基于视觉-语义中间综合属性特征的图像中文描述生成算法论文笔记
1.摘要
该文提出了基于多层次选择性视觉语义属性特征的图像中文描述生成算法。该算法结合目标检测和注意力机制,充分考虑了图像高层视觉语义所对应的中文属性信息,抽取不同尺度和层次的属性上下文表示。
2.当前研究任务的不足及解决方法
首先,现有研究大多针对图像的英文描述。相比英文,中文在语法结构、词义表述等方面更为丰富。因此,在实现图像中文描述的算法学习过程中,模型不仅需要对中文语料进行必要的分词、词嵌入表示等预处理,还需要考虑词语的多义性。
其次,现有图像语句描述的算法并没有并重考虑视觉和语言两方面的信息。多数算法对发展较为成熟的语言模型更为倚重,对图像的视觉信息,尤其是图像内容的分布信息,处理方式简单粗暴,信息利用不充分。
本文充分考虑图像高层视觉语义对应的中文属性信息,结合目标检测算法,提出多层次多尺度的中间属性特征抽取模块,获取图像的视觉语义要素,克服存在的异构语义鸿沟问题;使用选择性注意力机制,将语义属性要素进行加权综合,将不同尺度和层次的属性上下文信息应用到图像的描述生成过程中。
本文的创新点主要体现在两方面:①本文根据中文语言特点,利用中文分词筛选出具有明确意义的中层属性语义词,并以此作为图像内容的中间语义特征,增强视觉和语言之间的信息关联度;②本文利用多层次中间语义属性特征,提出基于显著目标候选区域选择性注意机制的图像中文描述生成算法。
3.1模型框架
模型采用图像的中间语义特征提取和描述语句的生成两阶段过程。其中,特征提取阶段又包含了两部分的网络:图像全局视觉特征检测器和图像高层中间语义属性特征检测器。
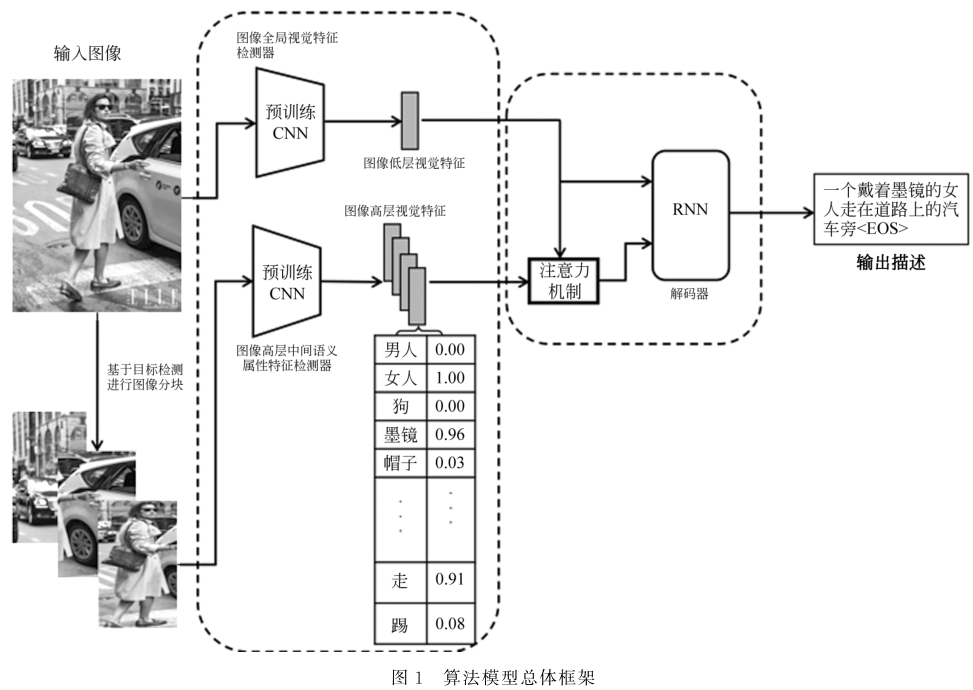
3.2图像全局视觉特征抽取网络
图像全局视觉特征抽取网络使用预训练好的卷积神经网络作为图像低层视觉特征提取器。在本文去除预训练的 ResNet50的最后全连接层后,网络输出的2048维向量被用作图像全局视觉特征。该特征虽然带有一定高度的内容抽象,但依然缺乏显式的语义对应关系,是对图像低层视觉特征的概括。
3.3图像高层中间语义属性特征抽取网络
图像高层中间语义属性特征抽取网络包含两个处理阶段。首先,构建视觉内容的关键属性词表,用于表征中间语义信息。其次,为了有效地实现属性词表中所表示的中间语义属性与视觉特征的关联,训练属性分类器,用于预测中间语义的概率。
4.实验细节
算法模型采用 PyTorch1.0版本实现。描述语句生成网络采用单层 LSTM结构,其中,循环单元的隐层状态数设置为 512。算法使用开源工具jieba-0.38进行中文分词。词嵌入特征向量的维度设置为512。网络模型训练的优化器设置为 Adam算法,训练批量大小(batchsize)设置为8,训练学习率初始化为0.001。为了保持模型结构的一致,Flick8k-CN数据集和 AIChallenger2017数据集对应的属性词表大小均设置为2048。具体地,在 AIChallenger2017数据集中,提取的属性词词频在 50以上。由于Flick8k-CN数据集[10]相对比较小,所提取的属性词词频设置为在2以上。由于我们提取的这些属性词的词性和意义均比较丰富,因此词频不影响属性词汇表的语义表达有效性。
5.实验不足
列举出了一些本文模型表述错误的例子。在这些样例中,基准模型的结果也同样是完全错误。与大部分的数据驱动方法一样,当图像出现的视觉要素(物品、行为等)在训练集中较少出现时,模型极易发生表述错误。

