布隆过滤器-解决缓存穿透
什么是缓存穿透
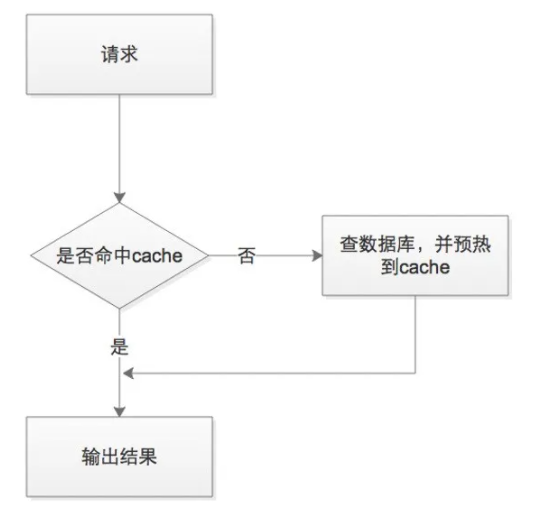
对于Redis的机制,我们这里就不再赘述。简单来说,就是查数据(Redis、数据库)-取数据的过程。
一个场景,购物车一个失效的商品,你可以持续的点击商品详情,然后根据商品ID去查,但是Redis不存在,当然数据库也不存在,于是告诉你商品失效。你不相信,又重新点击了一次商品详情,无意间,你就发起了一次缓存穿透攻击。
又比如典型的秒杀场景。当无数的秒杀并发请求到达数据库,那么要么是Redis加锁,要么是布隆过滤器了。不过布隆过滤器对该类场景有不足,下面再说。
如下图所示,重复的请求和数据库不存在的信息使得这一过程成为了一个死循环。那么数据库就面临非常大压力了。
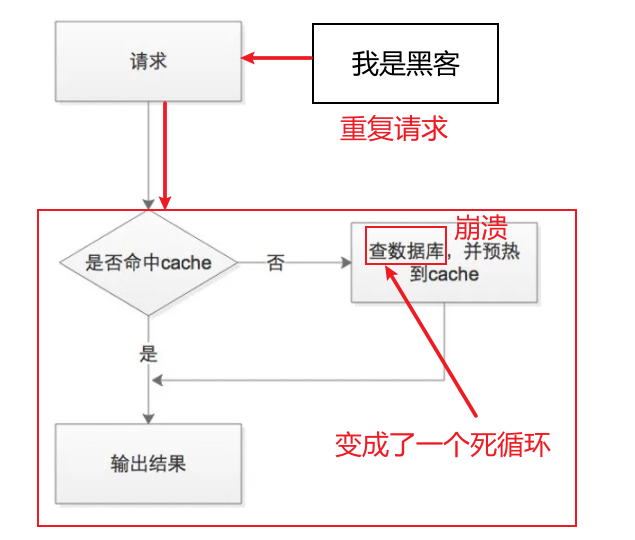
请求直达数据库,就是缓存穿透!
解决缓存穿透。
总体来看,计算机解决问题的思路无非就两个:空间换时间,时间换空间。当然,目前的算法都集中于空间换时间,谁让我们内存过剩呢?
先说其他方法:
- 将不存在的数据也加入到Redis,设置过期时间,攻击无法直达数据库。
这其实也是空间换时间。 - 此外就是布隆过滤器。
我们再搞一个表来,把数据库的ID再存一次,下次数据来了,先到表里查一查再说。
类似于我们去打单位,都要先在门卫查一下访问名单,为什么呢?因为大量人直接到单位大厅去办事,再来查数据,那岂不是大厅挤爆了,客服小姐姐因为忙不过来了!
那么布隆过滤器,就是我们的门卫了。它的手里,也要有一份名单。这个名单,不同于客服小姐姐手里厚厚的一本客户记录,而是一个简单的表,不然门卫大叔也要忙不过来了。
那么这个框架的要求:
- 快速检索
- 内存空间要非常小
什么是布隆过滤器
BloomFilter 是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。
有没有发现,hashMap之类的性能较好的东西,都是使用数组结构作为基础,这也是数组的随即访存所具备的高性能所决定的。
- 优点:空间效率和查询时间都远远超过一般的算法。
- 缺点:有一定的误识别率,删除困难。删除困难其实并不困难,可以通过方案解决。这里所说的删除困难,是指在例如上文提到的秒杀中,如何在高访问量的情况下,保证布隆过滤器和数据库、Redis的缓存一致性,这才是删除困难所在,也就是布隆过滤器不能够及时把删除信息更新。
布隆过滤器构建
布隆过滤器本质上是一个 n 位的二进制数组,用0和1表示。

对于商品ID1,进行三次hash,每次hash得到一个数据中的位置,将该位置的值从0置为1。为什么要进三次甚至k次hash呢?
主要是为了尽可能的将得到hash值打散。显而易见,当大量ID进行hash时,冲突是我们必须要考虑的!因此多次的hash尽可能避免hash值重复。
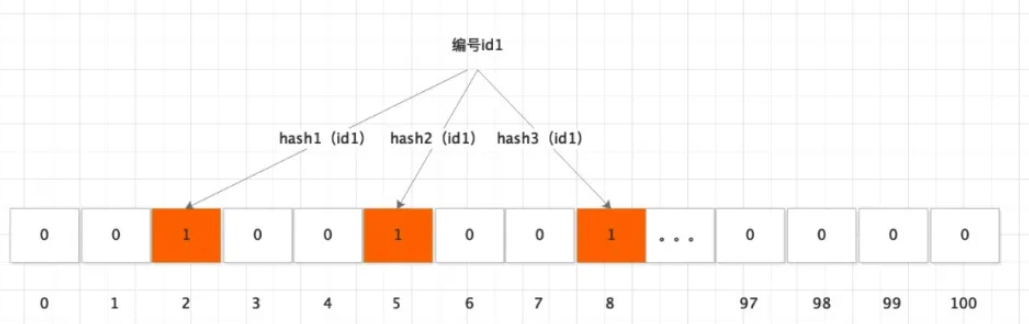
但是,即便如此,明显也无法避免hash重复。简单来说,就是门卫的名单上有一个重名的人出现啦!这个人就会通过布隆过滤器(门卫),直接访问数据库,这就是布隆过滤器的缺点。
布隆过滤器使用
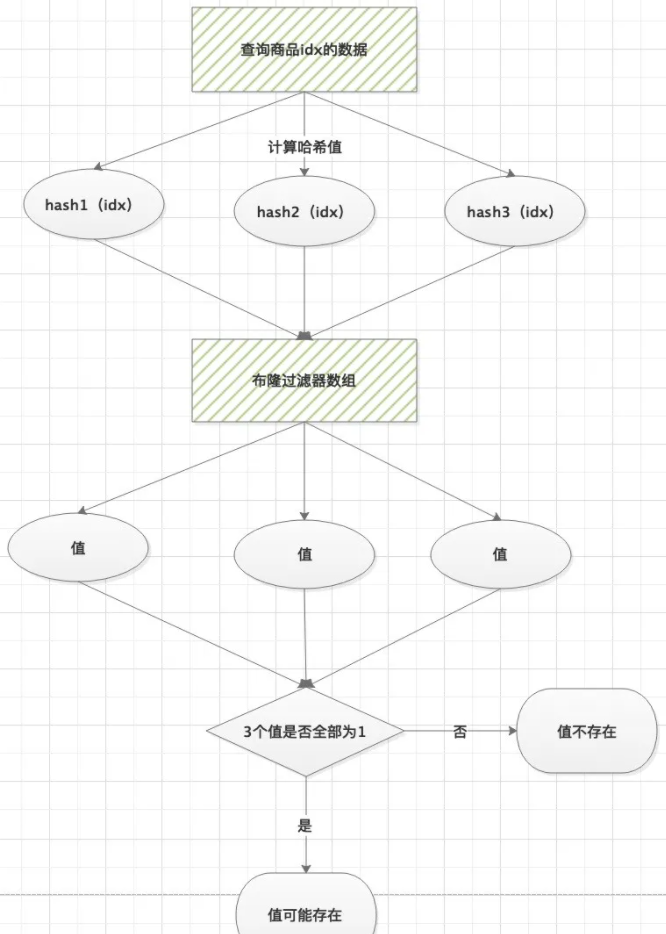
对于要查询的ID,先进行散列,得到一系列数组下标。如果全为1,就存在这一id。
显然,就像门卫处的名单一样,名单(布隆过滤器)上不存在的人,肯定无法进入。但是名单上存在的人,是不是就有他的档案呢?当然不是,因为你可能只是和他重名了,这就是hash冲突!
如何解决hash冲突
- 增加hash次数到k次(可以理解为取去一个长长的名字哈哈)
- 增大布隆过滤器数组(可以理解为使用更大范围的汉字来取名,这样也能减少重复)
使用布隆过滤器
Java 中提供了一个 Redisson 的组件,它内置了布隆过滤器。
首先引入依赖包
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.1</version>
</dependency>
示例代码:
@Test
public void BloomTest() {
Config config = new Config();
config.useSingleServer().setAddress("redis://172.16.67.37:6379");
RedissonClient cient = Redisson.create(config);
RBloomFilter<String> bloomFilter = cient.getBloomFilter("test5-bloom-filter");
// 初始化布隆过滤器,数组长度100W,误判率 1%
bloomFilter.tryInit(1000000L, 0.01);
// 添加数据
bloomFilter.add("ID1");
// 判断是否存在
System.out.println(bloomFilter.contains("ID2"));
System.out.println(bloomFilter.contains("ID1"));
}
运行结果:
false // 肯定不存在
true // 可能存在,有1%的误判率
注意:误判率设置过小,会产生更多次的 Hash 操作,降低系统的性能。通常建议值是 1%
布隆过滤器二进制数组,如何处理删除?
如果原始数据删除了怎么办?布隆过滤器二进制数组如何维护?
直接将对应的hash位置0就行了
才怪
由于hash冲突,
- 只能是重新载入布隆过滤器了。开发定时任务,每隔几个小时,自动创建一个新的布隆过滤器数组替换老的。注意,是几小时,这也就意味着,这一方法在高并发的情况下有巨大缺点。
- 或者,直接记录hash冲突次数。布隆过滤器增加一个等长的数组,存储计数器,主要解决冲突问题,每次删除时对应的计数器减一,如果结果为0,更新主数组的二进制值为0
明显,不论哪种方案,都决定了布隆过滤器大多数情况只能应用在缓存数据更新较慢的情况下。
