三种联邦学习的个性化方法及应用
这篇文章与那些优化证明收敛的文章不同点在于,它是从泛化性来进行算法收敛说明的,我觉得它更像是一个框架而不是怎么具体进行优化的方法。
preliminary
文章在开头就对比了传统的global model和纯粹在自己数据集上训练得到的local model的差异,从而引出了personalization是介于两者之间的一个东西,personalization希望得到global model的泛化性以及local model在本地数据集上的良好表现。
global model实际上是对\(\sum\limits_k \lambda_k \hat{\mathcal{D}}_k\)进行优化的,其度量了当函数\(h\)在全局和本地数据情况下,对本地数据损失的差异,
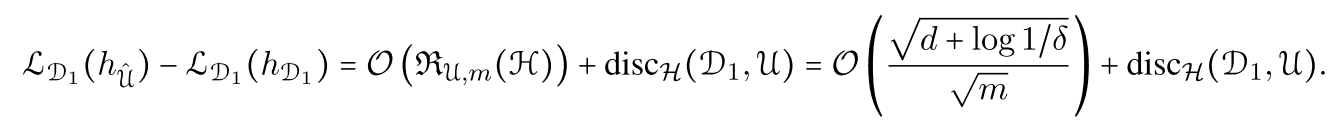
可以看到全局数据数量越大,损失差异就越小,本地数据和全局数据分布差异越大,损失差异就越大。也就是说,像传统联邦学习那样,用全局数据训练得到的模型可能对数据分布与\(\sum\limits_k \lambda_k \hat{\mathcal{D}}_k\)差异较大的客户的效果不好。
本文提出了三种personalization的方法,分别是user clustering,data interpolation,model interpolation。
user clustering
就跟我们传统的聚类算法假设一样,我们认为所有用户是可以被分为几个类别的,通过对各个类别分别建模从而提高模型表现。

作者提出的算法流程也非常的朴素,现在假设有\(q\)个模型,客户在那个模型上的损失最小那他就属于这个类别,然后对所属这一类的用户进行梯度下降。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号