hashCode与equals
是什么?
hashcode()是Object类中的一个方法。
public native int hashCode();
可以看到,这是使用native关键字调用底层C++实现的产生随机数的函数。、
有这样一些生成方法:
- 随机数
- 基于内存地址生成
- 固定值:1,用于测试
- 自增
- 利用位移生成随机数
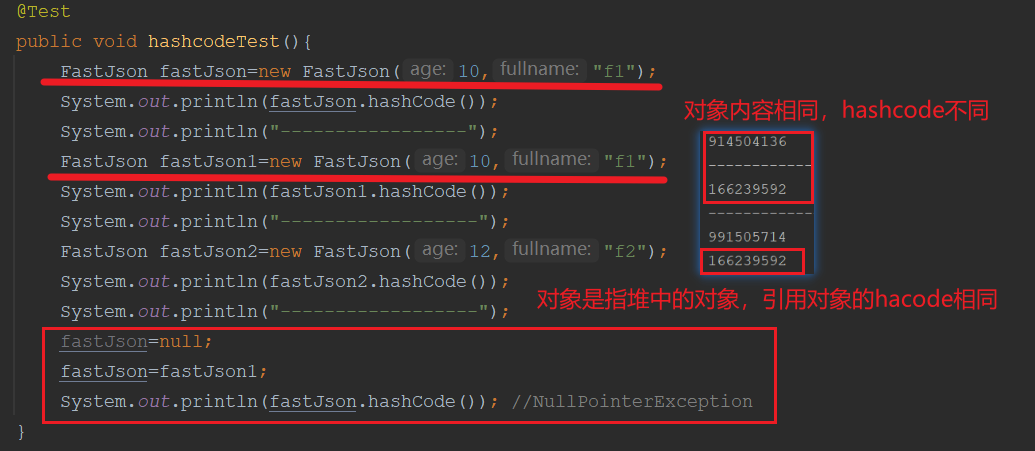
这就带来一个问题,Object中并没有一个值来保存hashcode,那么每次调用hashcode岂不是会变化?但是如下图所示,是不变的。这是因为该信息直接被保存在了对象头的标记字(MarkWord)中
如果进入各种锁状态,那么会缓存在其他地方,一般是获取锁的线程里面存储,恢复无锁(即释放锁)会改回原有的哈希值。
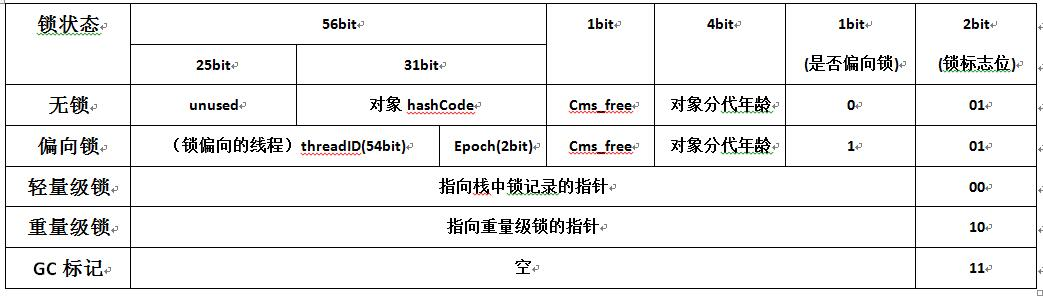
一个Java对象包含如下三个部分:
- 对象头
- 实例信息
- 对齐信息
equal来自于超类Object,默认是==,需要重写。
为什么?
说到这两个,我们都知道,重写。
重写是为了实现我们的目的。我们知道,hashMap存储对象时,是使用到equal和hashcode的。那么一步一步来:
- 为什么不使用
equal或者hashcode
没有重写,和我们使用hashMap的目标不一致。两者都不涉及对象的内容比较。 - 为什么要重写
equal还要重写hashcode,仅重写其中一个不就行了?
首先,这是因为hashMap的策略就是先使用hashcode判别,再使用equal判别。为什么呢?直接equal不就可以了吗?这就涉及到hashMap的原理了。不详细说,简单来说就是一个数组+链表的形式。
那么判断对象存不存在,直接equal就好了。当然可以?当数组中存了一万个对象时,最多equal一万次就能判断出是否已经有该对象了。额,是不是有些问题对吧!既然是数组,那么我们就要利用数组的特性:下标直接访问。因此hashcode就是得到数组下标的关键。为了方便,还是给出一张图:
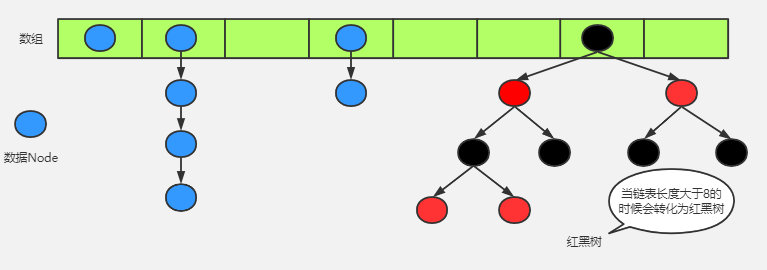
hashMap拿到对象后,先使用hashcode进行一系列换算得到该对象在数组中分配的位置。但是,hashCode一样可能相同。不怕,我们还有equal!使用equal对比该位置上的所有对象,即可判断出hashMap中是否重复该元素。equal数量极大减少了!!!
由此,我们也可以看出hashcode和equal的一些区别: - 不同内容对象,
equal必须不同,但是hashcode可能相同。 - 反之
hashcode相同,equal不一定相同。
怎么用?
重写!!!
equal的重写
简单来说,就是对象内容不同,要保证结果为false。因此在对比时不要漏掉属性即可。
hashcode的重写为了满足上面的规则,也有一番讲究。
hashCode()方法在重写时通常按照以下设计原则实现。
(1)把某个非零常数值37,保存在int型变量result中。这里涉及到jvm的优化。
(2)对于对象中每一个比较值f(equals方法中考虑的每一个属性)参照以下原则处理。
- boolean型,计算(f ? 0:1)。
- byte、char和short型,计算(int)。
- long 型,计算(int)(f^(f>>>32))。
- float 型,计算Float.floatToIntBits(afloat)。
- double型,计算Double.doubleToLongBits(adouble)得到一个long,再执行long型的处理。
- 对象引用,递归调用它的hashCode()方法。
- 数组域,对其中每个元素调用它的hashCode()方法。
(3)将上面计算得到的散列码保存到int型变量c,然后执行result=37×result+c。
(4)返回result。
其他