14周学习汇总(关于强化学习在目标检测中微调的小问题)
14周学习问题汇总
周学习简单汇报:因为没有布置具体任务,我去看了王树森那本《深度强化学习》巩固了一些概念性的基础知识,手推了上次师兄讲的如何在cv任务中用强化学习微调的所有过程,下面是在推导过程中遇到的一些问题(有些问题是确认自己理解的对不对,有些是对计算过程的不理解)
Q1:目标检测中,state是图像,action是预测框?分别对应的是损失函数里的x和y吗?
A:图像 = state = x, action = 预测框 != y y是标签
Q2:为什么是max E[V(S;θ],要强调状态和策略,怎么理解(不能直接max E[U_t]吗,之前一直说强化学习的目标是最大化return,现在是最大化状态价值函数应该怎么理解)

A: 理论上来说确实应该最大化return,但是return与太多随机变量相关,最大化状态价值函数是最大化return的一个充分条件
Q3:

参考了:(69条消息) 【强化学习理论】状态价值函数与动作价值函数系列公式推导_Mocode的博客-CSDN博客

如果动作价值函数和θ独立,那可以推出状态价值函数也和θ独立,与状态价值函数可对θ求导矛盾?
A: 事实上确实θ和动作价值函数确实不独立,但是推导起来会很麻烦,这里假设独立和不独立的结果是一样的,方便计算便假设独立了
Q4: 如果用ut来估计,那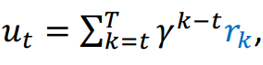 中T的含义是什么,(就是目标检测的轨迹是什么)(如果是多轮检测,后面step_reward里好像针对的是一轮)
中T的含义是什么,(就是目标检测的轨迹是什么)(如果是多轮检测,后面step_reward里好像针对的是一轮)

A: 事实上,在目标检测中,每次的u_t只有一轮,也就是上述公式中,T=t
Q5:n是样本数吗?对loss求和取平均的意义是什么

A: n是样本数,这里loss实际的推导其实是通过梯度反推导的,
我们先是推导出了policy gradient为: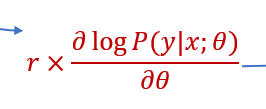
然后通过这个梯度,进行一个类似积分的操作(感觉可以看成是蒙特卡洛?),求和取平均,来得到我们的loss函数
Q6: y_sample 和 y_baseline 是什么?“降低梯度估计的方差”这句话不理解

A: 大致是让一个随机变量的期望减去一个baseline,可以减小这个随机变量的方差。(好像高中数学有过类似的,E[X-b]与E[X]一样,但是Var[X-b]比Var[X]小,待查证),可以让loss稳定收敛
学习过程中一些其余小问题:
Q1: 对二分类(/多分类)问题建模构建似然函数的时候,如何理解那个次方项(从建模角度)

A:其实就是一个0-1分布,次方通过二项分布的似然函数推导去理解即可
Q2:在蒙特卡罗法求近似期望过程中,书中提到,对概率密度函数做非均匀抽样,可以更快收敛,怎么理解这句话(为什么非均匀会比均匀更好)

A:还未解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号