深度学习_1_神经网络_2_深度神经网络
深度神经网络------>卷积神经网络
1,卷积神经网络与简单神经网络的比较
全连接网络的缺点:
- 参数太多,图片过大时,计算太多
- 没有利用像素之间位置信息
- 层数限制
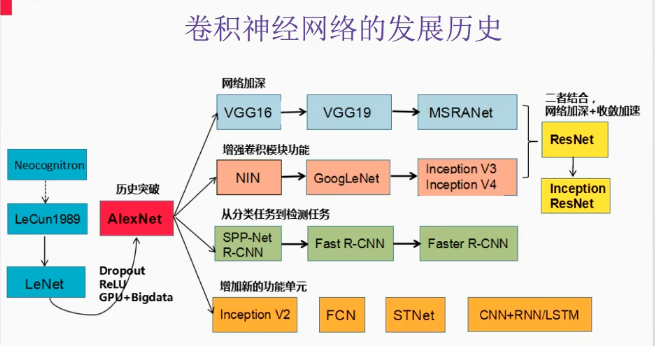
2,卷积神经网络发展史
3,卷积神经网络结构

-
神经网络:输入层,隐藏层,输出层
-
卷积神经网络:隐藏层分为
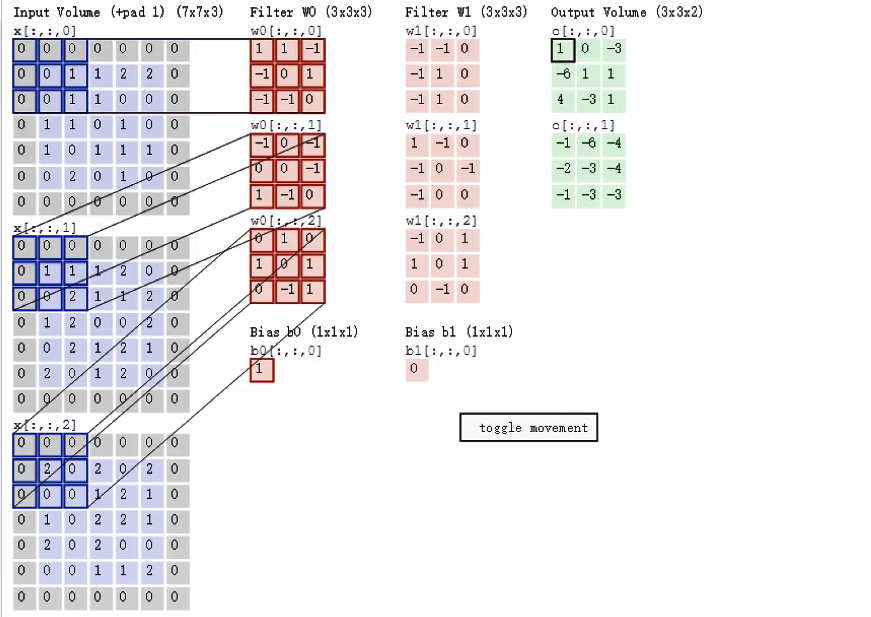
卷积层过滤器:通过在原始图像上平移来提取特征,定义过滤器观察窗口(大小,步长)单位为像素
移动越过图片大小,例如步长过长,会导致最后一次越界,或不足(使用填充 0填充解决)
1,不越过,直接停止观察 (valid 取样面积小于总面积)
2,直接越过(same 取样面积和输入像素一致)
计算输入层----》卷积层输出后大小
Filter数量K,大小F,步长S,零填充大小P(填充的0的层数,Tensor是根据大小,步长求得的)
输入体积H*W*D 输出体积H1*W1*D1
H1=(H-F+2P)/S+1
W1=(W-F+2P)/S+1
D1=K
激活函数:增加网络的非线性分割的能力
sigmod f(x)=1/(1+e^(-x)) 计算量大,反向传播时 容易出现梯度爆炸
relu f(x)=max(0,x) 常用
数据经过多个filter后会变多
池化层:通过特征后稀疏参数来减少学习的参数,降低网络的复杂性。(最大池化和平均池化)

全连接层:前面的卷积和池化相当于特征工程,后面的全连接相当于特征加权,“全连接层”起到了分类器的作用

4,卷技网络API
tf.nn.conv2d(input,filter,strides,padding,name)
- input:出入的张量[batch,height,weight,channel] float32,64
- filter:指定过滤器[filter_height,filter_weight,图片通道数,filter 个数]
- padding:same(填充,变化后height,width不变),valid(超出部分舍弃)
tf.nn.relu(features,name) 激活函数
features:卷积后加上偏执的结果
tf.nn.max_pool(value,ksize,strides,padding,name)
value:4DTensor形状的【batch,height,weight,channels】
ksize:池化窗口大小 [1,ksize,ksize,1]
strides:步长大小 [1,strides,strides,1]
padding:
5,手写数字识别
图片比较大,类别多的时候使用定义过的网络例如googlenet
简单图片,自定义网络
一层卷积:
卷积:32个filter,5*5 1 SAME bias = 32 输入:【None,28,28,1】输出:【None,28,28,32】
激活:【None,28,28,32】
池化:2*2 strides=2 SAME bias = 64 输入:【None,28,28,1】输出:【None,14,14,32】
二层卷积:
卷积:64个filter,5*5 1 SAME 输入:【None,14,14,32】输出:【None,14,14,64】(64个过滤器 ,每层都是32个14*14相加)
激活:输出:【None,14,14,64】
池化:2*2 strides=2 SAM E 输入:【None,14,14,64】输出:【None,7,7,64】
全连接层FC
【None,7,7,64】---》【None,7*7*64】*【7*7*64,10】 -------------》【None,10】
# 定义一个权重初始化函数
def weight_variables(shape):
weight = tf.Variable(tf.random_normal(mean=0.0, stddev=1.0, shape=shape), name="w")
return weight
# 定义一个权重初始化函数
def bias_Variables(shape):
bias = tf.Variable(tf.constant(0.0, shape=shape), name="b")
return bias
# 自定义卷积模型
def model():
# 1,准备占位符x [None,784] y_true[None,10]
with tf.variable_scope("data"):
x = tf.placeholder(tf.float32, [None, 784])
y_true = tf.placeholder(tf.int32, [None, 10])
# 2,一层卷积 卷积5*5*1 32 strides=1, 激活 tf.nn.relu 池化
with tf.variable_scope("conv1"):
# 随机初始化权重
weight_conv1 = weight_variables([5, 5, 1, 32]) # 32个过滤器, 1表示图片通道数
# 随机偏置
bias_conv1 = bias_Variables([32])
# 对x进行形状的改变【None,784】 ----》 【None,28,28,1】
x_reshape = tf.reshape(x, [-1, 28, 28, 1])
# [None,28,28,1] ----->[None,28,28,32]
x_relu1 = tf.nn.relu(tf.nn.conv2d(x_reshape, weight_conv1, strides=[1, 1, 1, 1], padding="SAME") + bias_conv1)
# 池化 2*2 strides2 [None,28,28,32] ----> [None,14,14,32]
x_pool1 = tf.nn.max_pool(x_relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
with tf.variable_scope("conv2"):
# 3,二层卷积 卷积5*5*32 64 strides=1, 激活 tf.nn.relu 池化
# 初始化权重
weight_conv2 = weight_variables([5, 5, 32, 64])
bias_conv2 = bias_Variables([64])
# 卷积,激活
# [None,14,14,32] --->[None,14,14,64]
x_relu2 = tf.nn.relu(tf.nn.conv2d(x_pool1, weight_conv2, strides=[1, 1, 1, 1], padding="SAME") + bias_conv2)
# 池化[None,14,14,64] --->[None,7,7,64]
x_pool2 = tf.nn.max_pool(x_relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# 4,全连接层
with tf.variable_scope("fc"):
# 初始化权重
weight_fc = weight_variables([7 * 7 * 64, 10])
bias_fc = bias_Variables([10])
# 修改形状 [None,7,7,64] --->[None,7*7*64]
x_fc_reshape = tf.reshape(x_pool2, [-1, 7 * 7 * 64])
# 矩阵运算得出每个样本的10个结果
y_predict = tf.matmul(x_fc_reshape, weight_fc) + bias_fc
return x, y_true, y_predict
def conv_fc():
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(r"E:\人工智能\data\mnist_65000_28_28_simple_number", one_hot=True)
x, y_true, y_predict = model()
# 求出所有样本的损失,求平均值
with tf.variable_scope("soft_cross"):
# 求平均值交叉熵损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict))
# 梯度下降求出损失
with tf.variable_scope("optimizer"):
train_op = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
# 计算准确率
with tf.variable_scope("acc"):
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
init_op = tf.global_variables_initializer()
# 开启会话运行
with tf.Session() as sess:
sess.run(init_op)
for i in range(1000):
mnist_x, mnist_y = mnist.train.next_batch(200)
# 运行训练
sess.run(train_op, feed_dict={x: mnist_x, y_true: mnist_y})
print("训练第%d的次,准确率为:%f" % (i, sess.run(accuracy, feed_dict={x: mnist_x, y_true: mnist_y})))
return None

GooglelNet API:tensorflow.contrib.slim.python.slim.nets.inception_v3 import inception_v3_base

 浙公网安备 33010602011771号
浙公网安备 33010602011771号