Mirror Descent
文章整理了Mirror Descent相关的概念、基本定理,主要参考资料为[1]。
Mirror Descent
Mirror Descent可以看做Proximal的推广,其迭代流程如下
如果\(\nabla f(x^t)\)不存在的话可以用次梯度\(\partial f(x^{t})=\bold{g}\),如果对于proximal gradient descent不熟悉,可以查看部分[6](也可以看一下我之前的博文优化整理)。
式子中\(D_\varphi(x,x^t)\)表示的是一种距离度量,称为Bregman divergence。相对于Proximal中的近端算子,Mirror Descent中也会用到投影的方法,Bregman Projection。我们希望我们选择的距离度量具有以下三个特点
- 拟合\(f\)函数的局部曲率
- 在几何上与约束集合\(\mathcal{C}\)想匹配
- Bregman projection操作尽量简单
Bregman Divergence
要先说清楚Mirror Descent就先得说清楚bregman divergence,Bregman divergence是一种广义的距离度量,定义如下
对于一个在定义域\(\mathcal{C}\)上强凸且可微的函数\(\varphi\),定义Bregman divergence如下
\[D_{\varphi}(x,y)=\varphi(x)-\varphi(y)-\nabla\varphi(y)^T(x-y) \]
Bregman divergence的详细含义和图示化的理解可以参看[2],简单来说,其表示的是\(x\)点\(f\)函数上在其\(y\)切线上插值,如图中蓝色的线段
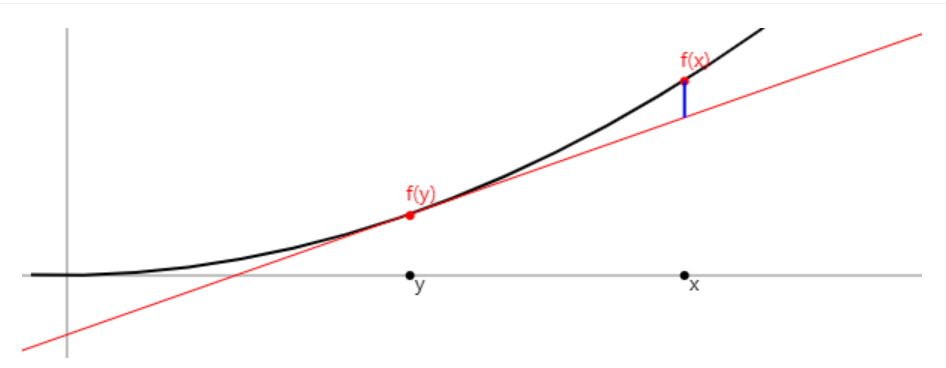
关于为什么说Bregman divergence是一种广义的度量以及详细的例子,可以参看[5]

Bregman divergence有如下几条简单的性质
- \(D_\varphi(x,y)\geq 0\),根据\(\varphi\)的强凸性
- \(D_\varphi(x,y)\)对于\(x\)来说也是凸函数
- \(D_\varphi(x,y)\neq D_\varphi(y,x)\)
- \(D_{\varphi_1+\lambda\varphi_2}(x,y)=D_{\varphi_1}(x,y)+\lambda D_{\varphi_2}(x,y)\)
- \(\nabla_xD_\varphi(x,y)=\nabla\varphi(x)-\nabla\varphi(y)\)
- 如果\(\varphi\)是\(\lambda\)-strongly convex,那么\(D_{\varphi}(x, y)\geq \frac{\lambda}{2}\Vert x-y\Vert^2\)
Three-point lemma
对于\(x,y,z\in \mathcal C\),有下式成立
\[D_\varphi(x,z)=D_\varphi(x,y)+D_\varphi(y,z)-\langle\nabla \varphi(z)-\nabla\varphi(y), x-y\rangle \]
这个定理证明将Bregman Divergence展开就可以得到,详细过程[1]
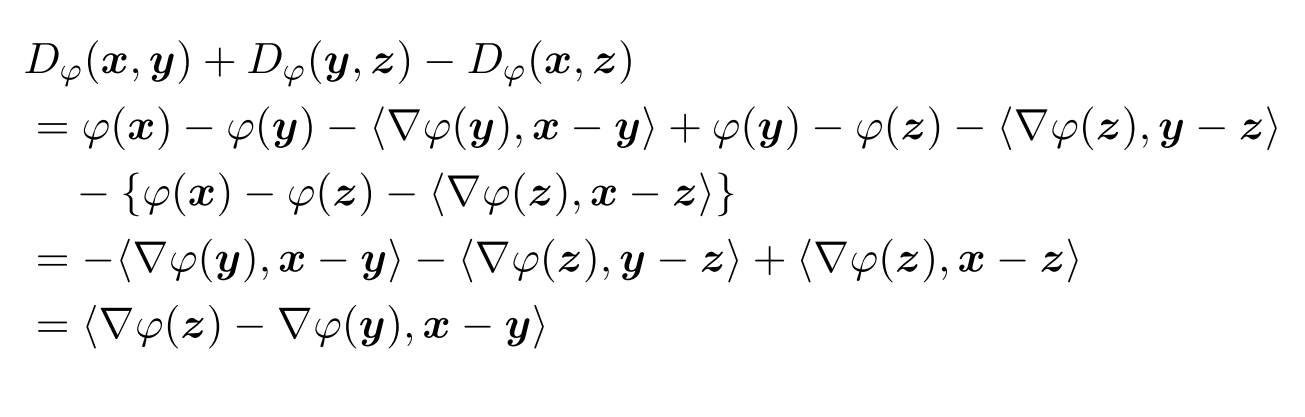
Bregman Projection
Bregman Projection的定义如下
给定点\(x\),其在约束集合\(\mathcal{C}\)上的Bregman projection为
\[\mathcal{P}_{\mathcal{C},\varphi}(x)=\arg\min_{z\in\mathcal{C}}D_\varphi(z,x) \]
Generalized Pythagorean Theorem
令\(x_{\mathcal{C},\varphi}=\mathcal{P}_{\mathcal{C},\varphi}(x)\),则
\[D_\varphi(z,x)\geq D_\varphi(z,x_{\mathcal{C},\varphi})+D_\varphi(x_{\mathcal{C},\varphi},x) \]
上面的定理说的就是在bregman divergence上定义的勾股定理,证明需要用到\(x_{\mathcal{C},\varphi}\)的性质,即
再利用凸函数的性质,可以得到
再利用上面的Three-point lemma,即可得到上面的广义勾股定理,详细证明过程可以参看[1]。
Alternative form of Mirror Descent
回到最开始的mirror descent更新公式,
现在我们\(\langle \mathbf g^t, x-x^t\rangle+\frac{1}{\eta_t}D_{\varphi}(x,x^t)=0\),可以得到:
因为这是我们没用在约束集\(\mathcal C\)上进行投影,就先用\(y^{t+1}\)来表示未投影的\(x^{t+1}\)。\(y^{t+1}\)可以看作为未进行bregman projection之前的解,那么
第一个式子可以通过,假设我们没有假设\(\mathcal{C}\)的假设,求原始问题的极小值,令其导数为\(\bold{0}\)得到。第二个式子是我们实际上是由约束的,所以我们要进行一步bregman projection。
上述方法求解原始问题的证明如下(\(\textit{5.3a那一行少了一个}\nabla\)):

进一步的,如果\(\mathcal{C}=R^n\),可以都得到
即\(\nabla^*\varphi=(\nabla \varphi)^{-1}\),\(\varphi^*\)表示共轭。
证明需要一些次梯度的理论,可以参看[3]的前几页内容。
详细证明过程推荐看原资料[1],\(x^{t+1}=(\nabla \varphi)^{-1}(\nabla\varphi(x^{t})-\eta \bold{g}^t)\)只需要对\(\arg\min_{z\in\mathcal{C}}D_\varphi(z, y^{t+1})\)对\(z\)求导即可。
Convergence Analysis
凸且连续的问题
对于\(f\)是凸且Lipschitz连续的函数,次梯度对偶范数满足\(\Vert g\Vert_*\leq L_f\),如果\(\varphi\)对于特定的范数空间是\(\rho\)强凸函数,则有
如果\(\eta_t=\frac{\sqrt{2\rho R}}{L_f}\frac{1}{\sqrt{t}}\),其中\(R:=\sup_{x\in\mathcal{C}}D_\varphi(x, x^0)\),则
在上面的式子中,除去\(f\)本身的\(L_f\)和\(\rho\)以外,它的upper bound只跟如何选择\(\varphi\),即度量\(D_\varphi\)有关。在[1]中,也拿一个distribution的simplex例子对比了bregman divergence作为欧氏距离和KL divergence时收敛上届的差别。
在看收敛速度,虽然这里写的是\(\frac{\log t}{\sqrt t}\)但是如果假定\(\eta_t\)是恒定恒定的话,结果应该是\(\mathcal{O}(\frac{1}{\sqrt{t}})\)的收敛速度
要证明上面的收敛性,需要先证明下面式子
现在只需要证明\(D_\varphi(x^t,y^{t+1})-D_\varphi(x^{t+1},y^{t+1})\leq\frac{\eta_t^2L_f^2}{2\rho}\)即可
现在我们有\(D_\varphi(x^*, x^{t})\)和\(D_\varphi(x^*,x^{t+1})\)的递推关系,只需要累加起来就可以得到最开始的证明了。
除了上述的证明外,还可以参考一下[7],在阅读之前请先阅读Fenchel dual内容
这里,将\(\theta^t=\nabla \varphi(x^t)\)表示对偶空间的向量,那么
\[\begin{align*} D_{\varphi^*}(\theta^{t+1},\theta^*)&=D_{\varphi^*}(\theta^{t+1}, \theta^t)+D_{\varphi^*}(\theta^t,\theta^*)+\langle \nabla\varphi^*(\theta^t)-\nabla\varphi^*(\theta^*), \theta^{t+1}-\theta^t\rangle\\ &=D_{\varphi^*}(\theta^{t+1}, \theta^t)+D_{\varphi^*}(\theta^t,\theta^*)-\langle x^t-x^*, \eta_t {\mathbf g}^t\rangle\\ & \leq =D_{\varphi^*}(\theta^{t+1}, \theta^t)+D_{\varphi^*}(\theta^t,\theta^*)+\eta_t(f(x^*)-f(x^t)) \end{align*} \]
Gradient Descent & Fenchel dual
要讲清楚Gradient Descent和Mirror Descent区别到底在哪里,首先要讲一讲Fenchel dual。
首先\(f\)的共轭函数(即Fenchel dual),\(f^*\)定义如下
接下来我们讲一讲这个共轭函数的性质
- \(f^{**}=f\), 当\(f\)是凸且闭的函数
- \(\langle y, x\rangle\leq f^{*}(y)+f(x)\)
- 当\(f\)是convex and closed,\(x\in \partial f^{*}(y) \Leftrightarrow y\in \partial f(x)\Leftrightarrow \langle x,y \rangle=f(x)+f^*(y)\)
我们可以看到,\(f(x)\)的导数(次梯度)是其对偶空间的一个向量,在进行梯度下降时,我们实际上是将两个空间的向量进行运算[8]。这里强烈建议阅读一下原文,在P7。因此实际上,Mirror Descent做的就是将在对偶空间的梯度再次通过\(\nabla f^{*}\)这样的操作,映射会原本的参数空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号