深度学习_1_神经网络_4_分布式Tensorflow
分布式Tensorflow
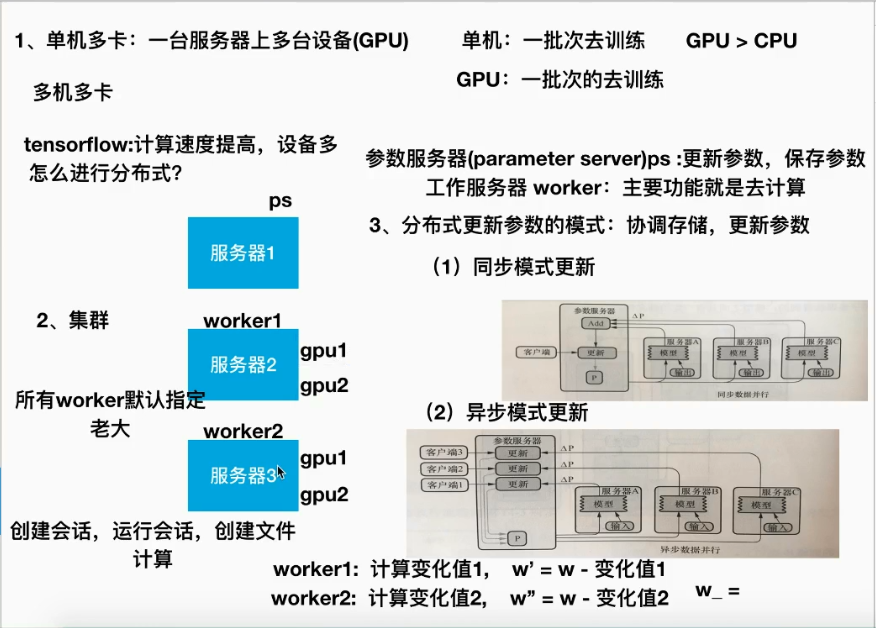
单机多卡(gpu)
多级多卡(分布式)
自实现分布式

API:
1,创建一个tf.train.ClusterSpec,用于对集群的所有任务进行描述,该描述对于所有任务相同
2,tf.train.Server 创建ps,worker 并运行相应的计算任务
-
cluster=tf.train.ClusterSpec({"ps":ps_spec,"worker":worker_spec})
ps_spec = ["ps0.example.com:port","ps2.example.com:port"] 对应 /job:ps/task:0,1
worker_spec=["worker0.example.com:port",...] /job:worker/task:10
-
tf.train.Server(server_orcluster,job_name,task_index=None,protocol_None,config=None,start=True) 创建服务
- server_or_cluster:集群描述
- job_name:任务类型名称
- task_index:任务数
- attributes:target 返回tfSession连接到此服务器的目标
- method:join() 参数服务器,直到服务器等待接收参数任务关闭
-
tf.device(device_name_or_function)
- 选择指定设备或者设备函数
- if device_name
- 指定设备
- 例如 “/job:worker/tsak:0/cpu:0
- if function
- tf.train.replica_device_setter(worker_device=worker_device,cluster=cluster)
- 作用:通过此函数协调不同设备上的初始化操作
- worker_device:为指定设备,“job/worker/task:0/cpu:0" or "/job:worker/task:0/gpu:0"
- cluster:集群描述对象
- 使用with tf.device() 使不同工作节点在不同设备上


本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,如有问题, 可评论咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号