第五章节:神经网络_周志华《机器学习》
本部分重点是对5.3章节的梳理和公式推导。
1.1神经网络
先简单介绍下神经网络,它是现在用的比较多的,深度学习也是基于此。简单看下最初的M-P神经元。
M-P神经元:神经元收到n个其他神经元传递过来的信号Xi,通过权重Wi连接,超过阈值θ就用f函数激活。
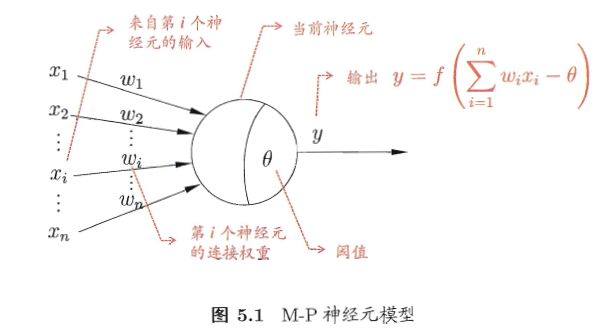
这里的f,是激活函数,可以是Sigmoid函数,也可以是其他函数。分类的话用S型函数,是他的健壮性比较好,也易于求导,故选用他来gank neural network。
1.2感知机
也简单介绍下感知机(Perceptron),他是有两层神经元组成。可以解决简单线性的与或非问题。但关于非线性的问题他就只能哭了。
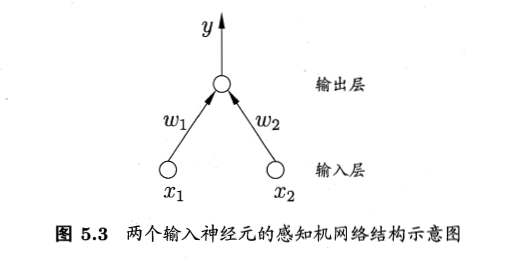
感知机就是比M-P神经元多了一层输入层,第二层还是M-P神经元。
1.3误差逆传播算法(Error BackPropagation)
这里的误差逆传播算法,是指标准BP算法:每次只基于一个样例进行一次参数的调整。还有一个叫累积BP:每次基于整个训练集进行一次参数调整。
1.3.1符号介绍
好了,上面的爸爸解决不了的非线性问题,只能留给大孙子了--------->具有多层的神经网络。他是家族里面的皇长孙。皇长孙的老师就是BP算法,目的很明显,就是把皇长孙给教育好,好继承王位。==好了,开始吧。
BP算法可以训练单层神经网络,也可以是多层神经网络。
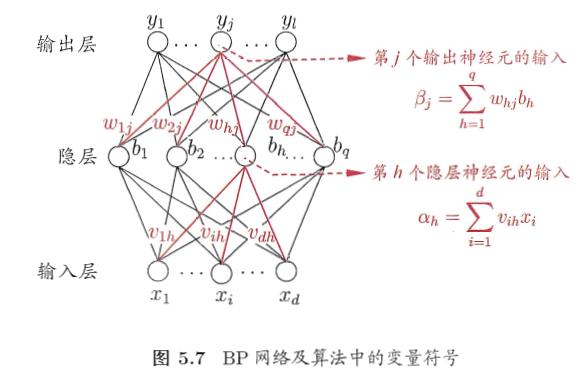
简单说下符号:这里只看有三层的神经网络,第一层是输入层,Xi是各个属性值,中间是一层隐层结点bh,隐层结点和输入层结点每个之间有连接权重Vih,隐层每个结点有一个阈值γh,隐层和输出层之间也有连接权重Whj,输出层每个结点的阈值是θj。
所以有这样的四个关系式:
(1)第h个隐层神经元的输入:
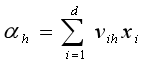
(2)第h个隐层神经元的输出:
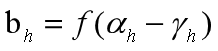
(3)第j个输出神经元的输入:
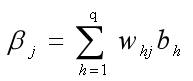
(4)第j个输出神经元的输出:
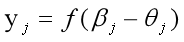
好,一会链式求导会用到这四个式子,其中f是S型函数。
1.3.2优化思路
本BP算法还是考虑要使得输出结果的误差最小,比如分类要和原类标一致,分类错误的越多模型就越不好。那怎么衡量好与不好?于是就有了对误差的考虑:
先考虑一个样本的输入,比如一个西瓜的各个属性值Xi都输进去后,假设得到的输出是Y*,原始类标是Y,那么Y*-Y就是一个预测样本的类标向量的误差Ek,这样的误差有L个,把每个训练例的L个误差加起来最小化不就达到我们优化误差的目的了。这里使用均方误差最小化来优化误差,就是最小二乘法。其实还是误差和,只不过是误差子项的平方和。下面公式中前面1/2是为了求导时消去平方而添加的,不影响我们的优化目标。
所以在第k个训练样例(Xk,Yk)上面的均方误差是:
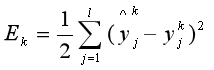
其中输出的预测值y^jk 就是1.3.1中的公式(4)。
而真正的目标是最小化训练集D上的累积误差:
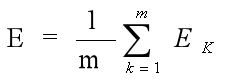
即为公式(5.16),m代表共有m个训练样本,Ek是每一个样本的误差,E是总的积累误差。除以m是归一化。这里的E是代码中用于判别收敛的。
但是下面求偏导用的是Ek,因为是针对每个样本误差逆调整参数的。
1.3.3参数调整
和感知机类似,对原来的参数+误差的大小作为增量(不一定是增加)进行迭代:
V = V + △V
(1)对Whj进行调整
BP算法的△V是基于梯度下降策略给出,下面以Whj为例子。



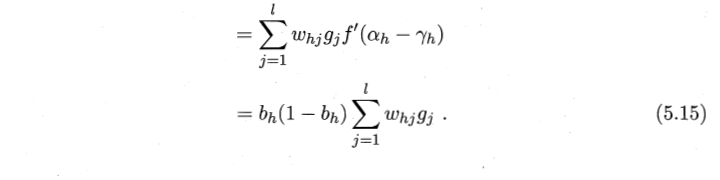
好,开始我不懂为什么图片里面公式(5.7)为什么不用求和,而上面eh里面要求和。
因为Ek和Whj是1对1对应的,不懂?念一下咒语:误差逆传播算法,关键就是这个逆字,链式求导时候,变量之间的关系是:Whj - βj - yjk - Ejk ,就是周志华讲的Whj先影响到第j个βj ,再影响到预测值yjk,最后影响到Ejk,怎么看?看上面1.3.1节里面的4个公式即可,Whj可以影响的是βj,因为Whj=∑Whj*bh,同理βj先影响到预测值yjk,是因为1.3.1里面的第4个公式:yjk=f(βj - θj),Ek同理。
公式(5.7)链式求导的顺序和上面前馈神经网络的变量之间的顺序:Whj - βj - yjk - Ejk 是相反的,是因为BP是把误差 Ek 先逆传播给预测值 yjk ,再由 yjk 逆传播给 βj , βj 最后逆传播给 Whj 。这样不就是误差可以逆向调整参数了嘛,这是公式(5.7)的链式求导部分理解。至于为什么没有求和,是因为误差Ek到Whj都是一一对应的,前后都有j,有木有发现! 就是Ek动一下,Whj也要动一下。
(2)对参数θ的调整
先分析下链路:θj - yjk - Ejk,那么求偏导时候要相反:
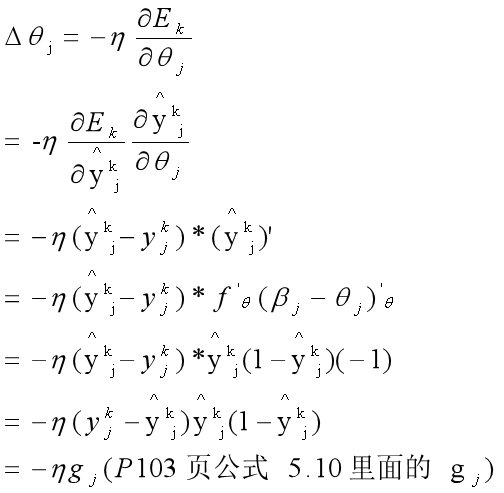
(3)对参数Vih的调整
先分析下链路:Vih - αh - bh - βj - yjk - Ejk ,虽然这里有点长,但可以解释为什么要有求和符号:因为从Vih - αh - bh都是一一对应的,但是到了 bh - βj - yjk - Ejk,有没有发现已经没有纽带了,直接从 h 跨越到了 j ,这里就差了个求和符号∑,为什么是l个,因为前馈是从 bh - βj,误差逆向传播的时候是 βj - bh,从图5.7来看,是l个结点误差汇总到bh,所以要把l个误差都加起来反馈回参数。求导公式如下:
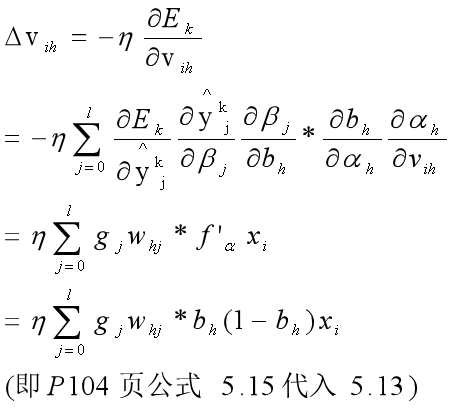
(4)对γh进行调整
先分析链路:γh先影响bh,bh影响βj,βj影响 yjk ,最后影响Ejk:γh - bh - βj - yjk - Ejk,同样 bh - βj 时候,是l个误差汇总到bh,求偏导如下:
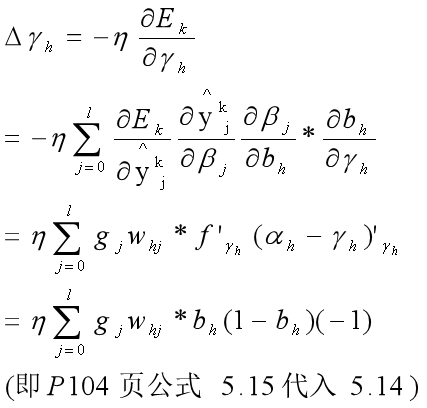
注意:有j的都要放到∑符号里面;第三个等号中gj里面有一个负号,把上一步的负号消了;bh=f(αh-γh),就是f函数,而f是S函数有特性:f'(x) = f(x)*( 1 - f(x) ),即b'h = bh(1-bh);
bh对γh求偏导,就是对γh求复合导数:f ' *(αh-γh)'=bh(1-bh)*(-1)。其中η是学习率,η∈(0,1),相当于调整误差步长的大小。上面几个推导也是类似。
至此:5.3节的大头已经gank掉了,爽!
1.3.4算法伪代码

好了,思考:怎么达到停止条件?因为这个是采用的梯度下降,你可以指定循环轮数就停止,比如循环100000次,反正是机器跑,你怕什么,但是这样遇到大数据量的时候收敛的反而比牛顿法和最小二乘法快,因为他们要求逆矩阵,大的数据量的逆矩阵不好求,这也是梯度下降的一个优点。或者根据误差小于阈值就停止循环比如0.000001,我们就认为它足够小,而符合我们的原始类标。
之前提到的我们计算的是标准BP算法,只基于一个样本来调整误差,还有一种累积BP算法,两者的差别类似于随机梯度下降和批量梯度下降的区别。关于梯度下降有一个很好的博客,推荐参考:
https://www.cnblogs.com/pinard/p/5970503.html
1.4代码参考
先说明这个代码不是我写的,网上的,在哪找的忘了。先贴一个累积BP算法的代码,标准BP的好像有错,我再看看,虽然我贴的和我上面单个样本调整误差的是不同的,但其实差不多,只是一个是整体训练样本矩阵放入计算,一个是每个样本进行迭代。
调用的时候输入2,选择累积BP算法即可。用的是pycharm+python3.5,安装个numpy包就好了。也欢迎有志者修改标准BP。
1 import numpy as np 2 import math 3 4 x = np.mat( '2,3,3,2,1,2,3,3,3,2,1,1,2,1,3,1,2;\ 5 1,1,1,1,1,2,2,2,2,3,3,1,2,2,2,1,1;\ 6 2,3,2,3,2,2,2,2,3,1,1,2,2,3,2,2,3;\ 7 3,3,3,3,3,3,2,3,2,3,1,1,2,2,3,1,2;\ 8 1,1,1,1,1,2,2,2,2,3,3,3,1,1,2,3,2;\ 9 1,1,1,1,1,2,2,1,1,2,1,2,1,1,2,1,1;\ 10 0.697,0.774,0.634,0.668,0.556,0.403,0.481,0.437,0.666,0.243,0.245,0.343,0.639,0.657,0.360,0.593,0.719;\ 11 0.460,0.376,0.264,0.318,0.215,0.237,0.149,0.211,0.091,0.267,0.057,0.099,0.161,0.198,0.370,0.042,0.103\ 12 ').T 13 x = np.array(x) #以数组列表的形式一行一个样本赋值给x 14 y = np.mat('1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0') 15 # print(y) 16 y = np.array(y).T #对应类别标记,竖的一排list 17 ''' 18 x = np.mat( '1,1,2,2;\ 19 1,2,1,2\ 20 ').T 21 x = np.array(x) 22 y=np.mat('0,1,1,0') 23 y = np.array(y).T 24 ''' 25 xrow, xcol = x.shape #x矩阵行列xrow:17,xcol:8 26 yrow, ycol = y.shape #17行1列 27 28 np.random.seed(0) #当我们设置相同的seed,每次生成的随机数相同 29 print('x: \n', x) 30 print ('y: \n', y) 31 32 def sigmoid(x): 33 return 1.0 / (1.0 + np.exp(-x)) 34 35 def printParam(v, w, t0, t1): 36 print ('v:', v) 37 print ('w: ', w) 38 print ('t0: ', t0) 39 print ('t1: ', t1) 40 41 def bpa(x, y, n_hidden_layer, r, error, n_max_train): 42 # print( ) 43 print ('all bp algorithm') 44 print ('------------------------------------') 45 print ('init param') 46 [xrow, xcol] = x.shape 47 [yrow, ycol] = y.shape 48 v = np.random.random((xcol, n_hidden_layer)) #初始化隐层和输入层之间的权重v, 8行5列随机数。5个隐层结点,每个结点是8个不同属性权值和5个阈值的Sigmoid函数输出值。 49 50 w = np.random.random((n_hidden_layer, ycol)) #也是8行5列随机数输出层和隐层的权值 51 52 t0 = np.random.random((1, n_hidden_layer)) #1行5列的随机值,隐层的阈值。 53 54 t1 = np.random.random((1, ycol)) #应该是输出层的阈值 55 56 57 print ('---------- train begins ----------') 58 n_train = 0 59 yo = 0 60 loss = 0 61 while 1: 62 b = sigmoid(x.dot(v) - t0) # bh=f(αh-t0) 63 yo = sigmoid(b.dot(w) - t1) 64 loss = sum((yo - y)**2) / xrow 65 if loss < error or n_train > n_max_train: 66 break 67 n_train += 1 68 # update param 69 g = yo * (1 - yo) * (y - yo) 70 71 w += r * b.T.dot(g) #r 是学习步长 72 t1 -= r * g.sum(axis = 0) 73 e = b * (1 - b) * g * w.T 74 v += r * x.T.dot(e) 75 t0 -= r * e.sum(axis = 0) 76 if n_train % 10000 == 0: 77 print('train count: ', n_train) 78 print (np.hstack((y, yo))) 79 print ('---------- train ends ----------') 80 print ('train count = ', n_train) 81 yo = yo.tolist() 82 print ('---------- learned param: ----------') 83 printParam(v, w, t0, t1) 84 print ('---------- result: ----------') 85 print (np.hstack((y, yo))) 86 print ('loss: ', loss) 87 88 r = 0.1 89 error = 0.001 #误差阈值 90 n_max_train = 1000000 #最大训练量100万。 91 n_hidden_layer = 5 #隐藏层五个结点 92 93 #bpa(x, y, n_hidden_layer, r, error, n_max_train) 94 95 96 def bps(x, y, n_hidden_layer, r, error, n_max_train): 97 98 print ('standard bp algorithm') 99 print ('------------------------------------') 100 print ('init param') 101 [xrow, xcol] = x.shape 102 [yrow, ycol] = y.shape 103 v = np.random.random((xcol, n_hidden_layer)) 104 w = np.random.random((n_hidden_layer, ycol)) 105 t0 = np.random.random((1, n_hidden_layer)) 106 t1 = np.random.random((1, ycol)) 107 print ('---------- train begins ----------') 108 n_train = 0 109 tag = 0 110 yo = 0 111 loss = 0 112 while 1: 113 for k in range(len(x)): 114 b = sigmoid(x.dot(v) - t0) 115 yo = sigmoid(b.dot(w) - t1) 116 loss = sum((yo - y)**2) / xrow 117 if loss < error or n_train > n_max_train: 118 tag = 1 119 break 120 b = b[k] 121 b = b.reshape(1,b.size) 122 n_train += 1 123 g = yo[k] * (1 - yo[k]) * (y[k] - yo[k]) 124 g = g.reshape(1,g.size) 125 w += r * b.T.dot(g) 126 t1 -= r * g 127 e = b * (1 - b) * g * w.T 128 v += r * x[k].reshape(1, x[k].size).T.dot(e) 129 t0 -= r * e 130 if n_train % 10000 == 0: 131 print ("train count: ", n_train) 132 print (np.hstack((y, yo))) 133 134 if tag: 135 break 136 137 print( '---------- train ends ----------') 138 print ('train count = ', n_train) 139 yo = yo.tolist() 140 print ('---------- learned param: ----------') 141 printParam(v, w, t0, t1) 142 print ('---------- result: ----------') 143 print (np.hstack((y, yo))) 144 print ('loss: ', loss) 145 146 n = int(input('标准BP请输入1,累积BP输入2:')) 147 if n == 1: 148 bps(x, y, n_hidden_layer, r, error, n_max_train) 149 elif n == 2: 150 bpa(x, y, n_hidden_layer, r, error, n_max_train) 151 else: 152 print ('命令行参数错误')
1.5总结
其实这章我看了2次了,总是没想通公式5.7没求和,但是公式5.15求和了,今天终于开悟了,故用一天时间整理和记录下来,希望可以给和我一样的初学者一点启发。也通过这个记录发现了自己对最小二乘法还有点不理解,以后再看看。
我是知识分享和开源的爱好者,想转载的可以,在评论里面和我说下就好了,如果有闲钱的大佬,欢迎扫描下面二维码转账,谢谢!
1.6参考
1.周志华《机器学习》
2.梯度下降: https://www.cnblogs.com/pinard/p/5970503.html


