
第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 1.学习设计项目的PSP表格;2. 学习使用github对代码进行管理;3. 学习使用性能分析工具,分析代码的性能 |
| github链接 | https://github.com/DerrickRose-1/3122006504 |
一、PSP表格
| PSP2.1 | Personal Software ProcessStages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| Estimate | 估计这个任务需要多少时间 | 15 | 20 |
| Development | 开发 | 160 | 200 |
| Analysis | 需求分析(包括学习新技术) | 60 | 80 |
| Design Spec | 生成设计文档 | 30 | 50 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 15 |
| Design | 具体设计 | 80 | 60 |
| Coding | 具体编码 | 100 | 150 |
| Code Review | 代码复审 | 15 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 45 |
| Reporting | 报告 | 80 | 85 |
| Test Repor | 测试报告 | 60 | 40 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 20 |
| 合计 | 735 | 825 |
二、计算模块接口设计与实现过程
模块接口设计和实现过程分为以下几个关键部分:
-
命令行参数处理模块:负责从命令行中读取输入参数,如文件路径和输出文件位置等信息。
-
文件读取模块:实现读取文本文件的功能,负责将指定文件中的内容加载到内存中进行后续处理。
-
文本预处理模块:对读取到的文本进行处理,包括分词、去除标点符号、换行符、多余空格,以及移除常见的停用词。
-
向量化处理模块:将预处理后的文本转换为词汇列表,然后基于这些列表构建向量表示,供相似度计算使用。
-
相似度计算模块:使用余弦相似度算法对文本的向量表示进行比较,计算两段文本的相似度。
-
结果输出模块:负责将相似度计算结果输出到指定的文件中,方便用户查看结果。
以下是重新设计的函数定义和实现思路:
-
cos_dist(vec1, vec2):
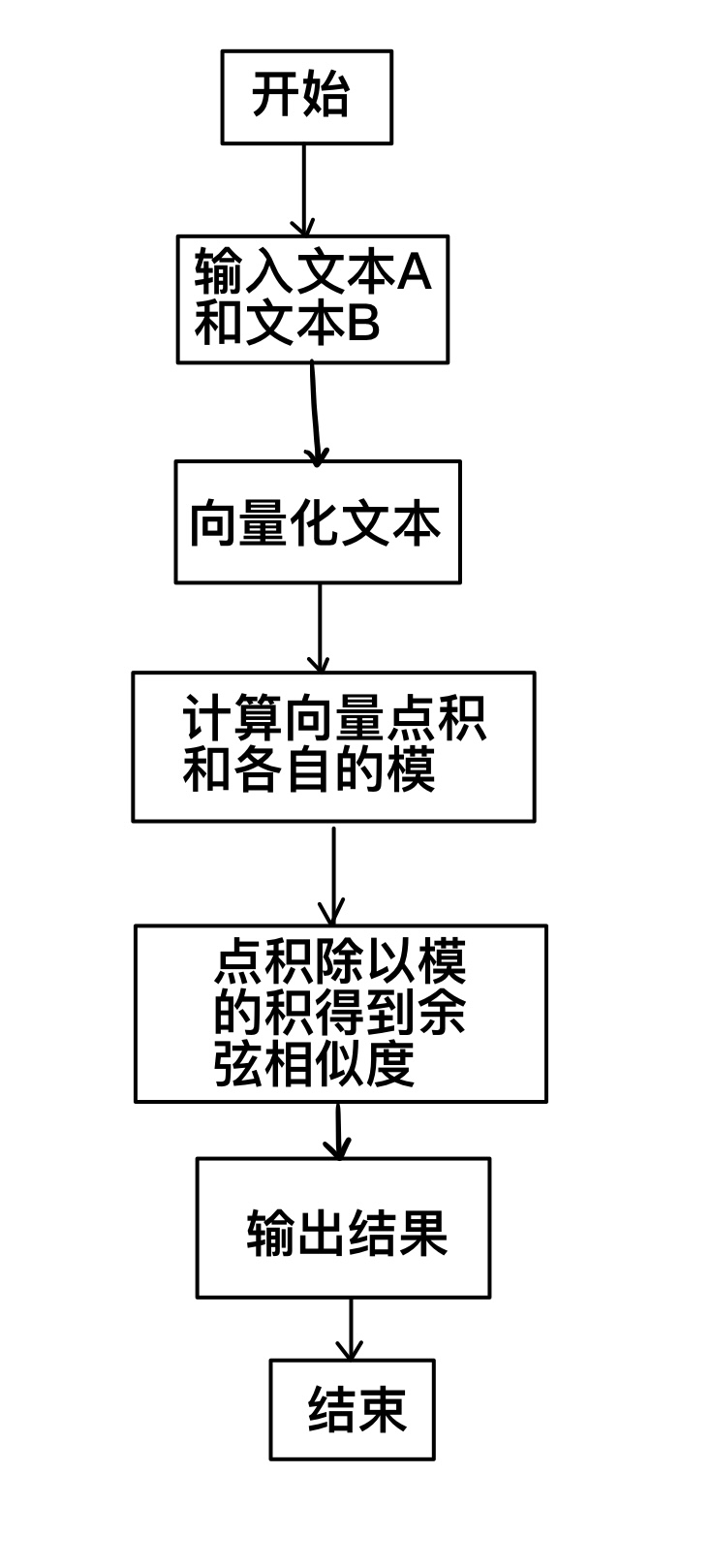
使用余弦相似度算法计算两个向量的相似度,确保分母不为0,计算公式为:
[
\text{cosine_similarity} = \frac{\vec1 \cdot \vec2}{|\vec1| |\vec2|}
]- 实现思路:
- 首先计算两个向量的点积。
- 分别计算两个向量的模(平方和的平方根)。
- 确保分母不为0,如果为0则返回0,否则返回内积除以模的乘积。
- 实现思路:
-
remove_punctuation(text):
去除文本中的所有标点符号并返回处理后的文本。- 实现思路:
- 使用正则表达式或Python的字符串处理方法,将所有标点符号替换为空格或直接删除。
- 返回处理后的文本字符串。
- 实现思路:
-
remove_stopwords(text, stopword_list):
将文本中的停用词去除后返回干净的文本。- 实现思路:
- 将文本切分为单词列表。
- 遍历该列表并去除出现在
stopword_list中的单词。 - 返回处理后的文本。
- 实现思路:
-
stopword_cut(stopword_file):
读取停用词文件,并返回停用词列表。- 实现思路:
- 打开停用词文件,逐行读取停用词。
- 将读取到的词条整理成列表,供其他模块使用。
- 实现思路:
-
read_file(file_path):
读取指定路径的文件内容,处理可能的异常(如文件不存在、无权限等)。- 实现思路:
- 使用
try-except块进行文件读取。 - 如果出现异常,输出相应的错误信息并保证程序不会崩溃。
- 成功读取后返回文件内容。
- 使用
- 实现思路:
-
write_to_text_file(content, output_path):
将内容写入到指定的文件,并处理写入过程中的异常。- 实现思路:
- 使用
try-except块进行文件写入操作。 - 若写入成功,返回成功消息;若发生异常,输出错误信息。
- 使用
- 实现思路:
-
create_vector(file_content1, file_content2):
根据传入的文件内容生成对应的词频向量。- 实现思路:
- 先对两个文件的文本进行分词、去除标点、去除停用词等处理。
- 使用词汇表构建词频向量,确保两个文本使用相同的词汇表。
- 实现思路:
-
put_out(file_path1, file_path2, similarity_score, output_path):
将两个文件的路径和计算出的相似度结果写入到指定的输出文件。- 实现思路:
- 先构建输出字符串,包括文件路径和相似度。
- 使用
write_to_text_file将内容写入到指定路径的文件中。
- 实现思路:
补充:余弦相似度算法
三、性能分析
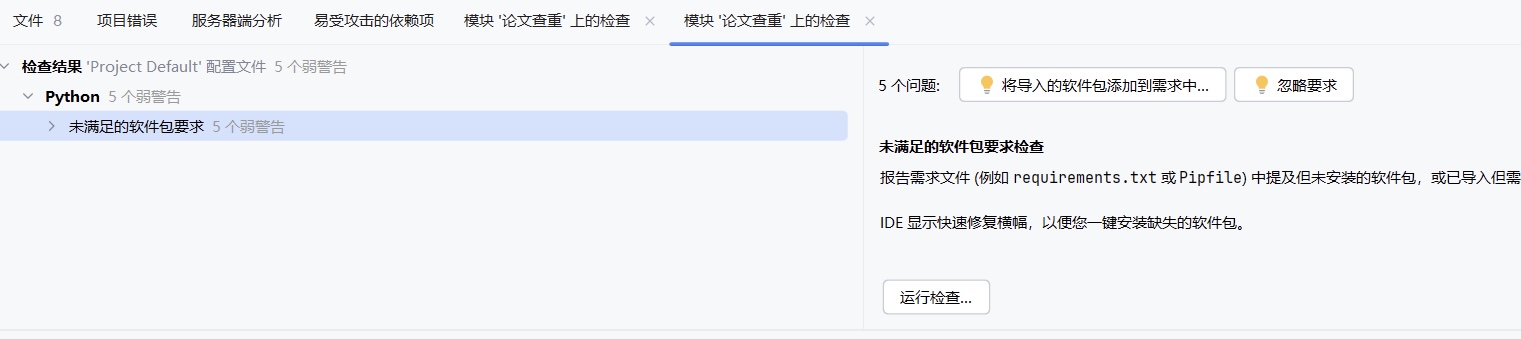
1.消除警告
使用PyCharm的Inspect Code功能可以对代码进行静态分析,帮助检测代码中的语法错误、潜在的逻辑问题以及其他代码质量问题。通过检查代码结果,发现并修复所有警告和错误。
2.性能改进
在pycharm编译器中,利用LineProfiler来检测每一个函数所用的时间,以便改进性能。
改进思路:
1. 减少内存占用:通过使用 Counter 类,我们不需要手动构建词频字典,Counter 会根据提供的分词生成器自动统计频次。
2. 避免重复计算:我们可以提前加载并处理停用词列表,避免在每次处理文本时重新加载文件。通过使用集合(set),停用词查找的效率更高。
3. 高效分词与词频统计:使用 jieba 分词的生成器,并将结果直接传递给 Counter 进行统计,这样可以减少中间变量的存储,进一步优化内存使用。
四、单元测试
unittest 是 Python 标准库自带的单元测试框架,不仅适用于单元测试,还可以用于 Web、Appium、以及接口自动化测试的开发与执行。该框架能够帮助组织和执行测试用例,并提供丰富的断言方法,用来验证测试用例是否通过。它还可以生成详细的测试结果报告,帮助开发者分析代码质量。通过使用单元测试,可以确保代码逻辑正确,并达到较高的测试覆盖率(100%)。
测试函数:
import unittest
from unittest.mock import patch
from 论文查重 import read_file, cos_dist, remove_punctuation
class TestMain(unittest.TestCase):
# 测试读取文件函数
def test_read_file(self):
# 模拟文件内容
file_path = 'test_file.txt'
with open(file_path, 'w', encoding='utf-8') as f:
f.write("测试读取文件函数")
# 测试文件存在的情况
result = read_file(file_path)
self.assertEqual(result, "测试读取文件函数")
# 测试文件不存在的情况
with self.assertRaises(FileNotFoundError):
read_file('non_existent_file.txt')
# 模拟权限错误
with patch("builtins.open", side_effect=PermissionError):
with self.assertRaises(PermissionError):
read_file('permission_error.txt')
# 模拟文件编码错误
with patch("builtins.open", side_effect=UnicodeError):
with self.assertRaises(UnicodeError):
read_file('encoding_error.txt')
# 模拟 I/O 错误
with patch("builtins.open", side_effect=IOError("I/O 错误")):
with self.assertRaises(IOError):
read_file('io_error.txt')
# 测试未知错误
with patch("builtins.open", side_effect=Exception("未知错误")):
with self.assertRaises(Exception):
read_file('unknown_error.txt')
# 测试去除标点符号的函数
def test_remove_punctuation(self):
text = "测试一下!\n这个,函数。"
expected_result = ['测试', '一下', '这个', '函数']
# 调用 remove_punctuation 函数
result = remove_punctuation(text).split()
self.assertEqual(result, expected_result)
# 测试计算余弦相似度函数
def test_cos_dist(self):
# 测试部分相同的文本
text1 = ['调试', '函数', '完成']
text2 = ['测试', '函数', '成功']
expected_similarity = 0.3333
result = cos_dist(text1, text2)
self.assertAlmostEqual(result, expected_similarity, places=4)
# 测试完全不同的文本
text3 = ['不同', '内容']
expected_similarity = 0.0
result = cos_dist(text1, text3)
self.assertAlmostEqual(result, expected_similarity)
# 测试完全相同的文本
text4 = text1
expected_similarity = 1.0
result = cos_dist(text1, text4)
self.assertAlmostEqual(result, expected_similarity)
if name == 'main':
unittest.main(
测试说明&异常:
if name == 'main':
unittest.main()
该代码块用于在脚本作为主程序运行时执行所有测试用例。
测试函数和构造思路:
1. test_read_file() 函数
• 目标函数: read_file()
• 测试目标: 验证文件读取功能,包括各种可能的异常情况。
• 测试思路:
• 成功读取文件: 创建一个测试文件并验证能否正确读取文件内容。
• 文件不存在: 验证当文件路径不存在时,是否会抛出 FileNotFoundError。
• 权限错误: 使用 unittest.mock.patch 模拟权限问题,验证是否抛出 PermissionError。
• 编码错误和I/O错误: 通过 patch 模拟其他异常,验证能否正确处理这些错误。
2. test_remove_punctuation() 函数
• 目标函数: remove_punctuation()
• 测试目标: 验证文本处理功能,确保标点符号被去除。
• 测试思路:
• 去除标点符号: 传入包含标点符号的文本,验证标点符号能否正确去除。
• 构造测试数据: 如 “测试一下!\n这个,函数。” 期望输出为 [‘测试’, ‘一下’, ‘这个’, ‘函数’]。
3. test_cos_dist() 函数
• 目标函数: cos_dist(text1, text2)
• 测试目标: 验证两个文本之间余弦相似度计算是否正确。
• 测试思路:
• 使用两组相似文本,预期余弦相似度应大于 0。
• 使用完全不同的文本,预期余弦相似度应为 0.0。
• 使用完全相同的文本,预期余弦相似度应为 1.0。
构造测试数据:
1. 测试数据:
• 'test_file.txt' 用于模拟文件读取成功。
• 'non_existent_file.txt' 用于模拟文件不存在。
• 通过 unittest.mock.patch 模拟权限错误、I/O 错误和其他未知异常。
2. 余弦相似度测试数据:
• 测试数据 ['调试', '函数', '完成'] 和 ['测试', '函数', '成功'] 用于部分相似文本。
• ['不同', '内容'] 用于测试完全不同文本。
• ['测试', '函数', '运行'] 用于完全相同的文本。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步