
21世纪最性感的数据科学家,原来只是一群沮丧的天气预报员
《哈佛商业评论》在2012年的一篇文章中,将数据科学家称为“21世纪最性感的工作”,而性感意味着具有非常需要的稀有品质。通常情况下,招聘这些人既困难又昂贵,而且由于他们服务的市场竞争非常激烈,所以难以保留。
截至2019年1月,在线求职网站确实发布了一份报告,显示数据科学家的需求同比增长29%,自2013年以来增长344%。
原本是件很美好的事情,但现实很骨感。在2019年伦敦Gartner数据与分析峰会上,Gartner分析师Nick Heudecker却表示:“数据科学家只是让我想起了一群沮丧的天气预报员。”为什么会出现如此大的落差,是什么导致了这种情况?
一、前期的数据收集、准备
数据科学家对数据的分析方法可以为企业提供有价值的洞察力以驱动业务决策。但实际情况是,他们几乎花费了一半的时间来为那些无法投入生产的项目准备数据。
根据Gartner的数据,数据科学家花费47%的时间用于数据收集,准备和问题分析,而不是开发模型。为此数据科学团队陷入了困境,因为他们当初选择来公司并不是被用来解决这些问题的。这就导致了一些项目的失败和人员的高流失率。
站在十字路口,如何才能扭转这种困境呢?这时一位数据分析师和数据科学家之间的混合体——数据工程师,出现了。

二、什么是数据工程师,你了解他们吗
DataPipeline CEO陈诚提到:“在和国内外顶尖公司交流的过程中,我发现他们多数都很骄傲能拥有一支极其专业的数据团队。这些公司花费了大量的时间和精力把数据工程这件事情做到了极致。这些规模不小的工程师团队,开源了大量数据技术,如Linkedin有Kafka, Samza, Facebook有Hive, Presto, Airbnb有Airflow, Superset,我所熟悉的Yelp也有MRJob…… 这些公司在数据领域的精益求精,为后来的大步前进奠定了基石。”
Gordon Lindsay Glegg曾用一个非常形象的例子阐释了数据工程师的重要性:“科学家可以发现一颗新星,但他不能制造一颗。他不得不让工程师为他做这件事。”关于这个岗位:Netflix是一个典型。当Netflix想要弄清楚如何将数据作为公司内部的一流资产时,他们将数据工程的概念提升为一个独立的学科。并创建了一个由高级数据工程师组成的卓越中心,发挥着承上启下的枢纽作用。
就上游而言,他们经常跟业务系统的人打交道,需要对业务系统比较熟悉。比如它们存在哪些接口,不管是API级别还是数据库接口。就下游来说,他们要跟许多数据分析师、数据科学家打交道,通常负责管理数据工作流,管道和ETL过程。将准备好的数据(数据的清洗、整理、融合),交给下游的数据分析师和数据科学家。
当然这还不是他们的全部,下面就带你走进他们(以ETL数据工程师为例)。
带你走进数据工程师(ETL数据工程师)
1. 首先是数据的获取
这类似于巧妇难为无米之炊,想要发挥数据价值的前提是要获取数据。
为了实现这个目的,就需要工程师对收集的数据如数家珍。最好能有一个数据目录将这些业务系统中的数据整理清楚,比如它们在哪,都有什么意义等。这时,一旦别人需要从数据工程师这里获取所需要的数据,他们能很快地定位到。
为什么建议这么做?在小公司时效果还不明显,如果在大公司可能有几十、数百个系统,每个系统中存有几十,甚至上千张表。这时理解这些系统和任务其实是一个非常复杂的工作。
当然仅做到上面还不够,还需要构建好的工具和方法提取这些数据。这中间还有许多维度,比如上游系统的侵入性是不是很高,它能给你何种权限等。另外,还需要考虑这些数据能否丢失,数据的语义需要什么保障,传输的准确性有什么要求。
相当于数据工程师需要有自己的工具箱,能清楚地知道对于不同维度的要求可以分别使用哪个工具,针对不同情况能变换相应的策略和方法。
2. 关于数据采集和数据清洗
关于数据采集基本有这三种途径:埋点、从数据库/文件系统抽取、通过API拿数。对于这三种数据工程师都要能有相应的应对措施,高效地完成。
下一步大概率会去做数据清洗,目前有两种情况:一种是将数据放到一个统一的ODS平台,先拉数据再做清洗。另一种是一边传输一边清洗。针对这两种情况工程师要非常明白,为达到数据目标应该采取何种措施。
这其中会有一些偏好或取舍,需要在存储空间、执行效率之间找到平衡。针对这点可以看:DataPipeline CTO陈肃:从ETL到ELT,AI时代数据集成的问题与解决方案
3. 关于实时和批量在此也有所影响
目前批流一体是当下的一个发展趋势,即在统一平台中管理各种任务,解决多个平台的运维难题。这要求工程师需要熟悉许多工具,以流式的计算框架为例,有Kafka Streams, Spark(Streaming), Flink等。
4. 最后是数据的存储
数据存储分为几级,有ODS层、数仓层、数据集市层,再往上是AI层、BI层。关于数据存储也有很多学问,比如,在入库时需要考虑上游源系统与下游的目标系统可能是不同的(结构互异的存储)。
企业该如何看待数据工程这件事
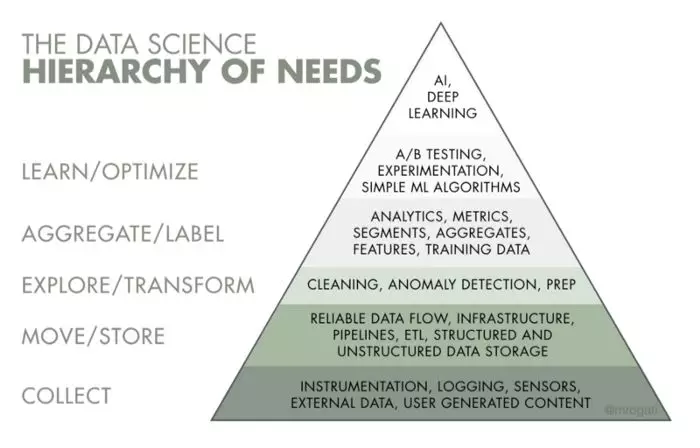
数据工程之于企业的意义,如同马斯洛需求理论之于人的意义(从低到高进阶满足)。所以,企业对于数据工程的应用应该遵循三角原则:
第一层,企业要注意到在公司发展过程中,最普世最基础的需求:即让数据可见可得。重视数据工程这件事,是企业做大做强安身立命的根本;
第二层,进阶需求。在具备数据意识且招来数据工程师之后,企业就需要开始从语义(semantic)的角度去理解跑起来的数据流了。实现从数据到企业战略指导再回到数据;
第三层,是目前看起来最接近塔尖也是最高级的需求:即建模、更完善的预测性算法、更漂亮的数据可视化、深度学习、AI 等等……
从沮丧的天气预报员到性感科学家,中间有多远
从一群沮丧的天气预报员到21世纪最性感的数据科学家,这中间的距离有多远?其实并不远,但却举步维艰。
如果说数据工程师是构建数据管道的管道工,那数据科学家则是画家和故事讲述者。简而言之,数据工程师需要在前期进行清理,准备和优化数据以供消费。所以减少数据管道的人为错误成分非常重要。
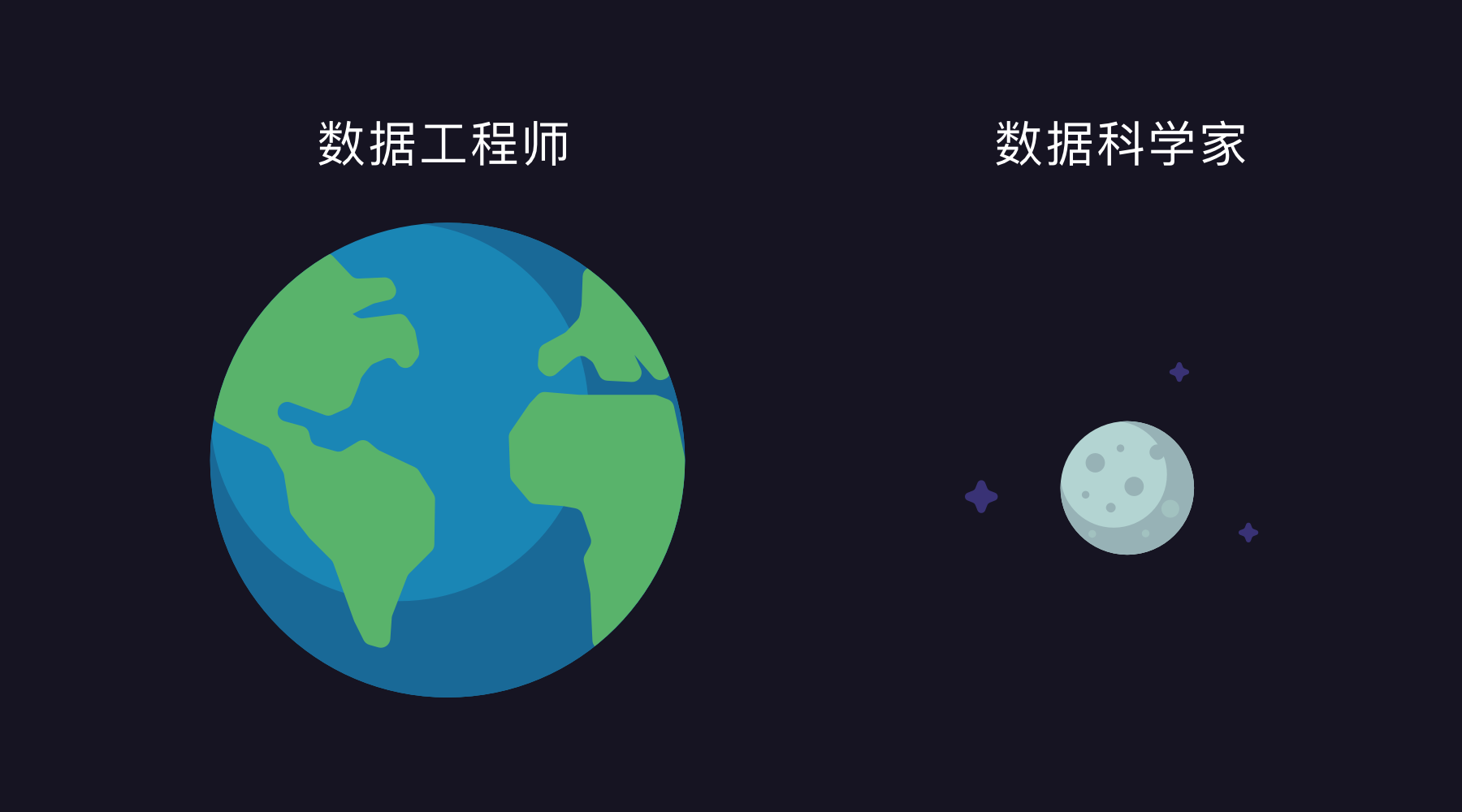
只有这样,数据科学家才能基于此执行各种分析和可视化技术来真正理解数据,并最终从数据中讲述故事。
参考资料:
"How to Become a Data Engineer in 2019" BY Masters in data science
"Who Is a Data Engineer & How to Become a Data Engineer?"作者 / Oleksii Kharkovyna
·End·
DataPipeline作为一家为企业提供批流一体的数据融合服务提供商,帮助数据工程师更敏捷、高效地实现复杂异构数据源到目的地数据融合和数据资产管理等综合服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号