Jmeter之中文乱码问题总结
-
请求消息中文显示乱码
-
产生原因:
这种情况在jmeter3.0的版本中才会产生。这不是乱码,而是由于3.0中优化body data后,使用默认的字体(Consolas)不支持汉字的显示。 - 解决办法:
打开 %JMeter_HOME%\bin\jmeter.properties文件,找到jsyntaxtextarea.font.family这个选项,取消前面的#号,使其使用Hack字体即可,当然,你也可以换成 宋体以及其他支持的字体集。
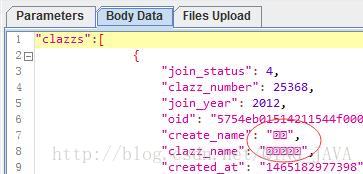

-
响应消息中文显示乱码
-
产生原因:
Jmeter的结果处理编码与被测试对象的编码不一致。Jmeter的sampler请求结果的默认编码方式为:ISO-8859-1(不支持中文),Jmeter的sampler请求结果的默认编码方式为:ISO-8859-1(不支持中文)。 -
解决办法一:
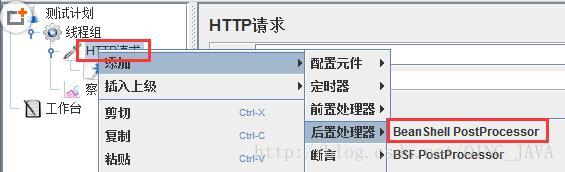
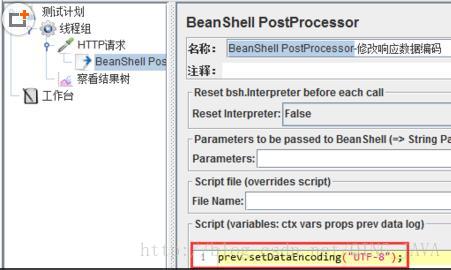
使用后置控制器”BeanShell PostProcessor”来动态修改结果处理编码,使之与被测对象保持一致;
优点:灵活,随时修改;
缺点:要根据不同的对象设置不同的编码;
适用范围:测试不同的公司项目,有些公司喜欢GBK,有些是UTF-8;
配置方法:
1、确定返回结果的编码(可跟开发人员确认,如果是web页面,可查看源文件得知);
2、右键httpSampler,添加“BeanShell PostProcessor”元件;
3、设置“BeanShell PostProcessor”;在“Script”中增加“prev.setDataEncoding(“UTF-8”);”
4、测试验证,OK,设置完毕。 -
解决办法二:
修改Jmeter的默认编码方式;
优点:一次修改,长久使用;
缺点:如果要测试不同的公司项目,需要多次修改,较麻烦;
适用范围:测试本公司的项目,毕竟同一个公司的项目基本上都是使用同一个编码的;
配置方法:
1、打开 %JMeter_HOME%\bin\jmeter.properties文件,搜索“sampleresult”,找到sampler的编码设置代码;修改编码与被测系统同样的编码方式,如UTF-8,去掉“#”(注释符号),保存设置,并重启Jmeter验证即可。
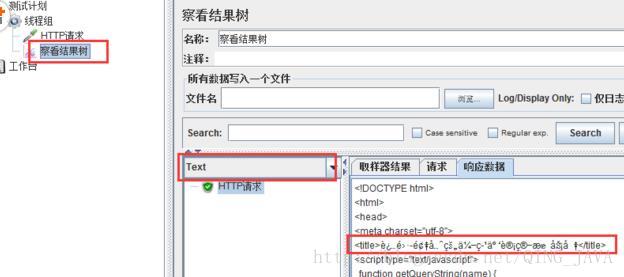
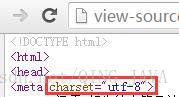

-
被测试系统收到中文乱码
-
产生原因:
发送的请求的编码方式与被测系统的编码方式不一致。 - 解决办法:
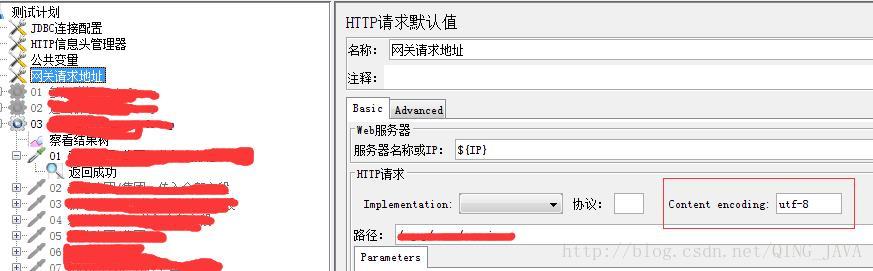
弄清被测系统编码方式,把发送的请求的编码方式设置成与被测系统的编码方式一致即可,如下图红框所示。


温馨提示: 欢迎加入软件测试学习交流QQ群:642466721


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)