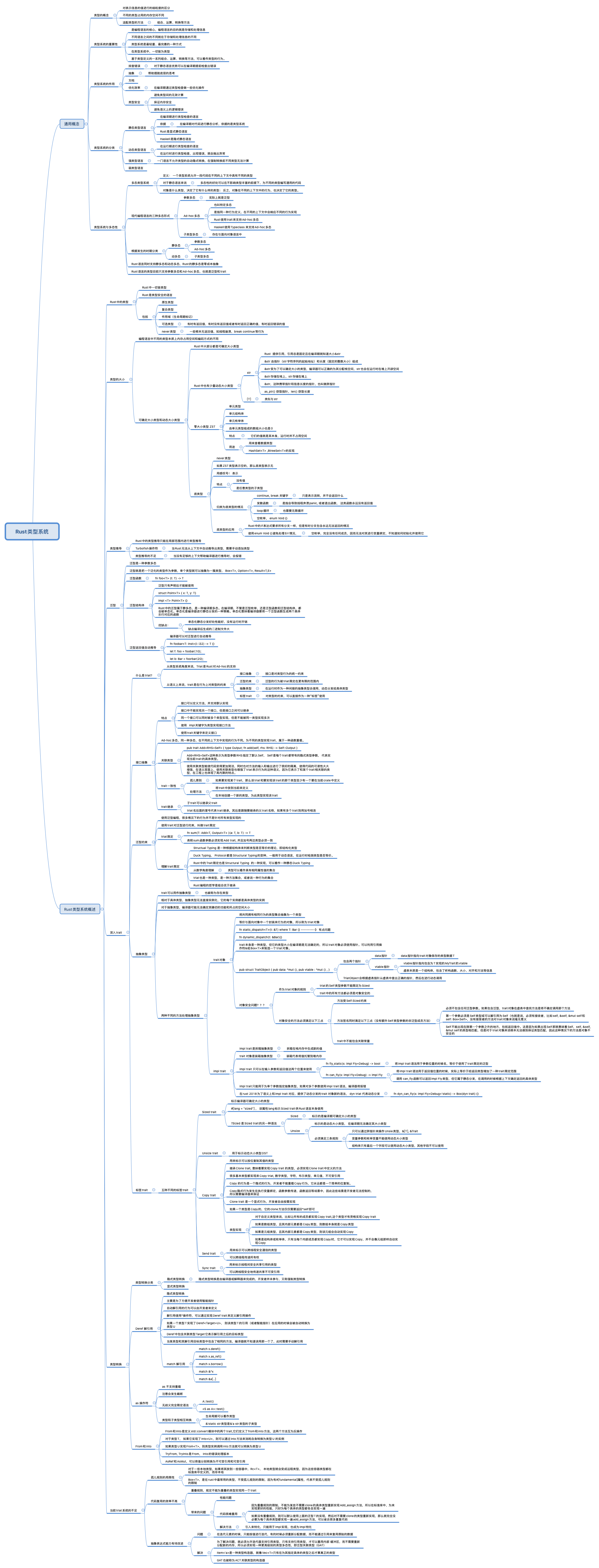
Rust的类型系统
Rust的类型系统
类型于20世纪50年代被FORTRAN语言引入,其相关的理论和应用已经发展得非常成熟。现在,类型系统已经成为了各大编程语言的核心基础。
通用基础#
所谓类型,就是对表示信息的值进行的细粒度的区分。比如整数、小数、文本等。
不同的类型占用的内存不同。与直接操作比特位相比,直接操作类型可以更安全、更有效地的利用内存。
计算机不只是存储信息,计算机要处理信息。
不同的类型的计算规则是不一样的。因此需要对这些基本的类型定义一系列的组合、运算、转换等方法。
如果把编程语言看作虚拟世界的话,那么类型就是构建这个世界的基本粒子,这些粒子通过各种组合、运算、转换等反应,造就这个世界中的各种事物。
类型之间纷繁复杂的交互形成了类型系统,**类型系统是编程语言的基础和核心,因为编程语言的目的就是存储和处理信息。不同编程语言之间的区别就在于如何存储和处理信息。
在计算机科学中,对信息的存储和处理不止类型系统这一种方式,还有其他的一些理论框架,只不过类型系统是最轻量、最完善的一种方式。
在类型系统中,一切皆类型。基于类型定义的一系列组合、运算和转换等方法,可以看作类型的行为。
类型的行为决定了类型如何计算,同时也是一种约束,有了这种约束才可以保证信息被正确处理。
类型系统的作用#
类型系统是一门编程语言不可或缺的部分,它的的优势有以下几个方面:
- 排查错误。很多编程语言都会在编译期或运行期进行类型检查,以排查违规行为,保证程序正确执行,如果程序中有类型不一致的情况,或有未定义的行为发生,则可能导致错误产生。尤其对于静态语言来说,能在编译期排查出错误是一个很大的优势,这样可以及早地处理问题,而不必等到运行后类型系统崩溃了再解决。(早期排查出错误,对于静态语言来说是很大的优势)
- 抽象。类型允许开发者在更高层面进行思考,这种抽象能力有助于强化编程规范和工程化系统。比如,面向对象语言中的类型就可以作为一种类型。(抽象可以帮助摆脱底层细节的思考)
- 文档。在阅读代码的时候,明确的类型声明可以表明程序的行为。
- 优化效率。这一点对于静态编译语言来说,在编译期可以通过类型检查来优化一些操作,节省运行时的时间。
- 类型安全。
- 类型安全的语言可以避免类型间的无效计算,比如可以避免3/"hello"这样不符合算术运算规则的计算。
- 类型安全的语言还可以保证内存安全,避免诸如空指针、悬垂指针和缓存区溢出等导致的内存安全问题。
- 类型安全的语言可以避免语义上的逻辑错误,比如以毫米为单位的数值和以厘米为单位的数值虽然都是以整数来存储的,但可以用不同的类型来区分,避免逻辑错误。
类型系统的分类#
在编译期进行类型检查的语言属于静态类型,
在运行期进行类型检查的语言属于动态类型。
如果一门语言不允许类型的自动隐式转换,在强制转换前不同类型无法进行计算,则该语言属于强类型,反之则属于弱类型。
静态类型的语言能在编译期对代码进行静态分析,依靠的就是类型系统。
以数组越界访问为例。C/C++在编译器并不检查数组是否越界访问,运行时可能会得到难以意料的结果,而程序依旧正常运行,这属于类型系统中未定义的行为,所以它们不是类型安全的语言。
Rust语言在编译期就能检查出数组是否越界访问,并给出警告,让开发者及时修改,如果开发者没有修改,那么运行时也会抛出错误并退出线程,而不会因此去访问非法的内存,从而保证了运行时的内存安全,所以Rust是类型安全的语言。
强大的类型系统可以对类型进行自动推导,因此一些静态语言在编写代码的时候不用显式地指定具体的类型,比如Haskell就被称为隐式静态类型。
Rust语言的类型系统受Haskell启发,也可以自动推导,但不如Haskell强大。在Rust中大部分地方还是需要显示指定类型的,类型是Rust语法的一部分,因此Rust是显示静态类型。
动态类型语言只能在运行时进行类型检查,但是当有数组越界访问时,就会抛出异常,执行线程退出操作,而不是给出奇怪的结果。
在其他语言中作为基本类型的整数、字符串、布尔值等,在Ruby和python语言中都是对象。实际上,也可将对象看作类型,Ruby和python语言在运行时通过一种名为Duck Typing的手段来进行运行时类型检查,以保证类型安全。在Ruby和python语言中,对象之间通过消息进行通信。如果对象可以响应该消息,则说明该对象就是正确的类型。
对象是什么样的类型,决定了它有什么样的行为;反过来,对象在不同上下文中的行为,也决定了它的类型。这其实就是一种多态性。
类型系统与多态性#
如果一个类型系统允许一段代码在不同的上下文中具有不同的类型,这样的类型系统就叫做多态类型系统,对于静态类型系统语言来说,多态性的好处是可以在不影响类型丰富的前提下,为不同的类型编写通用的代码。
现代编程语言包含了三种多态形式:
- 参数多态(parametric polymorphism)
- Ad-hoc多态(Ad-hoc polymorphism)
- 子类型多态(subtype polymorphism).
如果按多态发生的时间来划分,又可以分为静多态(static polymorphism)和动多态(Dynamic Polymorphism)。
静多态发生在编译期,动多态发生在运行时。
参数化多态和Ad-hoc多态一般是静多态,子类型多态一般是动多态。
静多态牺牲灵活性获取性能,动多态牺牲性能获取灵活性。
动多态在运行时需要查表,占用较多空间,所以一般情况下都使用静多态。
Rust语言同时支持静多态和动多态,静多态就是一种零成本抽象。
参数化多态实际上就是泛型。很多时候函数或数据类型都需要适用于多种类型,以避免大量的重复性工作。泛型使得语言极具表达力,同时也能保证静态类型安全。
Ad-hoc多态也叫特定多态。Ad-hoc多态是指同一种行为定义,在不同的上下文中会响应不同的行为实现。**Haskell语言中使用Typeclass 来支持Ad-doc多态,Rust受Haskell启发,使用trait来支持Ad-hoc多态。所以Rust的trait系统的概念类似于Haskell中的Typeclass
子类型多态的概念一般用在面向对象语言中,尤其是Java语言中,Java语言中的多态就是子类型多态,它代表一种包含关系,父类型的值包含了子类型的值,所以子类型的值有时也可以看作父类型的值,反之则不然。而Rust语言中并没有类似Java中的继承的概念,所以也不存在子类型多态。所以,Rust中的类型系统目前只支持参数化多态和Ad-hoc多态,也就是,泛型和triat。
Rust类型系统概述#
Rust是一门强类型且类型安全的静态语言。Rus中一切皆表达式,表达式皆有值,值皆有类型。因此,Rust中一切皆类型。
Rust中包含基本的原生类型和复合类型,Rust把作用域也纳入了类型系统,也就是生命周期标记,还有一些表达式,有时有返回值,有时没有返回值(返回单元值)或者有时返回正确的值,有时返回错误的值,Rust将这类情况也纳入了类型系统,这就是Option<T>和Result<T,E>这样的可选类型,从而强制开发人员必须分别处理这两种情况。
一些根本无返回值的情况,比如线程崩溃、break或continue等行为,也都被纳入了类型系统,这种类型叫做never类型。
因此,Rust的类型系统基本囊括了编程中会遇到的各种情况,一般情况下不会有未定义的行为出现,所以说,Rsut是类型安全的语言。
类型大小 #
编程语言中不同的类型本质上是内存中占用空间和编码方式的不同。
Rust中没有GC,内存首先由编译器来分配,Rust代码被编译为LLVM IR, 其中携带来内存分配的信息,所以编译其需要事先直到类型的大小,才能分配合理的内存,
可确定大小类型和动态大小类型#
Rust中绝大部分类型都是在编译期可确定大小的类型(sized Type), 比如原生类型整数类型u32固定是4个字节,可以在编译期确定大小的类型。
Rust中也有少量的动态大小的类型(Dynamic Sized type, DST),比如 str类型的字符串字面量,编译器不可能事先知道程序中会出现什么样的字符串,所以对于编译器来说,str类型的大小是无法确定的。
(Rust有动态类型,例如str,但是对于编译器不能提前就知道程序在运行时是什么字符串,对于编译器来说,str的大小是无法确定的,所以Rust提供来引用,引用总是有固定且在编译期就知道大小,例如&str)
对于这种情况,Rust提供类引用类型,因为引用总会有固定的且在编译期已知的大小。字符串切片&str就是一种引用类型,它由指针和长度信息组成。
&str 存储在栈上,str字符串序列存储于堆上。&str由两部分组成:指针和长度信息,其中指针是固定大小的,存储的是str字符串序列的起始地址,长度信息也是固定大小的整数。因此,&str就变成了可确定大小的类型,编译器就可以正确地为其分配栈内存空间,str也会在运行时在堆上开辟内存空间。
1 let str = "hello, Rust"; 2 let ptr = str.as_ptr(); 3 let len = str.len(); 4 println!("{:?}", ptr); 5 println!("{:?}", len);
通过as_ptr 和 len 方法,可以分别获取字符串字面量的地址和长度信息,这种包含了动态大小类型地址信息和携带长度信息的指针,叫做胖指针(Fat pointer) ,所以&str是一种胖指针。
和str类似的是[T],
Rust中的数组[T]也是动态大小类型,编译器难以确定它的大小。

1 fn rest(mut arr: [u32]){ 2 // [u32] 是动态大小的类型,编译器是无法确定的 3 //^ [u32] does not have a constant size known at compile-time 4 arr[0] = 5; 5 arr[1] = 4; 6 arr[2] = 3; 7 arr[3] = 2; 8 arr[4] = 1; 9 println!("reset arr {:?}", arr); 10 } 11 12 fn main() { 13 let arr: [u32] = [1, 2, 3, 4, 5]; 14 reset(arr); 15 println!("origin arr {:?}", arr); 16 }
第一种方式, 通过传入[u32;5]显示的标明长度信息
1 fn reset(mut arr: [u32;5]){ 2 //[u32;5]表示这是一个数组元素类型是u32, 长度大小为5的数组。 3 arr[0] = 5; 4 arr[1] = 4; 5 arr[2] = 3; 6 arr[3] = 2; 7 arr[4] = 1; 8 println!("reset arr {:?}", arr); //[5, 4, 3, 2, 1] 9 } 10 11 fn main() { 12 let arr: [u32; 5] = [1, 2, 3, 4, 5]; 13 reset(arr); 14 println!("origin arr {:?}", arr);//[1, 2, 3, 4, 5] 15 }
u32类型是可复制的类型,实现了Copy trait,所以整个数组也是可复制的。所以当数组被传入函数中时就会被复制一份新的副本。这里,[u32]和[u32;5]是两种不同的类型。
第二种,使用胖指针
1 fn reset(arr: &mut [u32]) { 2 arr[0] = 5; 3 arr[1] = 4; 4 arr[2] = 3; 5 arr[3] = 2; 6 arr[4] = 1; 7 8 println!("array length {:?}", arr.len()); 9 10 println!("reset array {:?}", arr); 11 } 12 13 fn main() { 14 15 let mut arr = [1, 2, 3, 4, 5]; 16 17 println!("reset before: origin array {:?}", str); //[1, 2, 3, 4, 5] 18 { 19 let mut_arr: &mut [u32] = &mut arr; 20 reset(mut_arr); 21 } 22 println!("reset after: origin array {:?}", arr);//[5, 4, 3, 2, 1] 23 }
&mut [u32]是可变借用,&[u32]是不可变借用。将引用当作函数参数,意味着被修改的是原始数组,而不是最新的数组,所以原数组在reset之后也发生了改变。
1 //比较&[u32;5]和&mut [u32]两种类型的空间占用情况 2 fn main() { 3 assert_eq!(std::mem::size_of::<&[u32;5]>(), 8); //&[u32;5]占8个字节 4 assert_eq!(std::mem::size_of::<&mut [u32]>(), 16);//& mut [u32]占16个字节 5 } 6 //std::mem::size_of::<T>()函数可以返回类型的字节数, 7 //&[u32;5]类型是普通类型,占8个字节。&mut [u32]类型为胖指针,占16个字节。
零大小类型(Zero Sized Type, ZST)#
例如:单元类型和单元结构体,大小都是零。
1 enum Void {} 2 struct Foo; 3 struct Baz { 4 foo: Foo, //单元结构体 5 quz: (),//单元类型 6 baz: [u8; 0],//数组的长度为0 7 } 8 fn main() { 9 assert_eq!(std::mem::size_of::<()>(), 0);//单元类型 10 assert_eq!(std::mem::size_of::<Foo>(), 0);//单元结构体 11 assert_eq!(std::mem::size_of::<Baz>(), 0);//复合结构体 12 assert_eq!(std::mem::size_of::<Void>(), 0);//单元枚举体 13 assert_eq!(std::mem::size_of::<[();10]>(), 0);//长度为10的单元类型数组 14 }
单元类型和单元结构体的大小为零,由单元类型组成的数组大小也为0,([();10], 长度为10的单元类型数组大小为0)。
ZST类型的特点是,它们的值就是其本身,运行时并不占用内存空间。ZST类型代表的意义是‘空’。
单元类型的使用技巧, 用来查看数据类型
1 let v: () = vec![0;10]; 2 // expected (), found struct 'std::vec::Vec' 3 //使用Vec<()>迭代器 4 let v: Vec<()> = vec![(); 10]; 5 for i in v { 6 println!("{:?}", i); 7 } 8 //在Vec内部迭代器中对ZST类型做了一些优化
另外的用途;在Rust官方标准库中HashSet<T>和BTreeSet<T>,只是把HashMap<K, T>换成了HashMap<K, ()>然后就可以公用HashMap<K, T>之前的代码,而不需要重新再实现一遍HashSet<T>.
底类型 #
底类型 bottom type是源自类型理论的术语, never类型。
特点是:
- 没有值
- 是其他任意类型的子类型
ZST类型表示‘空’, 底类型表示‘无’。底类型无值,而且它可以等价于任意类型,有无中生有的意思。
Rust中的底类型用叹号!来表示。也被称为Bang Type。
Rust中有很多情况确实没有值,但为了类型安全,必须把这些情况纳入类型系统进行统一处理。
- 发散函数
- continue和break关键字
- loop循环
- 空枚举,enum Void {}
发散函数是指会导致线程崩溃的painc!("This function never return!"), 或者用于退出函数的std::process::exit,这类函数永远都不会有返回值。
continue和break也是类似的,它们只是表示流程的跳转,并不会返回什么。loop循环虽然可以返回某个值,但也需要无限循环的时候。
Rust中的if语句是表达式,要求所有分支类型一致,但是有的时候,分支中可能包含了永远无法返回的情况,属于底类型的一种应用。
1 #![feature(never_type)] 2 fn foo() -> ! { 3 // ... 4 loop { println!("jh"); } 5 } 6 7 fn main() { 8 9 let i = if false { 10 foo(); // 返回! 11 else { 12 100 // 返回100 13 }; 14 assert_eq!(i, 100); 15 } 16 //编译可以通过,把else表达式中的整数类型换成字符串或其他类型,编译器也可以通过。
空枚举,比如enum Void {}, 完全没有任何成员,因而无法对其进行变量绑定,不知道如何初始化并使用它,所以他也是底类型。
1 enum Void {} 2 fn main() { 3 let res: Result<u32, Void> = Ok(0); 4 let Ok(num) = res; 5 }
Rust中使用Result类型来进行错误处理 ,强制开发者处理OK和Err两种情况,但是有时可能永远没有Err,这时使用enum Void{}就可以避免处理Err的情况。
这里也可以使用if let 语句处理,这里为了说明空枚举的用法。
类型推导#
类型标注在Rust中属于语法的一部分,所以Rust属于显式类型语言。
Rust支持类型推断,但是其功能并没有Haskell那样强大,Rust只能在局部范围内进行类型推导。
1 fn sum(a: u32, b: i32) -> u32 { 2 a + ( b as u32) 3 } 4 5 fn main() { 6 let a = 1; 7 let b = 2; 8 assert_eq!(sum(a, b), 3); 9 let elem = 5u8; 10 let mut vec = Vec::new(); 11 vec.push(elem); 12 assert_eq!(vec, [5]); 13 }
Turbofish操作符#
当Rust无法从上下文中自动推导出类型的时候,编译器会通过错误信息提示,请求你添加类型标注。
1 fn main() { 2 let x = "1"; 3 println!("{:?}", x.parse.unwarp()); 4 // error, type annotations required 5 }
这里想把字符串1,转换称整数类型1,但是parse方法其实是一个泛型方法,当前无法自动推导类型,所以rust编译器无法确定到底要转换成那种类型的整数, u32还是i32?
1 fn main() { 2 let x = "1"; 3 let int_x : i32 = x.parse().unwarp();//一种标注类型的方法 4 assert_eq!(int_x, 1); 5 } 6 fn main() { 7 let x = "1"; 8 assert_eq!(x.parese::<i32>().unwarp(), 1);//一种标注类型的方法 9 }
使用了parse::<i32>的形式为泛型函数标注类型,这样避免了变量声明。这种::<>的形式叫做turbofish操作符。
类型推导的不足#
1 fn main() { 2 let a = 0; 3 let a_pos = a.is_positive(); 4 } 5 //Error, no mathod named 'is_positive' found for type '{integer}' in the current scope
is_positive()是整型类型实现用于判断正负的方法,但是当前Rust编译会出错。这里出现{integer}类型并非真实类型,他只是被用于错误信息中,表明此时编译器已经知道变量a是整数类型,但并未推导变量a的真正类型,因为此时没有足够的上下文信息帮助编译器进行推导。所以在用Rust编程的时候,应尽量显式声明类型,可以避免麻烦。
泛型 #
泛型 Generic 是一种参数化多态。使用泛型可以编写更为抽象的代码,减少工作量。
泛型就是把一个泛化的类型作为参数,单个类型就可以抽象为一簇类型。
Box<T>, Option<T>, Result<T, E>都是泛型。
泛型函数#
1 fn foo<T>(x: T) -> T { 2 x 3 } 4 fn main() { 5 assert_eq!(foo(1), 1); 6 assert_eq!(foo("hello"), "hello"); 7 }
泛型结构体#
结构体名称旁的<T>叫做泛型声明,泛型只有被声明之后才可以被使用。在为泛型结构体实现具体方法的时候,也需要声明泛型类型。
1 struct Point<T> { 2 x: T, 3 y: T, 4 } 5 6 #[derive(Debug, PartialEq)] 7 struct Point<T> { 8 x: T, 9 y: T, 10 } 11 impl <T> Point<T> { //需要先声明T, 之后才能使用T 12 fn new(x: T, y: T) -> Self { 13 Point{x: x, y: y} 14 } 15 } 16 17 fn main() { 18 19 let point1 = Point::new(1, 2); 20 let point2 = Point::new("1", "2"); 21 assert_eq!(point1, Point{x: 1, y: 2}); 22 assert_eq!(point2, Point{x: "1", y: "2"}); 23 }
1 //标准库 Vec<T>源码 2 pub sturct Vec<T> { 3 buf: RawVec<T>, 4 len: usize, 5 }
Rust中的泛型属于静多态,它是一种编译期多态。
在编译期,不管是泛型枚举,还是泛型函数和泛型结构体,都会单态化(Monomorphization).单态化是编译器进行静态分发的一种策略。
单态化意味着编译器要将一个泛型函数生成两个具体类型对应的函数。
1 fn foo<T>(x: T) -> T { 2 x 3 } 4 5 fn foo_1(x: i32) -> i32 { 6 x 7 } 8 9 fn foo_2(x: &'static str) -> &'static str { 10 x 11 } 12 13 fn main() { 14 foo_1(1); 15 foo_2("2"); 16 }
泛型及单态化是Rust中两个重要的功能。单态化静态分发的好处就是性能好,没有运行时开销;缺点就是造成编译后生成的二进制文件膨胀。
如果变得太大,可以根据具体的情况重构代码来结解决问题。
泛型返回值自动推导 #
编译器可以对泛型进行自动推导。
1 #[derive(Debug, PartialEq)] 2 struct Foo(i32); 3 4 #[derive(Debug, PartialEq)] 5 struct Bar(i32, i32); 6 7 trait Inst { 8 fn new(i: i32) -> Self; 9 } 10 11 impl Inst for Foo 12 fn new(i: i32) -> Foo { 13 Foo(i) 14 } 15 } 16 17 impl Inst for Bar { 18 fn new(i: i32) -> Bar { 19 Bar(i, i + 10) 20 } 21 } 22 23 fn foobar<T: Inst>(i: i32) -> T { 24 T::new(i) 25 } 26 27 fn main() { 28 let f: Foo = foobar(10); //根据给定的类型自动去推导,这里给定的是Foo 29 //调用foobar函数,并指定其返回值的类型为Foo, Rust就会根据该类型自动推导出要调用Foo::new方法, 30 assert_eq!(f, Foo(10)); 31 let b: Bar = foobar(20); //给定的是Bar 32 //同理,指定返回值为Bar, 自动推导出要调用Bar::new方法 33 assert_eq!(b, Bar(20, 30)); 34 }
深入trait#
Rust中所有抽象,比如借口抽象,OOP范式抽象,函数式抽象等,均基于trait来完成的。同时,trait,也保证了这些抽象几乎都是没有运行时开销的。
什么是triat?
从类型系统的角度来说,trait是Rust对Ad-hoc多态的支持。
从语义上来说,trait是在行为上对类型的约束,这个约束可以让triat有如下4中用法:
- 接口抽象,接口是对类型行为的统一约束。
- 泛型约束,泛型的行为被triat限定在更有限的范围内,
- 抽象类型,在运行时作为一种间接的抽象类型去使用,动态分发给具体的类型。
- 标签triat,对类型的约束,可以直接作为一种“标签”使用。
接口抽象#
trait最基础的用法就是进行接口抽象,他有如下特点:
- 接口中可以定义方法, 并支持默认实现
- 接口中不能实现另一个接口,但是接口之间可以继承
- 同一个接口可以同时被多个类型实现,但是不能被同一个类型实现多次
- 使用impl关键字为类型实现接口方法。
- 使用trait关键字来定义接口
Ad-hoc多态,同一个triat,在不同的上下文中实现的行为不同。为不同的类型实现trait,属于一种函数重载,也可以说函数重载就是一种Ad-hoc多态。
关联类型#
Rust中很多操作符都是基于trait来实现的。比如加法操作就是一个trait,加法操作不仅可以针对整数、浮点数,也可以针对字符串。
如何抽象这个加法操作?
除了两个相加的值的类型,含有返回值类型,这三个类型不一定相同。首先想到的是结合泛型的triat
1 trait Add<RHS, Output> { // RHS代表加操作符右侧的类型, Output代表返回值的类型,在该trait内定义的add方法签名中,以slef为参数,代表实现该triat的类型 2 fn my_add(self, rhs: RHS) -> Output; 3 } 4 5 impl Add<i32, i32> for i32 { //为i32实现Add triat 6 //^ RHS, Output 7 fn my_add(self, rhs: i32> -> i32 { 8 self + rhs 9 } 10 } 11 12 impl Add<u32, i32> for u32 { //为u32实现Add triat 13 // ^ RHS, Output 14 fn my_add(self, rhs: u32) -> i32 { 15 (self + rhs) as i32 16 } 17 } 18 19 fn main() { 20 let (a, b, c, d) = (1i32, 2i32, 3u32, 4u32); 21 let x: i32 = a.my_add(b); 22 let y: i32 = c.my_add(d); 23 assert_eq!(x, 3i32); 24 assert_eq!(y, 7i32); 25 }
存在的问题是, 对于字符串来说有问题。
对于字符串来说,Rust中可以动态增加长度的只有String类型的字符串,所以一般是String类型才会实现Add,其返回值也必须是String类型。但是加法操作右侧可以是字符串字面量。针对这种情况,String的加法操作还必须实现Add<&str, String>
1 //标准库中的定义 2 pub trait Add<RHS=Self> { //(待加深理解) 3 type Ouput;//叫做关联类型 4 fn add(self, rhs: RHS) -> Self::Ouput; 5 }
Add<RHS=Self>这种形式表示为类型参数RHS指定了默认值Self,Self是每个trait都带有的隐式类型参数,代表实现当前trait的具体类型。
当代码中出现操作符“+”的时候,Rust就会自动调用操作符左侧的操作数对应的add()方法,去完成具体的加法操作,也就是说“+”操作与调用add()方法是等价的,
1 + 2 == 1.add(2)
1 //标准库中为u32实现Add triat 2 impl Add for $t { 3 type Output = $t; 4 fn add(self, other: $t) -> $t { 5 self + other 6 } 7 } 8 9 impl Add for u32 { 10 //这里实现Add triat时没有指明泛型参数的具体类型,则默认Self类型,也就是u32类型 11 //Add<RHS=Self>表示类型参数RHS指定了默认值Self,Self是每个trait都带有的隐式类型参数,代表实现当前trait的具体类型 12 type Output = u32; 13 fn add(self, other: u32) -> u32 { 14 self + other 15 } 16 } 17 //这里的关联类型是u32,因为两个u32整数相加结果必然还是u32整数。如果实现Add trait时未指明泛型参数的具体类型,则默认为Self类型,也就是u32类型。 18 19 //String类型的加号运算 20 impl Add<&str> for String { 21 //^RHS=&str ^ 为 String类型实现Add 22 type Output = String; 23 fn add(mut self, other: &str) -> String { 24 self.push_str(other); 25 self 26 } 27 } 28 //imple Add<&str> 指明了泛型类型&str,并没有使用Self默认类型参数,这表表明对于String类型字符串来说,加号右侧的值为&str类型,而非String类型。 29 //关联类型Output指定为String,意味着加法返回的是String类型。 30 fn main() { 31 let a = "hello"; // a 为 &str类型 32 let b = ", world"; // b 为 &str类型 33 let c = a.to_string() + b; // a 转换为String类型 34 println!("{:?}", c);// "hello, world" 35 }
使用关联类型能使代码变得更加简洁,同时也对方法的输入和输出进行了很好的隔离,使得代码的可读性大大增强。
在语义层面上,使用关联类型也增强了triat表示行为的这种语义,因为他表示了和某个行为trait相关联的类型。在工程上也体现了高内聚的特点。(待加深理解)
triat一致性 #
既然Add是trait,那么就可以通过impl Add的功能来实现操作符重载的功能。在Rust中,通过上面对Add trait的分析就可以知道,u32和u64类型是不能直接相加的。
1 use std::ops::Add; 2 impl Add<u64> for u32 { 3 type Output = u64; 4 fn add(self, other: u64) -> Self::Output { 5 (self as u64) + other 6 } 7 } 8 fn main() { 9 let a = 1u32; 10 let b = 2u64; 11 assert_eq!(a + b, 3); //Error, only traits defined in the current crate can be implemented for arbitrary types 12 }
孤儿原则: 如果要实现某个trait,那么该trait和要实现该trait的那个类型至少有一个要在当前crate中定义。
Add trait 和 u32,u64都不是在当前crate中定义的,而是定义在标准库中的。如果没有孤儿原则的限制,标准库中u32类型的加法行为就会被破坏性的改写,导致所有使用u32类型的crate可能产生难以预料的bug。
(这样这里的确是有问题的,一个u32的数加上一个u64后就变为了u64,要是换一个加u128,就变成了u128这样做很不符合实际)
要想通过编译,就需要将Add trait放到当前crate来定义。
1 trait Add<RHS=Self> { 2 type Output; 3 fn add (self, rhs: RHS) -> Self::Output; 4 } 5 impl Add<u64> for u32 { 6 type Output = u64; 7 fn add(self, other: u64) -> Self::Output { 8 (self as u64 ) + other 9 } 10 } 11 fn main() { 12 let a = 1u32; 13 let b = 2u64; 14 assert_eq!(a.add(b), 3);//注意在调用的时候要用add,而非操作符+,以避免被Rust识别为标准库中的add实现。 15 }
还可以在本地创建一个新的类型,然后对此类型实现Add, 这样同样不会违反孤儿原则。
1 use std::ops::Add; 2 #[derive(Debug)] 3 struct Point { 4 x: i32, 5 y: i32, 6 } 7 impl Add for Point { 8 type Output = Point; 9 fn add(self, other: Point) -> Point { 10 Point { 11 x: self.x + other.x, 12 y: self.y + other.y, 13 } 14 } 15 } 16 fn main() { 17 //Point { x: 3, y: 3} 18 println!("{:?}", Point{ x: 1, y: 0} + Point{ x: 2, y: 3}); 19 }
关联类型Output必须指定具体类型,函数add的返回类型可以写Point吗也可以写Self, 或者Self::Output.
trait继承#
Rust不支持面向对象的继承,但是支持trait继承。子trait可以继承父trait中定义或实现的方法。
在日常编程中,trait中定义的一些行为可能会有重复的情况,使用trait继承可以简化编程,方便组合,让代码更加优美。
以Web编程中的分页为例,来说明trait继承的一些应用场景
1 trait Page {// 代表当前页面的页码 2 fn set_page(&self, p: i32) { //设置当前页面页码,默认值设置为了第一页 3 println!("Page Default: 1"); 4 } 5 } 6 7 trait PerPage { // 每页显示的条目数 8 fn set_perpage(&self, num: i32) { //设置每页显示条目数,默认值设置为了显示10个条目 9 pritln!("per Page Default: 10"); 10 } 11 } 12 13 struct MyPaginate { page: i32 } 14 impl Page for MyPageinate{} 15 impl PerPage for MyPaginate {} 16 fn main() { 17 let my_paginate = MyPaginate{ page: 1}; 18 my_paginate.set_page(2); 19 my_paginate.set_perpage(100); 20 }
假如此时需要多加一个功能,要求可以设置直接跳转的页面页码,为了不影响之前的代码,可以使用trait继承来实现。
1 trait Paginate: Page + PerPage { // 冒号代表继承其他trait 2 fn set_skip_page(&self, num: i32){ 3 println!("Skip Page: {:?}", num); 4 } 5 } 6 imple <T: Page + PerPage> Paginate for T {} 7 //为所有拥有Page和PerPage行为的类型实现Pageinate
trait名后面的冒号代表trait继承,其后跟随继承的父trait名称,如果有多个trait则用加号相连。
1 fn main() { 2 let my_paginate = MyPaginate { page: 1}; 3 my_paginate.set_page(1); 4 my_paginate.set_perpage(100); 5 my_paginate.set_skip_page(12); 6 }
泛型约束#
使用泛型编程,在很多情况下的行为并不是针对所有类型都实现的
1 fn sum<T>(a: T, b: T) { 2 a + b 3 }
如果向代码sum函数中传入的参数的是两个整数,那么加法行为是合法的。如果传入的参数是两个字符串,理论上也应该是合法的,加法行为可以是字符串相连。
但是假如传入的两个参数是整数和字符串,或者整数和字符串,或者整数和布尔值,意义就不太明确了,有可能引起程序崩溃。
trait限定 #
只要两个参数是可相加的类型
1 use std::ops::Add; 2 fn sum<T: Add<T, Output=T>> (a: T, b: T) -> T { 3 //^ 使用<T: Add<T, Ouput=T>>对泛型进行了约束,表示sum函数的参数必须实现Add trait,并且加号两边的类型必须一致, 4 //对泛型约束的时候,Add<T, Output=T> 通过类型参数确定了关联类型Output是T, 也可以省略类型参数T, 直接写成Add<Output=T> 5 //这里的<T, Output=T>相当于在使用泛型类型时,必须先声明,这里就是使用T,先要声明T. 6 a + b 7 } 8 fn main() { 9 assert_eq!(sum(1u32, 2u32), 3); 10 assert_eq!(sum(1u64, 2u64), 3); 11 }
如果该sum函数传入两个String类型参数,就会报错.因为String字符相加时,右边的值必须是&str类型。所以不满足此sum函数中Add trait的约束。
使用trait对泛型进行约束,叫做trait限定(trait Bound).
1 fn generic<T: MyTrit + MyOtherTrait + SomeStandardTrait> (t: T) {}
理解trait限定
trait限定的思想和Java中的泛型限定、Ruby和Python中的Duck Typing, Golang中的Structural Typing, Elixir和Clojure中的Protocol都很相似。
在类型理论中,Structural Typing是一种根据结构来判断类型是否等价的理论,翻译过来为结构化类型。
Duck Typing、Protocol都是Structural Typing 的变种,一般用于动态语言,在运行时检测类型是否等价。
Rust中的trait限定也是Structral Typing的一种实现,可以看作一种静态Duck Typing.
从数学角度来理解trait限定。类型可以看作具有相同属性值的集合。当声明变量let x: u32, 意味着x 属于 u32, x属于u32集合。
1 trait Paginate: Page + PerPage
triat也是一种类型,是一种方法集合,或者说,是一种行为的集合。Paginate集合是Page 和 Perpage交集的子集。
Rust中冒号代表集合的“包含于”关系“, 而加号代表交集。
1 impl <T: A + B> C for T 2 // 所以这里表示的是C在T中,而T是属于A和B的交集中的一部分
Rust编程的哲学是组合优于继承,Rust并不提供类型层面上的继承,Rust中所有类型都是独立存在的,所以Rust中的类型可以看作语言允许的最小集合,不能再包含其他子集,而trait限定可以对这些类型集合进行组合,也就是求交集。
trait限定给予来开发者更大的自由度,因为不再需要类型间的继承,简化来编译器的检查操作,包含trait限定的泛型属于静态分发,在编译器通过单态化分别生成具体类型的实例,所以调用trait限定中的方法也都是运行时零成本的,因为不需要在运行时再进行方法查找。
1 fn foo<T, K, R> (a: T, b: K, c: R) 2 where T: A, K: B+C, R: D 3 {}
抽象类型#
trait还可以用作抽象类型 Abstract Type, 抽象类型属于类型系统的一种,也叫做存在类型(Existential Type).
相当于于具体类型而言,抽象类型无法直接实例化,它的每个实例都是具体类型的实例。
对于抽象类型而言,编译器可能无法确定其确切的功能和所占的空间大小,所以Rust目前有两种方法来处理抽象类型: Trait对象和impl trait.
triat对象#
在泛型中使用triat限定,可以将任意类型的范围根据类型的行为限定到更精确可控的范围内。
从这个角度出发,也可以将共同拥有相同行为的类型集合抽象为一个类型,也就是triat对象 trait Object.
“对象”这个词来自面向对象编程语言,因为trait对象是对具有相同行为的一组具体类型的抽象,等价于面向对象中的一个封装来行为的对象,所以称其为trait对象。
1 //trait限定和triat对象的用法比较 2 #[derive(Debug)] 3 struct Foo; 4 5 trait Bar { 6 fn baz(&self); 7 } 8 impl Bar for Foo { 9 fn baz(&self) { 10 println!("{:?}", self); 11 } 12 } 13 14 fn static dispatch<T>(t: &T) //静态分发,参数t之所以能调用baz方法,是因为Foo类型实现来Bar. 15 where T: Bar { //trait限定 16 t.baz(); 17 } 18 19 fn dynamic_dispatch(t: &Bar) { // trait object 20 t.baz(); // 动态分发,参数t标注的类型&Bar是trait对象 21 }//dynamic_dispatch(&foo)函数在运行期被调用时,会先查虚表,取出相应的方法t.baz(),然后调用。 22 23 fn main() { 24 let foo = Foo; 25 static_dispatch(&foo); 26 dynamic_dispatch(&foo); 27 }
什么是动态分发?它的工作机制是怎么样的呢?
trait本身也是一种类型,但它的类型大小在编译期是无法确定的,所以triat对象必须使用指针。
可以利用引用操作符&或Box<T>来制造一个trait对象。
1 //trait 对象结构体 2 pub struct TraitObject { 3 pub data: *mut (), 4 pub vtable: *mut (), 5 }
结构体TraitObject来自Rust标准库,但它不能代表真正的trait对象,它仅仅用于操作底层的一些Unsafe代码。
TriatObject包括两个指针: data指针和vtable指针。
以impl MyTrait for T 为例,
data指针指向trait对象保存的类型数据T,
vtable指针指向包含为T实现的MyTrait的Vtable(Virtual Table). 所以可以称为虚表。
虚表的本质上是一个结构体,包含了析构函数、大小、对齐和方法等信息。
在编译期,编译器只知道TraitObject包含指针信息,并且指针的大小也是确定的,并不知道要调用那个方法。
在运行期,当有trait_object.method()方法被调用时,TraitObject会根据虚表指针从虚表中查出正确的指针,然后再进行动态调用。这也是将trait对象称为动态分发的原因。
对象安全问题?(需要加深理解)
并不是每个trait都可以作为trait对象被使用,这依旧和类型大小是否确定有关系。
每个trait都包含一个隐式的类型参数Self,代表实现该triat的类型。
Self默认有一个隐式的trait限定?Sized, 形如<Self: ?Sized>, ?Sized trait 包括了所有的动态大小类型和所有可确定大小的类型。
Rust中大部分类型都默认是可确定大小的类型,也就是<T:Sized>,这也是泛型代码可以正常编译的原因。
当trait对象在运行期进行动态分发时,也必须确定大小,否则无法为其正确分配内存空间。
所以必须同时满足以下两条规则的triat才可以作为trait对象使用。
- trait的Self类型参数不能被限定为Sized。
- triat中所有的方法都必须是对象安全的。
满足这两条规则的trait就是对象安全的trait。
什么是对象安全呢?
trait的Self类型参数绝大部分情况默认是?Sized ,但也有可能出现被限定为Sized的情况。
1 trait Foo: Sized { 2 fn some_method(&self); 3 }
Foo继承Sized, 这表明,要为某类型实现Foo, 必须先实现Sized.所以, Foo中的隐式Self也必然是Sized,因为Self代表的是那些要实现Foo的类型。
按规则一, Foo不是对象安全的。Triat对象本身是动态分发的,编译期根本无法确定Self具体是那个类型,因为不知道给那些类型实现过该triat,更无法确定其大小,现在又要求Self是可确定大小的,这就造就了薛定谔的类型: 既能确定大小又不确定大小。
当把trait当作对象使用时,其内部类型就默认为Unsize类型,也就是动态大小类型,只是将其置于编译期可以确定的胖指针背后,以供运行时动态调用。
对象安全的本质就是为了让trait对象可以安全地调用相应的方法。
如果给trait加上Self:Sized限定,那么在动态调用trait对象的过程中,如果碰到了Unsize类型,在调用相应方法时,可能发生段错误。所以,就无法将其作为triat对象,反过来,当不希望trait作为triat对象时,可以使用Self: Sized进行限定。
对象安全的方法必须满足以下三点之一:
-
方法受Self:Sizd约束
-
方法签名同时满足以下三点。
- 必须不包含任何泛型参数。如果包含泛型,triat对象在虚表(Vtable)中查找方法时将不确定该调用那个方法。(需要例子)
- 第一个参数必须为Self类型或可以解引用为Self类型(也就是说,必须有接收者,比如selfm &self, &mut self和self: Box<Self>, 没有接受者的方法对trait对象来说毫无意义)
- Self不能出现在除了第一个参数之外的地方,包括返回值中。这是因为如果出现Self,那就意味着Self和self, &self或&mut self的类型相匹配。但是对于trait对象来说,根本无法做到保证类型匹配,因此,这种情况下的方法是对象不安全的。
没有额外Self类型参数的非泛型成员方法。
-
triat中不能包含关联常量Associated Constant, 在Rust2018中,trait中可以增加默认的关联常量,其定义方法和关联类型差不多,只不过需要使用const关键字。
1 // 标准对象安全的trait 2 trait Bar { 3 fn bax(self, x: u32); 4 fn bay(&self); 5 fn baz(&mut self); 6 } 7 // 这里有疑问------> trait Bar 不受Sized限定,trait方法是没有额外Self类型参数的非泛型成员方法。 8 // 上面给出的对象安全要求是方法受Self: Sized 约束。 ---》 和这里描述的不一致啊!!!!!! 9 //典型的对象不安全的trait 10 11 // 对象不安全的trait 12 trait Foo{ 13 fn bad<T>(&self, x: T); 14 fn new() -> Self; // Self出现在了返回值的位置,违反规则 15 } 16 17 //对象安全的trait, 将不安全的方法拆分出去 18 trait Foo { 19 fn bad<T>(&self, x: T); 20 } 21 22 trait Foo: Bar { //这个是对对象安全的吗?????🤔️ 23 fn new() -> Self; 24 } 25 26 //对象安全的trait, 使用where子句 27 triat Foo { 28 fn bad<T> (&self, x: T); 29 fn new() -> Self where Self: Sized; 30 //在new方法签名后面使用where子句,增加Self: Sized限定,则trait Foo 又成为一个对象安全的trait, 只不过在trait Foo 作为trait对象且有? Sized限定,不允许调用 31 //new方法 32 }
impl trait#
在rust 2018中,引入了可以静态分发的抽象类型impl trait. 如果说triat对象是装箱类型 Boxed Abstract Type, 那么impl Trait就是拆箱抽象类型(Unboxed Abstract Type).
“装箱”代表将值托管到堆内存,“拆箱”则是在栈内存中生成新的值。
装箱抽象类型代表动态分发,拆箱抽象类型代表静态分发。
目前impl Trait只可以在输入的参数和返回值这两个位置使用。
1 use std::fmt::Debug; 2 pub trait Fly { 3 fn fly(&self) -> bool; 4 } 5 #[derive(Debug)] 6 struct Duck; 7 #[derive(Debug)] 8 struct Pig; 9 impl Fly for Duck { 10 fn fly(&self) -> bool { 11 true 12 } 13 } 14 15 impl Fly for Pig { 16 fn fly(&self) -> bool { 17 false 18 } 19 } 20 21 fn fly_static(s: impl Fly+Debug) -> bool { 22 s.fly() 23 } 24 fn can_fly(s: impl Fly+Debug) -> impl Fly { // 将impl trait 语法用于参数位置的时候,等价于使用trait限定的泛型 25 //^ 将impl Trait 语法用于返回值位置的时候,实际上等价于给返回类型增加了一种trait限定范围 26 if s,fly() { 27 println!("{:?} can fly", s); 28 }else { 29 println!("{:?} can't fly", s); 30 } 31 s 32 } 33 34 let pig = Pig; 35 assert_eq!(fly_static(pig), false); 36 let duck = Duck; 37 assert_eq!(fly_static(duck),true); 38 let pig = Pig; 39 let pig = can_fly(pig); 40 let duck = Duck; 41 let duck = can_fly(duck);
在main函数中调用fly_static 函数的时候,也不再需要使用trubofish操作符来指定类型。
如果在Rust无法自动推导类型的情况下,还需要显式指定类型,只不过无法使用turbofish操作符。
调用can_fly函数可以返回impl Fly类型,属于静态分发,在调用的时候根据上下文确定返回的具体类型。
不能在let语句中为变量指定impl Fly类型,let duck : impl Fly = can_fly(duck); // Error
imple Trait只能用于为单个参数指定抽象类型,如果对多个参数使用impl Triat语法,编译器将报错。
use std::ops::Add; fn sum<T>(a: impl Add<Output=T>, b: impl Add<Output=T>) -> T { a + b } // a,b会被编译器认为是两个不同的类型,不能进行加法操作。
在Rust2018中,为来语义上和impl Trait语法相对应,专门为动态分发的trait对象增加了新的语法dyn Trait,其中dyn是Dynamic的缩写。
即, impl Trait 代表动态分发,dyn Trait代表动态分发。
1 fn dyn_can_fly(s: impl Fly+Debug+'staic) -> Box<dyn Fly> { 2 if s.fly() { 3 println!("{:?} can fly", s); 4 } else { 5 println!("{:?} can't fly", s); 6 } 7 Box::new(s) 8 } 9 //方法签名中出现的'static 是一种生命周期参数,它限定了impl Fly+Debug抽象类型不可能是引用类型,因为这里出现引用类型可能会引发内存不安全。
标签trait#
trait这种对行为约束的特性非常适合作为类型的标签。
Rust以供提供了5个重要标签trait,都被定义在标准库std::marker模块中。
- Sized trait ,用来标识编译期可确定大小的类型。
- Unsize trait,目前trait为实验特性,用于标识动态大小类型DST
- Copy trait,用来标识可以按位复制其值的类型
- Send trait, 用来标识可以跨线程安全通信的类型。
- Syn trait,用来标识可以在线程间安全共享引用的类型
Sized trait#
Sized trait, 编译器用它来识别可以在编译期确定大小的类型。
1 #[lang = "sized"] //这里是真正起“打标签”作用的代码 2 pub trait Sized {}
Sized trait是一个空trait,因为仅仅作为标签trait供编译器使用,#[lang = "sized"],该属性lang表示Sized trait供Rust语言本身使用,声明"sized", 称为语言项lang Item. 这样编译器就知道Sized trait如何定义了。类似的加号操作是语言项#[lang = "add"]
Rust语言大部分类型都是默认Sized的,所以在写泛型结构体程序的时候,没有显式地加上Sized trait限定。
1 struct Foo<T>(T); //-------> 默认等价于 struct Foo<T: Sized>(T); 2 struct Bar<T: ?Sized>(T); // 这里相当于指定使用动态大小类型 ---> 这里的限定为 <T: ?Sized> 3 // ^ Bar<T: ?Sized> 支持编译期可确定大小类型和动态大小类型两种类型
Foo是一个泛型结构体,等价于Foo<T:Sized>, 如果需要在结构体中使用动态大小类型,则需要改为<T:?Sized> 限定。
?Sized 是Sized trait的另一种语法, ?Sized 标示的类型包含了:
- Sized ,标示的是编译期可确定大小的类型
- Unsize , 标示的是动态大小类型,在编译期无法确定其大小类型,其中必须满足以下三条使用规则。
- 只可以通过胖指针来操作Unsize类型,比如&[T]或&Trait
- 变量、参数和枚举变量不能使用动态大小类型
- 结构体中只有最后一个字段可以使用动态大小类型,其他字段不可以使用
目前Rust中的动态类型有trait和[T],
其中[T] 代表一定数量的T在内存中一次排列,但不知道具体的数量,所以它的大小是未知的,用Unsized来标记。比如str字符串和定长数组[T:N].
[T]其实就是[T;N]的特例,当N的大小未知时就是[T]
Copy trait #
Copy trait用来标记可以按位复制其值的类型,按位复制等价于C语言中的memcpy.
1 #[lang = "copy"] 2 pub trait Copy : Clone {}
Copy trait 继承自Clone trait, 意味着,要实现Copy trait的类型,必须实现Clone trait中定义的方法。
1 // Clone trait 源码 2 pub trait Clone: Sized { //意味这要实现Clone trait 的对象必须是Sized类型 3 fn clone(&self) -> Self; 4 fn clone_from(&mut self, source: &self) { 5 *self = source.clone() //默认调用clone方法 6 } 7 //所以对于要实现Clone trait的对象,只需要实现clone 方法就可以了。 8 }
如果让一个类型实现Copy trait, 就必须同时实现Clone trait.
1 struct MyStruct; 2 impl Copy for MyStruct{} 3 impl Clone for MyStrcut { 4 fn clone(&self) -> MyStruct { 5 *self 6 } 7 } 8 9 // 等价于 10 #[derive(Copy, Clone)] 11 struct MyStruct;
Rust为很多基本数据类型都实现了Copy trait, 比如常用的数字类型,字符,布尔类型,单元值、不可变引用等。
1 //检测乐行是都实现Copy trait 2 fn test_copy<T: Copy> (i: T) { // Copy 是一个标签Trait,编译器做类型检查时会检测类型所带有的标签,以检验它是否“合格” 3 pritln!("hh"); 4 } 5 6 fn main() { 7 let a = "String".to_string(); // ---> String类型,没有实现Copy triat 8 test_copy(a); 9 }
Copy 的行为是一个隐式的行为,开发者不能重载Copy 行为,它永远都是一个简单的位复制。
Copy隐式行为发生在执行变量绑定,函数参数传递,函数返回等场景中,因此这些场景是开发者无法控制的,所以需要编译器来保证。
Clone trait是一个显式的行为,任何类型都可以实现Clone trait,开发者可以自由地按需实现Copy 行为, 比如String类型并没有实现Copy trait,但是它实现了Clone trait,如果代码里有需要,只需要String类型的clone方法即可。
但是需要注意的是,如果一个类型是Copy的,它的clone方法仅仅需要返回*self即可。
并非所有类型都可以实现Copy trait.
对于自定义类型来说,必须让所有的成员都实现了Copy trait,这个类型才有资格实现Copy trait。
如果是数组类型,且其内部元素都是Copy类型,则数组本身就是Copy类型;
如果是元组类型,且其内部元素都是Copy类型,则该元组会自动实现Copy;
如果是结构体或枚举体,只有当每个内部成员都实现Copy时,它才可以实现Copy,并不会像元组那样自动实现Copy.
Send trait && Sync trait #
Rust 作为现代编程语言,提供了语言级的并发支持。 Rust在标准库中提供了很多并发相关的基础设施,比如线程, Channel,锁,和Arc等,这些都是独立于语言核心之外的库,意味着基于Rust的并发方案不受标准库和语言的限制,开发人员可以编写自己所需的并发模型。
系统级的线程是不可控的,编写好的代码不一定会按预期的顺序执行,会带来竞争条件。
不同的线程同时访问一块共享变量也会造成数据竞争。
竞争条件是不可能被消除的,数据竞争是有可能被消除的,而数据竞争是线程安全最大的“隐患”。
Erlang提供轻量级进程和Actor并发模型;
Golang提供了协程和CSP并发模型
Rust从正面解决这个问题,通过类型系统和所有权机制。
Rust提供了Send 和 Sync两个标签trait,它们是Rust无数据竞争并发的基石。
- 实现Send的类型,可以安全地在线程间传递值,也就是说可以跨线程传递所有权。
- 实现Sync的类型,可以跨线程安全地传递共享(不可变)引用
Rust中所有的类型归为两类: 可以安全线程传递的值和引用,以及不可以跨线程传递的值和引用。
在配合所有权机制,Rust能够在编译期就检查出数据竞争的隐患,而不需要等到运行时再排查。
1 //多线程之间共享不可变变量 2 use std::thread; 3 fn main() { 4 let x = vec![1, 2, 3, 4]; 5 thread::spawn(|| x); // 使用标准库thread模块中的spawn函数来创建自线程,需要一个闭包作为参数。 6 // 变量x被闭包捕获,传递到子线程中,但x默认不可变,所以多线程之间共享是安全的。 7 } 8 //多线程之间共享可变变量 9 use std::thread; 10 fn main() { 11 let mut x = vec![1, 2, 3, 4]; 12 thread::spawn (|| { 13 x.push(1); 14 }); 15 x.push(3); 16 }
这里闭包中的x实际为借用,Rust无法确定本地变量x可以比闭包中x存活得更久,假如本地变量x被释放了,闭包中的x借用就成了悬垂指针,造成内存不安全。
编译器建议在闭包前面使用move关键字来转移所有权,转移了所有权意味着x变量只可以在子线程中访问,而父线程再无法操作变量x,这就阻止了数据竞争。
1 //在多线程之间move可变变量 2 use std::thread; 3 fn main() { 4 let mut x = vec![1, 2, 3, 4]; 5 thread::spawn(move || x .push(1)); 6 // x.push(2); //这里会报错 7 }
这里之所以可以正常move变量,是因为数组x中的元素均为原生数据类型,默认都实现了Send和Sync 标签trait,所以它们跨线程传递和访问都是安全的。在x被转移到子线程之后,就不允许父线程对x进行修改。
1 //在多线程之间传递没有实现Send和Sync的类型 2 use std::thread; 3 use std::rc:Rc; 4 fn main() { 5 let x = Rc::new(vec![1, 2, 3, 4]); 6 thread::spawn(move || { 7 x[1]; 8 }); 9 }
使用std::rc::Rc容器来包装数组,Rc没有实现Send和Sync,所以不能在线程之间传递变量x。
因为Rc是用于引用计数的智能指针,如果把Rc类型的变量x传递到另一个线程中,会导致不同线程的Rc变量引用同一块数据,Rc内部实现并没有做任何线程同步的处理,因此这样做必然不是线程安全的。
Send和Sync也是标签trait。可以安全地跨线程传递和访问的类型用Send和Sync标记,否则用!Send和!Sync标记。
1 #[lang = "send"]
2 pub unsafe trait Send {}
3
4 #[lang = "sync"]
5 pub unsafe triat Sync {}
6 //Rust 为所有类型实现Send 和 Sync
7 unsafe impl Send for .. {} //for .. 表示为所有类型实现Send, Sync同理
8 impl <T: ?Sized> !Send for * const T {} //对原生类型实现!Send,代表它们不是线程安全的类型,将他们排除出去
9 impl <T: ?Sized> !Send for * mut T {} //
对于自定义的数据类型,如果其成员类型必须全部实现Send和Sync,此类型才会被自动实现Send和Sync。Rust也提供来类似Copy和Clone那样的derive属性来自动导入Send和Sync的实现。但是不建议开发者使用该属性,因为它可能引起编译器检查不到的线程安全问题。
类型转换#
在编程语言中,类型转换分为隐式类型转换 implicit type conversion 和显式类型转换 explicit type conversion。
隐式类型转换是由编译器或解释器来完成的,开发者并未参与,所有又称强制类型转换 type Coercion. 显式类型转换是由开发者指定的,就是一般意义上的类型转换。
Deref 解引用 #
Rust中的隐式类型转换基本上只有自动解引用。自动解引用的目的主要是方便开发者使用智能指针。
Rust中提供的Box<T>, Rc<T>, 和String等类型,实际上是一种智能指针,它们的行为就像指针一样,通过“解引用“操作符进行解引用,来获取其内部的值进行操作。
自动解引用 #
自动解引用虽然是编译器来做的,但是自动解引用的行为可以由开发者来定义。
一般来说,引用使用&操作符,而解引用使用*操作符。
可以通过实现Deref trait 来自定义解引用操作。Deref有一个特性是强制隐式转换,规则是这样的: 如果一个类型T实现了Deref<Target=U>, 则该类型T的引用(或者智能指针)在应用的时候会被自动转换为类型U。
1 pub trait Deref { 2 type Target: ?Sized; 3 fn deref(&self) -> &Self::Target; 4 } 5 6 pub trait DerefMut : Derf { 7 fn deref_mut(&mut self) -> &mut Self:;Target; 8 }
DerefMut和Deref类似,只不过他是返回可变引用。Deref中包含关联类型Target它表示解引用之后的目标类型。
1 //String 类型实现了Deref, 2 fn main() { 3 let a = "hello".to_string(); 4 let b = " world".to_string(); 5 let c = a + &b; // &b : &String ---> String类型实现add方法的右值参数必须是&str类型, 这里String类型实现了Deref<Target=str> 6 println!("{:?}", c);// "hello world" 7 //String实现Deref<Target=str> 8 impl ops::Deref for String { 9 type Target = str; 10 fn deref(&self) -> &str { 11 unsafe { str::from_utf8_unchecked(&self.vec) } 12 } 13 }
标准库中常用的其他类型都实现了Deref,比如Vec<T>, Box<T>, Rc<T>, Arc<T>。实现Deref的目的只有一个,就是简化编程
1 fn foo(s: &[i32] ) { 2 println!("{:?}", s[0]); 3 } 4 fn main() { 5 let v = vec![1, 2, 3]; // type : Vec<T> 6 foo(&v);// 传入类型&Vec<i32> ---> Vec<T> 实现了Deref<Target=[T]>, 所以&Vec<T>会被自动转换为&[T]类型 7 } 8 //Rc指针实现Deref 9 fn main() { 10 let x = Rc::new("hello"); 11 println!("{:?}", c.chars()); 12 }
手动解引用#
有时就算实现了Deref ,编译器也不会自动解引用。
当某类型和其解引用目标类型中包含了相同的方法,编译器就不知道该用哪一个了,此时就需要手动解引用
1 use std::rc::Rc; 2 fn main() { 3 let x = Rc::new("hello"); 4 let y = x.clone(); // Rc<&str> 5 let z = (*x).clone(); // &str 6 //clone 方法在Rc和&str类型中都实现了,所以调用时会直接调用Rc的clone方法,如果想调用Rc里面&str类型的clone方法,则需要使用"解引用'操作符 7 }
8 //match 引用也需要手动解引用 9 fn main() { 10 use std::ops::Deref; 11 use std::borrow::Borrow; 12 let x = "hello".to_string(); 13 match &x { // ----> &x ==> &*x, &x[..], x.deref(), x.borrow() 14 "hello" => { println!("hello"); }, 15 _ => {} 16 } 17 }
- match x.deref(),直接调用deref方法,需要use std::ops::Deref
- match x.as_ref(), String类型提供了as_ref 方法来返回一个&str,该方法定义于AsRef trait中
- match x.borrow(), 方法borrow定义于Borrow trait中,行为和AsRef类型一样,需要use std::borrow::Borrow
- match &*x, 使用"解引用:操作符,将String转换为str,然后再用“引用”操作符转为&str.
- match &x[..] ,这是因为String类型的index操作可以返回&str类型。
as 操作符 #
as操作符最常用的场景就是转换Rust中的基本数据类型,需要注意的是,as关键字不支持重载。
1 fn main() { 2 let a = 1u32; 3 let b = a as u64; 4 let c = 3u64; 5 let d = c as u32; 6 }
注意的是, 短类型转换为长类型的时候是没有问题的,但是如果反过来,则会被截断处理。
1 fn main() { 2 let a = std::u32::MAX; // 3 let b = a as u16; 4 assert_eq!(b, 65535); 5 let e = -1i32; 6 let f = e as u32; 7 println!("{:?}", e.abs()); //1 8 println!("{:?}", f); // 9 }
无歧义完全限定语法 #
为结构体实现多个trait时,可能会出现同名的方法。
1 strcuct S(i32); 2 trait A { 3 fn test(&self, i: i32); 4 } 5 trait B { 6 fn test(&self, i: i32); 7 } 8 impl A for S { 9 fn test(&self, i: i32) { 10 println!("From A: {:?}", i); 11 } 12 } 13 impl B for S { 14 fn test(&self, i: i32) { 15 println!("From B: {:?}", i + 1); 16 } 17 } 18 19 fn main() { 20 le s = S(1); 21 A::test(&s, 1); 22 B::test(&s, 1); 23 <S as A>::test(&s, 1); 24 <S as B>::test(&s, 1); 25 }
结构体S实现了A和B两个trait, 虽然包含了同名的方法test, 但是行为不同,有两种方式调用可以避免歧义。
- 直接当作trait的静态函数来调用,A::test(), B::test().
- 使用as操作符, <S as A>::test()或<S as B>::test()
这两种叫作无歧义完全限定语法Full Qualified Syntax for Disambiguation, 也叫做通用函数调用语法UFCS
类型和子类型相互转换
as转换可以用于类型和子类型之间的转换。Rust中没有标准定义的自类型,比如结构体继承之类,但是生命周期可看作类型。
比如&'static str 类型是&'a str类型的子类型,因为两者的生命周期标记不同,'a 和'static都是生命周期标记。其中'a 是泛型标记,是&str的通用形式,
而'static 则是特指静态生命周期的&str字符串,通过as 操作符转换可以将&'static str类型转为&'a str类型
1 fn main() { 2 let a : &'static str = "hello"; // &'static str 3 let b: &str = a as &str; // &str 4 let c: &'static str = b as &'static str; // &'static str 5 }
From 和 Into#
From 和 Into 是定义于std::convert模块中的两个trait。它们定了from和into两个方法,这两个方法互为反操作。
1 pub trait From<T> {
2 fn from(T) -> Self;
3 }
4 pub trait Into<T> {
5 fn into(self) -> T;
6 }
7 fn main() {
8 let string = "hello".to_string();
9 let other_string = String::from("hello"); // 根据trait From中的fn from(T),
10 assert_eq!(string, other_string);
11 }
对于类型T, 如果它实现了Into<U>, 则可以通过into方法来消耗自身转换为类型U的实例
1 #[derive(Debug)] 2 struct Person{ name: String } 3 impl Person { 4 fn new<T: Into<String>>(name: T) -> Person { //new方法是一个泛型方法,它允许传入参数是&str,String类型 5 //使用了<T: Into<String>> 限定就意味着,实现了into方法的类型都可以作为参数 6 //&str, String类型都实现了Into。当参数是&str类型时,会通过into转换为String类型,当参数是String类型,则什么都不会发生 7 Person { name: name.into() } 8 } 9 } 10 fn main() { 11 let person = Person::new("Alex"); 12 let person = Person::new("Alex".to_string()); 13 println!("{:?}", person); 14 }
如果类型U实现了From<T>,则类型实例调用into方法就可以转换为类型U.
这是因为Rust标准库内部有一个默认的实现。
1 //为所有实现了From<T> 的类型实现Into<U> 2 impl <T, U> Into<U> for T where U: From<T> 3 fn main() { 4 let a = "hello"; 5 let b : String = a.into(); 6 }
String类型实现了From<&str>, 所以可以使用into方法将&str转换为String。
一般情况下,只需要实现From即可,除非From不容易实现,才需要考虑实现Into.
在标准库中,还包含了TryFrom和TryInto两种trait,是From和Into的错误处理版本,因为类型转换是有可能发生错误的,所以需要进行错误处理的时候可以使用TryFrom和TryInto。不过TryFrom和TryInto目前还是实现特性
标准库中还有AsRef和AsMut两个trait,可以将值分别转换为不可变引用和可变引用。AsRef和标准库中的另一个Borrow trait功能有些类似,但是AsRef比较轻量级,他只是简单地将值转换为引用,而Borrow trait可以用来将某个复合类型抽象为拥有借用语义的类型。
当前trait系统的不足#
主要有以下三点:
孤儿规则的局限性。
- 代码复用的效率不高
- 抽象表达能力有待改进
孤儿规则的局限性#
在设计trait时,还需要考虑是否会影响下游的使用者,比如在标准库实现一些triat时,还需要考虑是否需要为所有的T或&'a T实现该trait
1 impl <T: Foo> Bar for T {} 2 impl <'a, T: Bar> Bar for &'a T {}
对于下游的子crate来说,如果想要避免孤儿规则的影响,还必须使用NewType模式或者其他方式将远程类型包装为本地类型。这就带来了很多不便。
对于一些本地类型,如果将其放到一些容器中,比如Rc<T>, Option<T>这些本地类型就会变成远程类型,因为这些容器类型都在标准库中定义的,而非本地。
1 use std::ops::Add; 2 #[derive(partialEq)] 3 struct Int(i32); //本地类型 4 impl Add<i32> for Int { //为本地类型实现Add trait,不违背孤儿原则 5 type Output = i32; 6 fn add(self, other: i32) -> Self::Output { 7 (self.0) + other 8 } 9 } 10 11 // impl Add<i32> for Option<Int> { //违背孤儿原则 12 // //TODO 13 //} 14 impl Add<i32> for Box<Int> { //正常编译 15 type Output = i32; 16 fn add(self, other: i32) -> Self::Output { 17 (self.0) + other 18 } 19 } 20 fn main() { 21 assert_eq!(Int(3) + 3, 6); 22 assert_eq!(Box::new(Int(3)) + 3, 6); 23 }
这是因为Box<T> 在Rust中属于最常用的类型,经常会遇到, 从子crate为Box<Int>这种自定义类型扩展trait实现.标准库中根本做不到覆盖所有的crate中的可能性,所以必须将Box<T>开放出来,脱离孤儿规则的限制,否则就会限制子crate要实现的一些功能。
1 #[fundamental] // 该属性的作用就是告诉编译器,Box<T>享有特权,不必遵守孤儿规则 2 pub struct Box<T: ?Sized> (Unique<T>);
除了Box<T>, Fn, FnMut, FnOnce, Sized等都加上了#[fundamental]属性,代表这些trait也同样不受孤儿规则的限制。
代码复用的效率不高#
Rust还遵守: 重叠规则, 该规则规定了不能为重叠的类型实现同一个triat
impl <T> AnyTrait for T {} //T 是泛型,指代所有的类型 impl <T> AnyTrait for T where T: Copy {} // T where T: Copy 是受trait限定约束的泛型T, 指代实现了Copy的一部分T, 是所有类型的子集 impl <T> AnyTrait for i32 {} // i32是一个具体类型
T包含了T: Copy, 而T: Copy 包含了i32, 这违反了重叠规则,所以编译会失败。这种实现trait的方式在Rust中叫作覆盖式实现
重叠规则和孤儿规则一样,都是保证triat一致性,避免发生混乱,但是他也带来了一些问题:
- 性能问题
- 代码很难重用
1 impl <R, T: Add<R> + Clone> AddAssign<R> for T { 2 fn add_assign(&mut self, rhs: R) { 3 let tmp = self.clone() + rhs; 4 *self = temp; 5 } 6 }
为所有类型T实现Addsign, 该trait定义的add_sign方法是+= 赋值操作对应的方法。这样做虽然好,但是会带来性能问题,因为会强制所有类型都使用clone方法,clone方法会有一定的成本开销,但是实际上有的类型并不需要clone.因为有重叠规则的限制。不能为某些不需要clone的具体类型重新实现Add_assign方法,所以在标准库中,为了实现更好的性能,只好为每个具体的类型都各自实现一遍AddAssign.
重叠规则严重影响了代码的复用,如果没有重叠规则,则可以默认使用上面对泛型T的实现,然后对不需要clone的类型重新实现AddAssign,那么就完全没必要为每个具体类型都实现一遍add_assign方法,可以省去很多重复代码,
为了缓解重叠规则带来的问题,Rust引入了特化,特化功能暂时只能用于impl实现,所以也称为impl特化。
1 #[feature(specialization)] 2 struct Diver<T> { 3 inner: T, 4 } 5 trait Swimmer { 6 fn swim(&self) { 7 println!("swimming") 8 } 9 } 10 11 impl <T> Swimmer for Diver<T> {} 12 impl Swimmer for Diver<&'static str> { 13 fn swim(&self) { 14 println!("drowning, help!") 15 } 16 } 17 fn main() { 18 let x = Diver::<&'static str> { inner: "Bob" }; //使用了Diver::<&'static str>使用了本身swim方法实现 19 s.swim(); // drowning, help! 20 let y = Diver::<String> { inner: String::from("Alice") }; //使用了Diver::<T>中的实现 21 y.swim(); // swimming 22 } 23 //trait 中的方法默认实现 24 trait Swimmer { 25 fn swim(&self); 26 } 27 28 impl <T> Swimmer for Diver<T> {
29 default fn swim(&self) { //如果不加default, 编译会报错,这是因为默认impl块中的方法不可被特化, 30 //必须使用default来标记那个需要被特化的方法,这是出于代码的兼容性考虑的 31 //使用default标记,也增强来代码的维护性和可读性 32 println!("swimming") 33 } 34 }
抽象表达能力有待改进#
迭代器在Rust中应用广泛,但是它目前有一个缺陷:在迭代元素的时候,只能按值进行迭代,有的时候必须重新分配数据,而不能通过引用来复用原始的数据。
比如标准库中的std::io::Lines类型用于按行读取文件数据,但是该实现迭代器只能读一行数据分配一个新的String,而不能重用内部缓存区。这样就影响了性能
这是因为迭代器的实现基于关联类型,而关联类型目前只能支持具体的类型,而不能支持泛型。不能支持泛型,就导致无法支持引用类型,因为Rust里规定使用引用类型必须标明生命周期参数,而生命周期参数恰恰是一种泛型类型参数。
为了解决问题,就必须允许迭代器支持引用类型,只有支持引用类型,才可以重用内部缓冲区,而不需要重新分配新的内存,所以就必须实现一种更高级别的类型多态性,即泛型关联类型(Generic Associated, GAT),
1 trait StreamingIterator { 2 type Item<'a>; // 'a 是一种泛型类型参数,叫作生命周期参数,表示这里可以使用引用 3 fn next<'a> ('a mut self) -> Option<Self::Item<'a>>; 4 }
这样,如果给std::io::Lines实现StreamingIterator迭代器,他就可以复用内部缓存区,而不需要为每行数据新开辟一份内存,因而提升了性能。
Item<'a>是一种类型构造器,就像Vec<T>类型,只有在为其指定具体的类型之后才算真正的类型,Vec<i32>. GAT也被称为ACT(Associated type constructor) 即关联类型构造器。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!