
Meta Learning for Image Captioning论文笔记
1、解决问题
使用强化学习训练模型,可能会使模型与奖励函数过拟合,造成奖励黑客行为(reward hacking),也就是说虽然奖励函数的得分提高了但是模型的实际性能是降低的,这是因为奖励函数不能非常正确的表达出生成描述的质量,一些错误的表示可能反而有很高的奖励,尤其是对描述的命题内容和独特性的奖励。比如,使用CIDEr优化倾向于让句子以“介词+a”结尾,因为CIDEr评价指标会惩罚太短的句子并给常见的短语小的权重,因此,当模型生成短描述时RL会添加一些小权重但是常见的短语来避免惩罚。SPICE指标认为不正常结尾是不匹配的对象-关系对,会惩罚这种现象,但是,SPICE有自己的奖励黑客问题,因为它不惩罚场景图中的重复元组。从技术上讲,很难设计一个完美的评价指标,能够考虑到预期目标的每一个方面。
2、方法
这篇论文使用元学习(meta learning)的方法,利用来自ground truth的监督信息,在优化评价指标的同时确保生成描述的命题正确性和独特性。具体来说,作者将MLE优化和RL优化看做两个任务,建立一个元模型同时适应这两个任务,找到这两个任务的最优解。如下图所示,如果直接将这两个任务的损失加起来(棕色箭头,表示为MLE+RL),梯度方向在它俩之间,这并不能保证是任何一个任务的最优解,但是使用元学习(绿色箭头)能够使学到的模型参数同时适应两个任务。
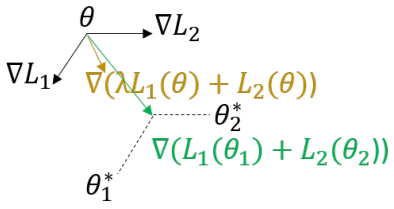
在实验时,模型先进行MLE预训练,然后在使用元学习对MLE和RL两个任务进行微调。注意作者对MLE进行了改进,即最大化正对(配对的ground truth)的概率同时最小化负对(不配对的ground truth)的概率,对于RL作者采用了CIDEr+SPICE作为奖励函数。
