,异步消息到来,执行回调函数
协程模式是主循环绑定入口函数后---->resume-----> 协程入口函数的执行异步操作----->yield------->主循环继续直到异步消息到来----->resume-------->协程继续执行yield后的逻辑--------> 入口函数执行完毕uc_link 回到主循环
体会主循环和协程的交替,异步的处理逻辑是在协程中的。看上去就是异步的代码却同步的写,中间由yield分开。主循环即用户负责调度,什么时候resume进入协程(逻辑开始时,异步消息到来后),协程负责yield(异步请求发出后)恢复主循环 recv_cs_inf_arena_p1_info_req
co_ctx main_ctx
resume
---<------- |---<---|
| |
| yield |
--->------- | ↑
...... |
↓ |
---<------- resume |
| |
| |
--->------- |--->---|
finish协程库封装
栈管理
协程栈的分配与释放
int co_stack_init(int co_num_max, int stack_size);
void *co_stack_alloc();
void co_stack_free(void *addr);mmap(COW)分配内存 映射一块连续的内存作为栈,中间加入保护页,防止栈超了写坏其他相邻栈
free_list和used_set管理内存
#include <unistd.h>
#include <sys/mman.h>
#include <list>
#include <unordered_set>
#include "co_stack.h"
struct CO_STACK_POOL
{
void *addr_base = nullptr;
int stack_size = 0;
int co_num_max = 0;
std::list<void *> free_list;
std::unordered_set<void *> used_set;
};
const int C_PAGE_SIZE = 4096;
const int C_STACK_SIZE_MIN = C_PAGE_SIZE * 8;
const int C_GUARD_PAGE_SIZE = C_PAGE_SIZE * 8;
static CO_STACK_POOL gs_pool;
int co_stack_init(int co_num_max, int stack_size)
{
// 不区分栈和保护页,全部分配
// 基于写时拷贝(COW)策略的内存配分技术,只会占用虚拟地址空间(VIRT),不占用真实物理内存(RES/SHR)
size_t virt_mem_size = (stack_size + C_GUARD_PAGE_SIZE) * co_num_max + C_GUARD_PAGE_SIZE;
void *addr_base = mmap(0, virt_mem_size, PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (addr_base == nullptr)
{
error_log("unable to map virtual memory, errno: %d", errno);
return ERR_BADALLOC;
}
// 将栈页改为读写权限,但不向其写入内容
// 调用次数受系统参数限制 /proc/sys/vm/max_map_count
for (size_t offset = C_GUARD_PAGE_SIZE; offset < virt_mem_size; offset = offset + stack_size + C_GUARD_PAGE_SIZE)
{
void *addr = (char *)addr_base + offset;
int ret = mprotect(addr, stack_size, PROT_READ | PROT_WRITE);
if (ret != 0)
{
error_log("unable to map stack, make sure co_num_max is less than /proc/sys/vm/max_map_count, errno: %d", errno);
return ERR_BADALLOC;
}
gs_pool.free_list.push_back(addr);
}
gs_pool.addr_base = addr_base;
gs_pool.stack_size = stack_size;
gs_pool.co_num_max = co_num_max;
infor_log("init co stack, co num max: %d, stack size: %d", co_num_max, stack_size);
return 0;
}
void *co_stack_alloc()
{
if (gs_pool.free_list.empty()) return nullptr;
// 内存分配基于写时拷贝(COW)技术,总是优先分配已经写过的内存,有可能会减少真实物理内存占用
void *addr = gs_pool.free_list.front();
gs_pool.free_list.pop_front();
gs_pool.used_set.insert(addr);
return addr;
}
void co_stack_free(void *addr)
{
assert_retnone(gs_pool.used_set.find(addr) != gs_pool.used_set.end());
gs_pool.used_set.erase(addr);
// 内存分配基于写时拷贝(COW)技术,总是优先分配已经写过的内存,有可能会减少真实物理内存占用
gs_pool.free_list.push_front(addr);
}协程类
#ifndef __CO_H__
#define __CO_H__
#include <ucontext.h>
#include <functional>
enum EN_CO_STATUS
{
E_CO_DEAD = 0,
E_CO_READY = 1,
E_CO_RUNNING = 2,
E_CO_SUSPEND = 3,
};
struct CO;
using CO_FUNC = std::function<void(CO &)>;
struct CO
{
u64 uid = 0;
int status = E_CO_DEAD;
CO_FUNC func;
int yield_value = 0;
ucontext_t main_ctx; //主循环上下文
ucontext_t co_ctx; //协程的上下文
int resume(int value = 0); //切换到协程,用于传递异步操作到来的返回值
int yield(); //切换到主循环
// debug
size_t stack_used() const;
};
CO *co_get_by_uid(u64 uid);
CO *co_alloc(CO_FUNC func);
void co_free(CO *co); // 正常结束不需要调用此逻辑
int co_alloc_and_resume(CO_FUNC func);
#endifyield和resume的实现
入口函数即
#include <limits.h>
#include <signal.h>
#include <unordered_map>
#include "co_stack.h"
#include "co.h"
static std::unordered_map<u64, CO *> gs_uid2co;
static void _co_entry_point(CO *co);
static u64 _co_alloc_uid();
int CO::resume(int value)
{
assert_retval(status == E_CO_READY || status == E_CO_SUSPEND, ERR_CO_INVALID_STATUS);
status = E_CO_RUNNING;
yield_value = value;
int ret = swapcontext(&main_ctx, &co_ctx);
assert_retval(ret == 0, errno);
return 0;
}
int CO::yield()
{
assert_retval(status == E_CO_RUNNING, ERR_CO_INVALID_STATUS);
status = E_CO_SUSPEND;
int ret = swapcontext(&co_ctx, &main_ctx);
assert_retval(ret == 0, errno);
return yield_value;
}
CO *co_get_by_uid(u64 uid)
{
auto it = gs_uid2co.find(uid);
if (it != gs_uid2co.end())
{
return it->second;
}
return nullptr;
}
CO *co_alloc(CO_FUNC func)
{
int ret = 0;
void *stack_addr = nullptr;
CO *co = nullptr;
do
{
stack_addr = co_stack_alloc();
if (stack_addr == nullptr)
{
error_log("alloc co stack failed");
break;
}
co = new CO();
if (co == nullptr)
{
error_log("alloc coroutine failed");
break;
}
co->uid = _co_alloc_uid();
co->status = E_CO_DEAD;
memset(&co->co_ctx, 0x0, sizeof(co->co_ctx));
ret = getcontext(&co->co_ctx);
if (ret != 0)
{
error_log("getcontext failed, errno: %d", errno);
break;
}
co->co_ctx.uc_link = &co->main_ctx;
sigemptyset(&co->co_ctx.uc_sigmask);
co->co_ctx.uc_stack.ss_sp = stack_addr;
co->co_ctx.uc_stack.ss_size = co_stack_size();
makecontext(&co->co_ctx, (void (*)())_co_entry_point, 1, co); //把co当作参数传入
memset(&co->main_ctx, 0x0, sizeof(co->main_ctx));
co->func = func;
co->yield_value = 0;
co->status = E_CO_READY;
gs_uid2co[co->uid] = co;
return co;
} while (0);
if (co != nullptr)
{
delete co;
}
if (stack_addr != nullptr)
{
co_stack_free(stack_addr);
}
return nullptr;
}
void co_free(CO *co)
{
gs_uid2co.erase(co->uid);
co_stack_free(co->co_ctx.uc_stack.ss_sp);
delete co;
}
int co_alloc_and_resume(CO_FUNC func)
{
CO *co = co_alloc(func);
if (co == nullptr) return ERR_SYS_BUSY;
return co->resume();
}
//
// static functions
//
void _co_entry_point(CO *co)
{
co->func(*co);
co->status = E_CO_DEAD;
// 回收协程对象,并回到最后一次resume进来时的状态 main_ctx
co_free(co);
}
u64 _co_alloc_uid()
{
static u32 serial = 0;
return ((u64)time(0) << 33) | ((u64)1 << 32) | (u64)++serial;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号