
实时数据融合之法,稳定高容错

陈雷 | DataPipeline 合伙人 & CPO
曾任 IBM 大中华区认知物联网实验室服务部首席数据科学家、资深顾问经理。十年管理经验,十五年数据科学领域与金融领域经验。综合交通大数据应用技术国家工程实验室产业创新部主任,西安交通大学软件学院大数据智能创新中心主任,中国电子学会区块链专委会委员。
上周我们发布了“实时数据融合之道,博观约取,价值驱动”,文章提到实时数据既要全面覆盖能被利用的各类数据,也要基于价值分清先后顺序;既要高效释放数据价值,也要选好抓手、切入点。而触客业务因为直接与收入相关,无疑成为实时数据最好的切入点。也正因为其重要性和敏感性,所以大家更为关注实时数据融合过程中的稳定高容错。
不管是绝地求生还是企业级系统,稳定输出都是最重要的。
上下游不稳定时,你得稳定
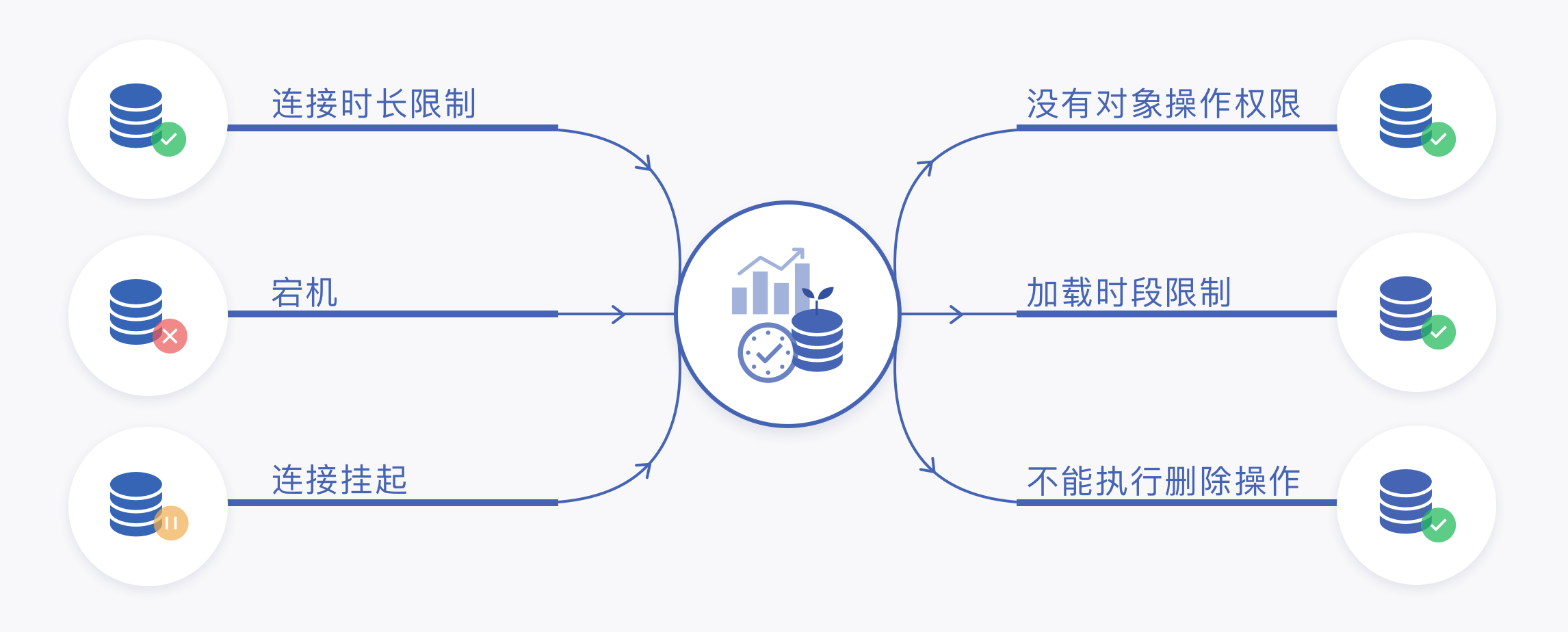
实时数据在获取与加载过程中,上下游节点一般都是注册机制而不是纳管机制,系统很难实时感知到上下游节点的实际状态和发生的问题,在实际企业环境中,实时数据融合的上下游节点往往在业务连续性和服务级别上高于实时数据融合系统,因此,实时数据的处理需要遵循上下游节点的管理机制,例如认证方式、安全加密方式、连接时长、最大连接数,甚至于日志模式也需要你来适应,更不用说上下游节点可不止一种类型,在充分调研准备和依赖管理机制之外,需要实时数据融合具备足够的策略配置与容错机制来应对上下游系统不稳定带来的不确定性,从而保证自身的稳定性。
结构不稳定时,你得稳定
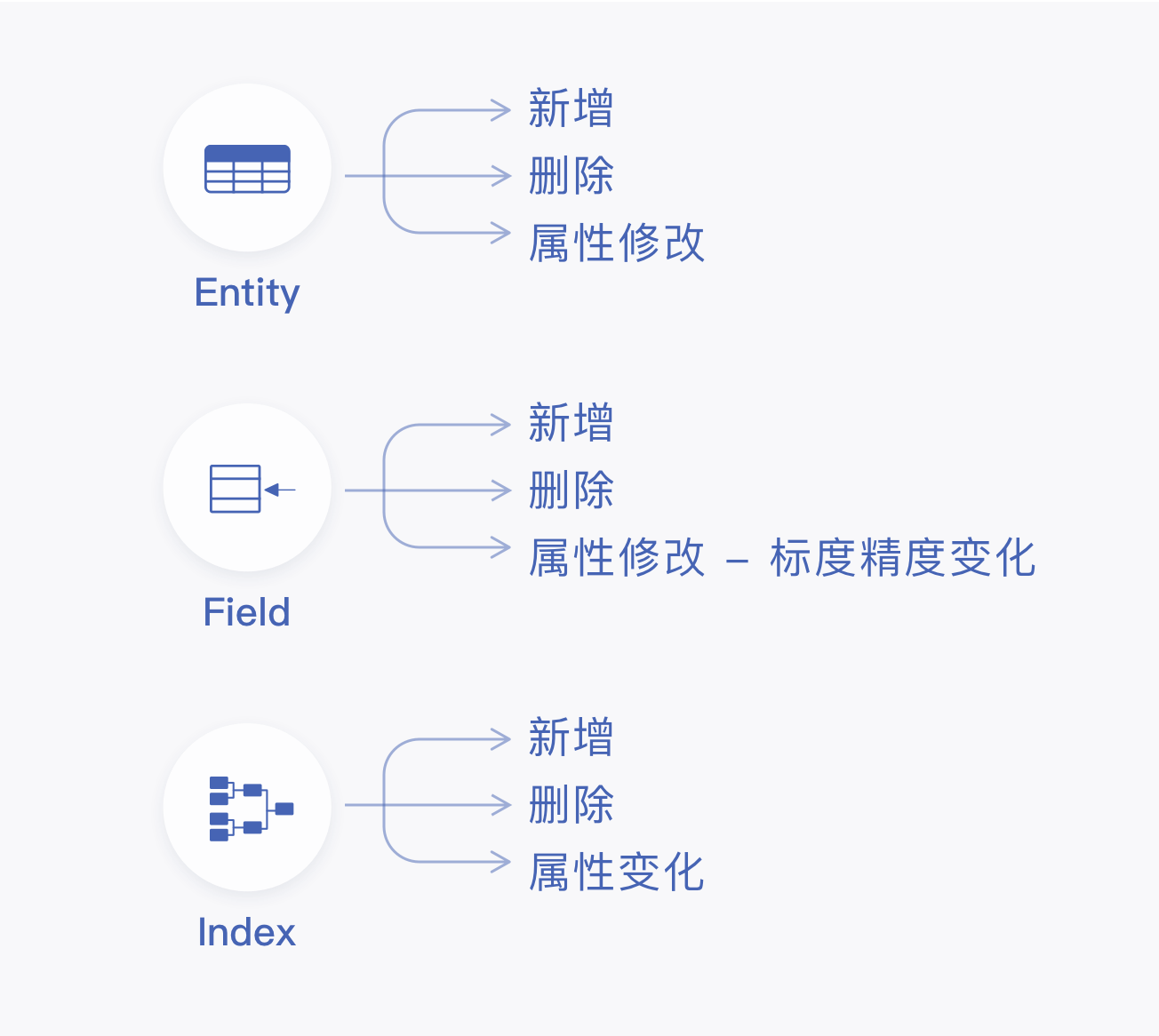
上下游节点咱们稳住之后,你就需要考虑节点内部对象不稳定的问题了,也就是所谓的DDL问题,原因同上,可能在一些信息化水平较高的企业中,任何的数据结构调整需要首先在数据管控平台进行影响分析,通知所有下游系统联调测试后统一上线切换,可这毕竟是别人家的孩子,到了自己家,还有各种各样的原因会出现。上游系统结构变化是在你意想不到的时候出现的,而下游系统嗷嗷待哺,定责分锅那是后面的事,先得保证业务不能停,因此就要求实时数据处理需要能够提供完善的结构变化应对策略,而针对不同的数据节点类型和增量获取机制,结构变化的感知方式也不尽相同,有的简单高效,有的成本极高,这又需要实时数据融合能够按照不同的场景进行取舍与配置,从而保证自身的稳定性。
流量不稳定时,你得稳定
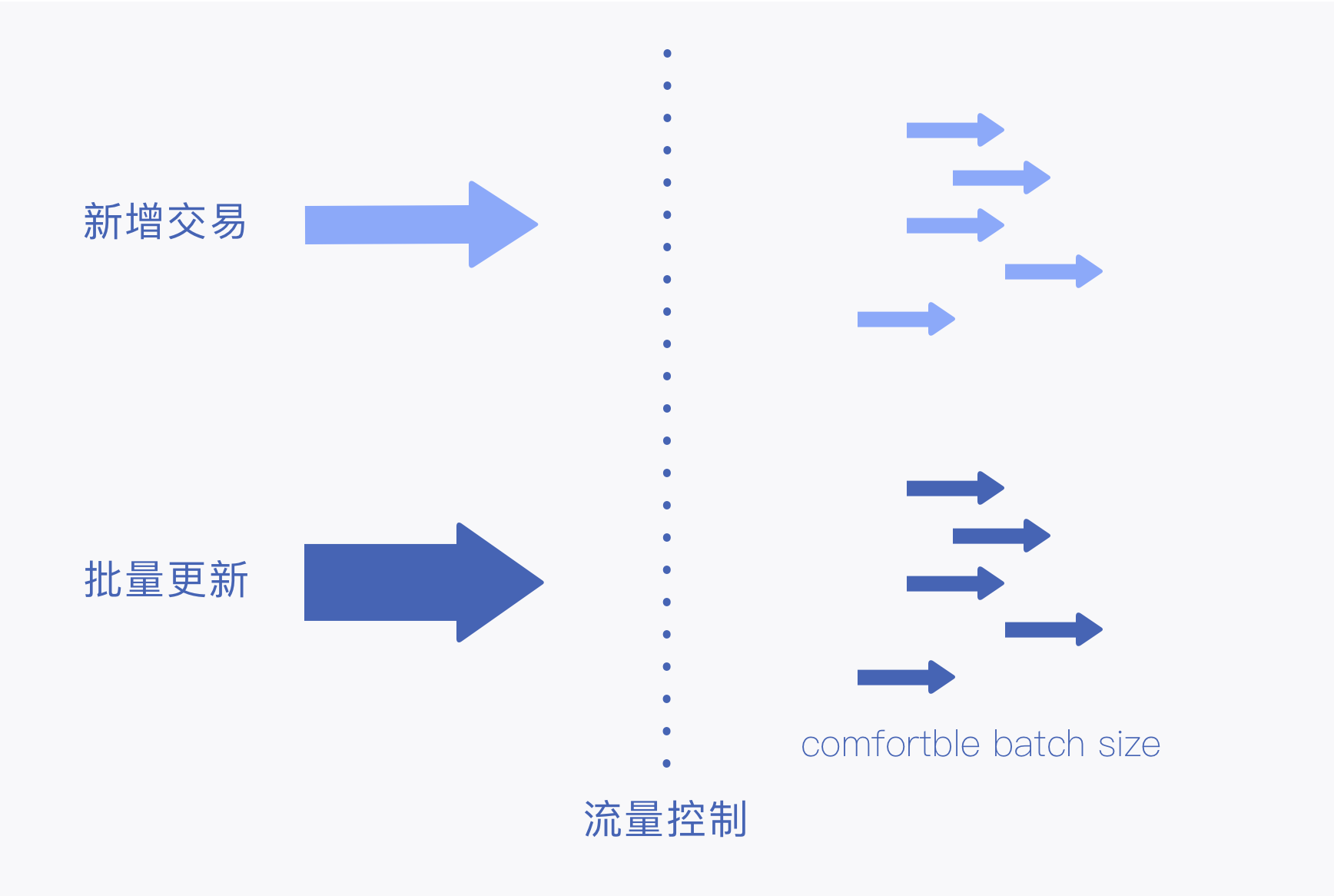
一开始处理实时数据时,我们往往把实时数据与交易数据,行为数据等时序数据挂钩,而在实际企业环境中,往往会出现部分系统某些情况下大面积更新操作,上游增量会突然增大,平时他安静得像山间的小溪,一转脸它变成了壶口的黄河,所以实时数据的流量往往和上游应用系统、数据模型、数据管理机制的设计有关,而不能仅仅基于交易量进行评估,在精确的容量评估与资源准备之外,还需要考虑资源的利用率和成本问题,因此就要求实时数据融合拥有强大的反压处理机制和灵活的读取、写入限制配置,可以通过控制读取速率、并行度、批次大小的方式,实现增量数据反压的处理,从而保证自身的稳定性。
环境不稳定时,你得稳定
一般来说,企业级环境中网络、存储、计算设备的稳定性还是可以保证的,但我敢保证,就像每个谢顶的程序员都有那么几个加班的夜晚一样,每个运维工程师都能讲几个系统莫名其妙出问题又莫名其妙就恢复了的灵异故事,因此就要求实时数据处理能够提供预设策略在无计划的网络不可用、出现未知异常等情况下进行重新连接,重置线程乃至重启任务等自动化操作,从而保证自身的稳定性。
——好稳呀,不过领导,这么多配置,这得搞多长时间呀?
——时间?时间是没有的。咱们什么时候有过时间?所以你再往下看。
下一期我们将从配置便捷、部署便捷、分层管理、按需服务四个方面详谈“实时数据融合之法,便捷可管理”,请大家持续关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号