知识点笔记
win
查看开关机记录
- win + r, 输入eventvwr.msc
- 点击左侧
Windows 日志-系统 - 右侧
筛选当前日志, 输入事件id6005,6006,6008,6013 - 事件id依次是: 开机记录, 关机记录, 异常关机(断电)启动记录, ntp同步事件记录
最近记录
- win + r, 输入recent
- 或者win + e, 快速访问中也有
软件运行记录
- c盘windows下Prefetch会记录软件在何时运行过
java
parallelStream
- strem: 顺序遍历
- parallelStream: 并行遍历
anyMatch
找到一个符合谓词时候就返回, 最好与parallelStream搭配
peek map
两个函数的返回值都是一个新的Stream,但是接收类型 peek是Consumer,map是Function
使用场景: 对象数组的集合流, peek 为遍历数组, 对item进行处理; map为数据库操作都可获取出某个属性或对整个item进行处理后返回
参考:
Collectors.toMap
(oldVal, newVal) -> newVal
List<String> words = Arrays.asList("apple", "banana", "apple", "orange");
Map<String, Integer> wordCount = words.stream()
.collect(Collectors.toMap(
word -> word, // 键:单词本身
word -> 1, // 值:初始计数为1
(oldCount, newCount) -> oldCount + newCount // 合并:累加计数
));
// 结果:{apple=2, banana=1, orange=1}
@Conditional
运行jar包时候可以指定: java -jar myapp.jar --spring.profiles.active=prod
指定prod时运行的话可以使用: @Profile("prod")
-
@ConditionalOnProperty(prefix = "scheduling", name = "enabled", havingValue = "true")
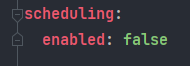
-
ConditionalOnExpression- 只能用于方法、类或注解的声明上
- 基于 Spring 表达式语言(SpEL)来定义条件的,可以使用 SpEL 中的各种运算符、函数和属性来组合条件;如
@ConditionalOnExpression("'prod'.equals('${spring.profiles.active}')")或@ConditionalOnExpression("${spring.profiles.active.equals('prod')}"). - 常用的字符串函数:
- startsWith(prefix):判断字符串是否以指定的前缀开头。
- endsWith(suffix):判断字符串是否以指定的后缀结尾。
- contains(substring):判断字符串是否包含指定的子串。
- equals(str):判断字符串是否与指定的字符串相等。
- matches(regex):判断字符串是否匹配指定的正则表达式。
- substring(startIndex):获取从指定位置开始到字符串结尾的子串。
- substring(startIndex, endIndex):获取指定位置范围内的子串。
- toLowerCase():将字符串转换为小写字母。
- toUpperCase():将字符串转换为大写字母。
- 可用在定时任务上
@Slf4j @Configuration @EnableScheduling @RequiredArgsConstructor @ConditionalOnExpression("'prod'.equals('${spring.profiles.active}')") public class MidJob { } - 在注入bean时候可以与
@Bean放在一起 - 在输入自己写的服务时候
- 在写的setter或者构造函数上加上
- 使用
@RequiredArgsConstructor的onConstructor参数, 如:@RequiredArgsConstructor(onConstructor_ = {@Autowired, @ConditionalOnExpression(...)})
-
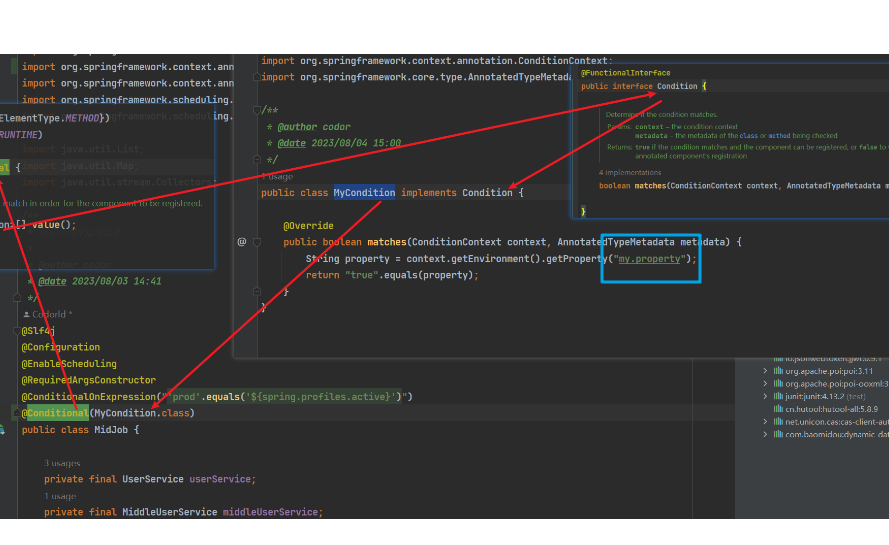
Conditional
使用方法与上面类似, 不过这个是需要实现org.springframework.context.annotation.Condition.matches()方法, 见下图:
sdf线程安全
SimpleDateFormat非线程安全, Date- SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- hutool里面DateUtil的
parse和format方法.
DateTimeFormatter线程安全, LocalDateTime- DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
- hutool里面LocalDateUtil的
parse和format方法, DateUtil的parseLocalDateTime和formatLocalDateTime;
- 参考:
map.compute
根据键是否存在执行put操作. Function: 单参数 BiFunction: 双参数
compute: 不管键是否存在都执行 参数类型(K, BiFunction)computeIfAbsent: 键不存在时候执行 参数类型(K, BiFunction) / (K, V)computeIfPresent键存在时候执行 参数类型(K, BiFunction)- 例子
Map<Integer, Integer> map = new HashMap<>(); // put 1,2 map.put(1, 2); // 2存不存在都执行后面的方法 map.compute(2, (k, v) -> { return 3; }); // 2存不存在都执行后面的方法 map.compute(2, (k, v) -> { return k + (v == null ? 0 : v) + 3; }); // 2不存在时候执行方法, 类似ObjUtil.defaultIfNull(); map.computeIfAbsent(2, k -> 3); // 2存在时候执行此方法 map.computeIfPresent(2, (k, v) -> 3);
poi外边框
多单元格的外边框
import org.apache.poi.ss.usermodel.BorderStyle;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.util.CellRangeAddress;
import org.apache.poi.ss.util.RegionUtil;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
public class ExcelOuterBorderThickWithRegionUtil {
public static void main(String[] args) throws IOException {
Workbook workbook = new XSSFWorkbook();
Sheet sheet = workbook.createSheet("Sheet1");
// 省略单元格填充
// 定义合并区域
CellRangeAddress region = new CellRangeAddress(0, 3, 0, 3);
sheet.addMergedRegion(region);
// 默认细线THIN / 中等MEDIUM / 加粗THICK
BorderStyle thickBorder = BorderStyle.THICK;
// 使用RegionUtil设置区域边框
RegionUtil.setBorderTop(thickBorder, region, sheet);
RegionUtil.setBorderBottom(thickBorder, region, sheet);
RegionUtil.setBorderLeft(thickBorder, region, sheet);
RegionUtil.setBorderRight(thickBorder, region, sheet);
// 将工作簿写入文件
FileOutputStream fileOut = new FileOutputStream("outer_border_example.xlsx");
workbook.write(fileOut);
fileOut.close();
workbook.close();
}
}
jmap
- 用法:
jmap -histo:live <pid> | more - 含义: 查看JVM堆中对象详细占用情况, 以上看到的是存活对象的, 如果需要查看待回收的去掉
:live即可
脚本启动
也可以使用相对路径, 但是要保证包名唯一
#!/bin/sh
NAME=weather-route-handle-service
PIDS=`ps -aux |grep /home/dalianwan/$NAME.jar | grep -v grep |awk '{print $2}' |awk -F '/' '{print $1}'`
for PID in $PIDS ;
do
kill -9 $PID > /dev/null 2>&1
done
echo "" >> /home/dalianwan/console.log.bak
mv /home/dalianwan/console.log /home/dalianwan/console.log.bak
nohup java -Xms1G -Xmx4G -jar /home/dalianwan/$NAME.jar > /home/dalianwan/console.log 2>&1 &
导出excel换行
在刷完数据之后给单元格设置一下样式
String fileName = "设备操作日志导出" + DateUtil.currentSeconds();
// 设置响应类型
response.setContentType("application/vnd.ms-excel");
// 设置字符编码
response.setCharacterEncoding("utf-8");
// 设置响应头信息
response.setHeader("Content-disposition",
"attachment;filename=" + URLEncoder.encode(fileName, "UTF-8") + ".xlsx");
// 写入文件
ExcelWriter writer = ExcelUtil.getWriter(true);
writer.setOnlyAlias(true);
writer.write(list, true);
writer.autoSizeColumn(10);
writer.setColumnWidth(0, 25);
writer.setColumnWidth(1, 25);
writer.setColumnWidth(2, 25);
writer.setColumnWidth(3, 30);
writer.setColumnWidth(4, 25);
writer.setColumnWidth(5, 35);
writer.setColumnWidth(6, 15);
CellStyle style = writer.createCellStyle();
// String.join("\n", record.getOperateDescList())
style.setWrapText(true); // 启用自动换行
style.setAlignment(HorizontalAlignment.CENTER); // 水平居中
style.setVerticalAlignment(VerticalAlignment.CENTER); // 垂直居中
// 设置边框
style.setBorderTop(BorderStyle.THIN);
style.setBorderBottom(BorderStyle.THIN);
style.setBorderLeft(BorderStyle.THIN);
style.setBorderRight(BorderStyle.THIN);
// 不过不是固定列或行, 就两个循环全部刷一遍
for (int i = 0; i < list.size(); i++) {
writer.getOrCreateCell(5, i + 1).setCellStyle(style);
}
try {
writer.flush(response.getOutputStream(), true);
} catch (IOException e) {
e.printStackTrace();
} finally {
writer.close();
}
@JsonFormat
使用@JsonFormat(pattern = DatePattern.NORM_DATETIME_PATTERN)修饰Date或者LocalDateTime的接受参数类时不会使用默认TimeZone.setDefault(TimeZone.getTimeZone("Asia/Shanghai"));配置的JVM时区参数
mp动态修改表名
- Handler
import cn.hutool.core.util.StrUtil; import cn.hutool.log.StaticLog; import com.baomidou.mybatisplus.extension.plugins.handler.TableNameHandler; public class ClickHouseTableNameHandle implements TableNameHandler { // 线程安全 private static final ThreadLocal<String> SUFFIX = new ThreadLocal<>(); public static void setSuffix(String suffix) { SUFFIX.set(suffix); } @Override public String dynamicTableName(String sql, String tableName) { StaticLog.debug("sql: {}", sql); String suffix = SUFFIX.get(); if (StrUtil.isNotEmpty(suffix)) { SUFFIX.remove(); StaticLog.debug("suffix: {}, tableName: {}", suffix, tableName); return tableName + suffix; } return tableName; } } - 配置
import com.baomidou.mybatisplus.annotation.DbType; import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.DynamicTableNameInnerInterceptor; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MybatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); NewPaginationInnerInterceptor innerInterceptor = new NewPaginationInnerInterceptor(DbType.CLICK_HOUSE); interceptor.addInnerInterceptor(innerInterceptor); DynamicTableNameInnerInterceptor tableNameInnerInterceptor = new DynamicTableNameInnerInterceptor(); tableNameInnerInterceptor.setTableNameHandler(new ClickHouseTableNameHandle()); interceptor.addInnerInterceptor(tableNameInnerInterceptor); return interceptor; } } - 使用
ClickHouseTableNameHandle.setPredictSuffix(); // 查询数据库 service.list(); - 参考:
数据库
开启sql打印
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
mysql 列变行
- 注意when后多个满足条件时, 会只取一个, 不会报错.
select max(case when then)SELECT name, MAX(CASE WHEN category = 'A' THEN value END) AS 'A', MAX(CASE WHEN category = 'B' THEN value END) AS 'B', MAX(CASE WHEN category = 'C' THEN value END) AS 'C' FROM my_table GROUP BY name; case when in() then方法, 将1,2,3的算作1; 5,6,7的算作8SELECT CASE WHEN your_column IN (1, 2, 3) THEN 1 WHEN your_column IN (5, 6, 7) THEN 8 ELSE your_column END AS grouped_column, COUNT(*) AS group_count FROM your_table GROUP BY grouped_column;- 参考: mysql列变行
mybatis @var
必须在数据库配置文件的数据库地址url中加上一个属性allowMultiQueries=true
参考: MySQL设置变量以及如何在Mybatis中使用
insert select *
中间不要value 或 values, mysql中可以省略into
- mysql:
insert t1(v1, v2, v3) select v1, v2, v3 from t2 - pgsql:
insert into t1(v1, v2, v3) select v1, v2, v3 from t2
mysql field()
FIELD(str,str1,str2,str3,...)
- 与order by 组合使用, 让字段按照后续字典表中的内容排序
select * from demo order by field(review_status, 2, 3, 1), 其中review_status为字段名
field()后可以跟desc与ascasc(默认): 按照表顺序(231), 且不存在231中的数据排在前面, 231的数据在最后desc: 按照表降序(132), 且不存在132中的数据排在后面, 132的数据在最前面
- 单独使用, 求出第一个值在后列表中的位置(从1开始)
- 第一个值是数字或字符串:
select field(1, 1, 2, 3, 4, 5) res结果是1 - 第一个值是语句:
select field((select id from (SELECT * FROM demo where id = 1) tt), 4, 1, 2, 1, 3) res结果是2(后面多个1是取第一个的索引) - 后面存在语句
select field(1, (select id from (SELECT * FROM demo where id in (1, 2, 3)) tt)) res运行报错Subquery returns more than 1 row, 表示子查询返回多列, 如果其他地方遇到这种情况需要使用limit 1或关键词any或some等等 - 补充: 当后面列表中不存在第一个值 或 第一个值为null时 返回0
- 第一个值是数字或字符串:
- pgsql
SELECT * FROM demo
ORDER BY
CASE review_status
WHEN 2 THEN 1 -- 2 排在第1位
WHEN 3 THEN 2 -- 3 排在第2位
WHEN 1 THEN 3 -- 1 排在第3位
ELSE 0 -- 不在列表中的值映射为0(排在最前)
END ASC; -- ASC为默认,可省略
sum(type = 1)
注意必须用sum才可以使用条件,count不可以, 如果count(*)=0时候type_1_percentage为null
SELECT COUNT(*) AS total_count,
SUM(type = 1) AS type_1_count,
(SUM(type = 1) / COUNT(*)) * 100 AS type_1_percentage
FROM your_table;
pgsql中虽然不支持这样, 但是可以sum(case when type = 1 then 1 else 0), 巧妙引入case when语句来解决
redis 备份恢复
- 备份: 使用redis-cli连接server, 如果有密码的话 auth 123(密码)授权
- bgsave: 后台生成备份文件
- save: 生成备份文件, 会阻塞其他指令
生成的文件路径在redis.conf中的dir下
- 关闭需要恢复的redis服务器上的redis服务(因为redis关闭时候会将内容的数据备份到路径下, 我们要覆盖他旧的备份文件)
- 移动到需要备份redis服务器上的dir指向的路径(如果dir配置也是默认的, 可以选择配置一下, 或者执行以下save指令, 看生成的dump文件在哪里,就复制到哪里), 然后启动redis即可.
关于dir配置的路径: 默认的./, 但是我生成的备份文件在根目录下, 反正根目录, 主目录, redis安装目录结合生成/修改时间检查一下. 恢复服务器那边不清楚的话, 可以执行save指令查看以下生成dump.rdb文件在哪里, 就复制到哪里就行, 建议配置将日志和路径都修改到redis安装目录或者自定义的数据路径中, 防止出现默认./结果出现在根目录下的情况.
联表更新
- mysql
UPDATE t1 JOIN t2 ON t1.t2_id = t2.id SET t1.t2_name = t2.name; - pgsql
UPDATE t1 SET t2_name = t2.name FROM t2 WHERE t1.t2_id = t2.id;
执行中的sql
- pgsql:
SELECT pid, query FROM pg_stat_activity - mysql: 无法找到pid与正在执行sql的关系, 可人为通过
show processlist来找(来源是表information_schema.processlist), 故也可通过SELECT * FROM information_schema.processlist实现
数据库迁移
- 处理之前一定做好数据备份!!! 或者在同版本同架构的虚拟机上进行测试
- mysql
- 停止mysql
- 默认数据路径:
/var/lib/mysql - 查看目标目录上的用户和用户组是否与默认路径相同, 如果不同, 使用
chown -R 用户:组 /路径修改 - 复制或移动到目标目录
- 配置文件路径:
/etc/mysql/my.cnf 或 /etc/my.cnf, 修改其内的datadir - 启动后进行
- pgsql
- 停止pgsql:
systemctl stop postgresql-14 - 默认数据位置:
/var/lib/pgsql/14/data - 查看目标目录上的用户和用户组是否与默认路径相同, 如果不同, 使用
chown -R pgsql:pgsql /home/pgsql/data修改 - 复制或移动到目标路径
- 修改目录权限
chmod 0700 /home/pgsql/data或chmod 0750 /home/pgsql/data - 配置文件路径: 目标目录
data下的配置文件postgresql.conf, 修改期内的data_directory - 修改
/usr/lib/systemd/system/postgresql-14.service: 找到Environment=PGDATA后面的路径 - 重载:
systemctl reload postgresql-14 - 启动pgsql:
systemctl start postgresql-14
- 停止pgsql:
navicat结果标题
-- NAME: 自定义的标题, 另起一行写查询.- 参考: navicat 查询结果重命名
redis命名空间
命名空间在图形化工具rdm中看到的效果类似文件目录一样, 他将同样前缀(:前的, 大于等于两条数据)的数据以前缀为目录归并起来, 而在使用上就当成一个整体使用即可
(这里提供两个版本下载rdm2021.4, 和rdm2022.5, 老版本稳定, 新版本界面和功能多, 电脑性能不高可能会卡)
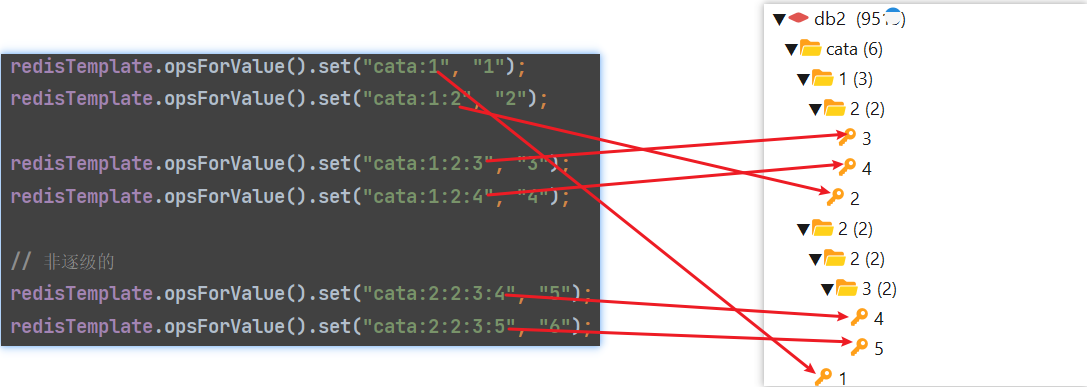
redisTemplate.opsForValue().set("cata:1", "1");
redisTemplate.opsForValue().set("cata:1:2", "2");
redisTemplate.opsForValue().set("cata:1:2:3", "3");
redisTemplate.opsForValue().set("cata:1:2:4", "4");
// 非逐级的
redisTemplate.opsForValue().set("cata:2:2:3:4", "5");
redisTemplate.opsForValue().set("cata:2:2:3:5", "6");
coalesce
- 含义: 从传入参数中找到第一个不为null的方法
- 用法:
coalesce(null, 0) - 类似: 深入理解与实战SQL IFNULL()函数
- 参考: sql:函数:COALESCE()
逗号分隔存储
在一对多的关系中, 多个的一方如果没用额外字段(比如一个人多个部门, 其中有部门职务等)时,
可以将id或编号放在一个字段上, 在搜索(比如输入部门id, 找出部门中的人有哪些)时可以使用此方法.
- 数据库:
,1,,2,,3,,4,,5,, 双逗号分隔存储, 读取出来解析时候也可以直接双逗号分割 - 搜索:
where depart_ids like ',1,%,3,%',13-(%拼接)->1%3-(逗号拼接, 两端加逗号)->,1,%,3, - 缺点: 如果多的找少的, like时候就找不到的多出来的id, 只能拆开id
(ids LIKE '%,,1,,%' OR ids LIKE '%,,2,,%' OR ids LIKE '%,,4,,%') - 代码:
// 从ids到idStr
public String in(List<Integer> ids) {
if (CollUtil.isEmpty(ids)) {
return null;
}
// 排序
ids.sort(Comparator.comparing(Integer::valueOf));
return ",," + StrUtil.join(",,", ids) + ",,";
}
// 从idStr到ids
public List<Integer> out(String idStr) {
if (StrUtil.isEmpty(idStr)) {
return new ArrayList<>();
}
List<String> ids = StrUtil.split(idStr, ",,", true, true);
// 将数字的保留下来
return ids.parallelStream().filter(StrUtil::isNumeric)
.map(Integer::parseInt).collect(Collectors.toList());
}
// 参数为名称模糊搜索出来的ids 或者 联表时需要过滤出来的
public String likeParam(List<Integer> ids) {
if (CollUtil.isEmpty(ids)) {
return "%";
}
// 排序
ids.sort(Comparator.comparing(Integer::valueOf));
// 2 3
// 2%3
// 2,%,3
// ,2,%,3,
// 返回的值直接like, like时会自动往两边带%
return "," + StrUtil.join(",", StrUtil.join("%", ids)) + ",";
}
clickhouse日志清理
使用默认配置运行半年之后400G的分区被日志写满了, 读取写入操作还是挺频繁的.
- 进入
clickhouse目录/data/store下, 或者通过du -sh指令来定位, 删除一些考前时间的日志, 将服务启动起来 - 快速定位的情况
SELECT database, table, formatReadableSize(sum(bytes_on_disk)) AS disk_space
FROM system.parts
--where system.parts.`database` = 'system'
GROUP BY database, table
ORDER BY disk_space DESC;
- 手动删除十天以前的:
ALTER TABLE system.table_name DELETE WHERE event_date < today() - INTERVAL 10 DAY; - 配置十天以前自动删除ttl:
ALTER tablesystem.table_name MODIFY TTL event_date + toIntervalDay(10); - 在配置文件中添加ttl,
vim /etc/clickhouse-server/config.xml
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
linux
du(disk usage)
- 用法:
du -sh * | sort -rh, 中间*是路径 - 解释:
-s: 只显示总计大小,而不显示每个子目录和文件的大小。就是加了不限制子文件(目录), 不加显示子文件(目录), 子文件的大小是都计算进去的-h: 以人类可读的格式显示大小,例如使用KB、MB、GB等单位.sort -rh: 将结果按照大小从大到小排序, r倒序, h以人类可读格式.- 更多通过
sort --help了解.
- 补充
- du -sh 后面没有
*时候, 统计的是当前目录的总大小 - 显示前面几条: 最后加
du -sh * | sort -rh | head -n 5. 以下针对-s的有无举两个例子- du -h 路径没有
*

- du -h 路径有
*, 相比上一个就少了一个当前当前目录, 因为没有-s, 所以所有目录和子文件都展示
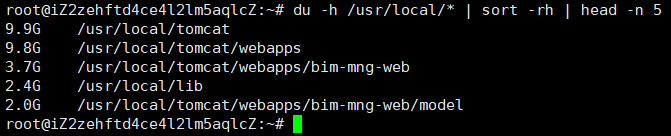
- du -sh 路径没有
*, 这种就显示那个目录下的

- du -sh 路径有
*, 只显示当前目录的各个目录内容, 加了-s只显示当前目录下各个的总大小

- du -h 路径没有
- du -sh 后面没有
systemctl
- systemctl 中
ExecStart等配置的指令或脚本内的指令使用的环境变量并不是$PATH,
而是固定的/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin, 也即默认的$PATH路径,
所以只在$PATH中添加路径并不行.可以将链接加入上面路径中或者在ExecStart中或脚本中使用绝对路径, 比如/path/to/command - 或者建立软链接:
ln -s /path/to/comand /usr/bin/command - 如果环境中存在多个java版本或者自己按照的jre找不到错误所在, 可以优先考虑使用绝对路径
- 备注: 指令比如java, 一些脚本(如tomcat)会自动去自动找
JAVA_HOME, 这时候可以在service文件中添加
Environment=JAVA_HOME=/usr/lib/jvm/java-1.8.0/ - 参考1: systemctl方式启动jar报错java: command not found
- 参考2: 执行Shell脚本,报java: command not found
- 参考3: systemd Unable to find Java
ps(process status)
- 显示所有进程:
ps -e或ps -A - 显示所有用户的进程:
ps -ef或ps aux, ps aux --sort=-%mem | head -n 5 显示5个占用内存最多的进程. - 显示进程树状结构:
ps -ejH或ps axjf
kylin audit
- 问题描述: 内存占用高
- 临时解决:
systemctl stop auditd.service - 升级版本:
yum install -y audit - 参考:
systemctl打印
- 问题描述: 使用
systemctl status tomcat时控制台无打印. 或者打印完没有退出, 末尾显示lines 1-13/13 (END) - 原因: 可能会因为屏幕缓冲区的限制而无法完全显示
- 临时读取
- 重定向到一个文件中
systemctl status tomcat >> acat a查看
systemctl status tomcat | less, less支持向前向后滚动, 只加载需要展示的, 退出后shell上不会保留systemctl status tomcat | more, more只能向前, 会加载所以, 然后逐页展示, 退出后shell后保留systemctl status tomcat --no-pager, 输出将不会被任何分页器处理
- 重定向到一个文件中
- 禁用分页展示
- 临时解决:
export SYSTEMD_PAGER="", 或者export PAGER="" - 永久解决:
- 修改用户的shell文件
.bashrc或.bash_profile - 在最后添加
export SYSTEMD_PAGER=""或export PAGER="" source ~/.bashrc加载- 在新窗口里面测试是否生效
- 修改用户的shell文件
- 临时解决:
- 参考: 通过systemctl status查询服务状态未退出
ulimit句柄数
-
全局
- 使用情况:
cat /proc/sys/fs/file-nr, 已分配, 已分配但未使用, 最大文件描述符 - 文件描述符数量:
vim /etc/security/limits.conf#任何用户可以打开的最大的文件描述符数量,默认1024,这里的数值会限制tcp连接 * soft nofile 655350 * hard nofile 655350 - 进程数量:
vim /etc/security/limits.d/20-nproc.conf#任何用户可以打开的最大进程数 * soft nproc 655350 * hard nproc 650000
- 使用情况:
-
特定进程
- 特定进程资源限制情况:
cat /proc/[pid]/limits, 查看Max open files - 统计数量:
lsof -p pid | wc -l, 或者使用ls -l /proc/122464/fd | wc -l - 查看所有文件描述符:
lsof -p pid > openfiles.txt systemctl管理:[Service]内添加LimitNOFILE=65535之后重载, 重启.
(或者设置为infinity, 这样Max open files就会对应unlimited
但是非常不建议这样做, 如果死循环后可能对系统稳定性造成影响)- 默认来自
/etc/systemd/system.conf,/etc/systemd/user.conf - 或者直接查看:
systemctl show --property=DefaultLimitNOFILE
- 默认来自
保存之后需要重启java进程(打开太多文件 / Too Many Open Files)
- 特定进程资源限制情况:
-
参考
scp
scp /path/to/file username@remote:/path/to/destinationscp apache-tomcat-8.5.81.tar.gz root@10.154.196.54:/opt/apache-tomcat-8.5.81.tar.gz

 浙公网安备 33010602011771号
浙公网安备 33010602011771号