Spark:The Definitive Book第八章笔记
Join Expressions
A join brings together two sets of data, the left and the right, by comparing the value of one or more keys of the left and right and evaluating the result of a join expression that determines whether Spark should bring together the left set of data with the right set of data. The most common join expression, an equi-join, compares whether the specified keys in your left and right datasets are equal. If they are equal, Spark will combine the left and right datasets.
Join Types
the join type determines what should be in the result set. There are a variety of different join types available in Spark for you to use:
- Inner joins (keep rows with keys that exist in the left and right datasets)
- Outer joins (keep rows with keys in either the left or right datasets)
- Left outer joins (keep rows with keys in the left dataset)
- Right outer joins (keep rows with keys in the right dataset)
- Left semi joins (keep the rows in the left, and only the left, dataset where the key appears in the right dataset) ?:
- Left anti joins (keep the rows in the left, and only the left, dataset where they do not appear in the right dataset) ?:
- Natural joins (perform a join by implicitly matching the columns between the two datasets with the same names) ?:
- Cross (or Cartesian) joins (match every row in the left dataset with every row in the right dataset)
// in Scala
val person = Seq(
(0, "Bill Chambers", 0, Seq(100)),
(1, "Matei Zaharia", 1, Seq(500, 250, 100)),
(2, "Michael Armbrust", 1, Seq(250, 100)))
.toDF("id", "name", "graduate_program", "spark_status")
val graduateProgram = Seq(
(0, "Masters", "School of Information", "UC Berkeley"),
(2, "Masters", "EECS", "UC Berkeley"),
(1, "Ph.D.", "EECS", "UC Berkeley"))
.toDF("id", "degree", "department", "school")
val sparkStatus = Seq(
(500, "Vice President"),
(250, "PMC Member"),
(100, "Contributor"))
.toDF("id", "status")
person.createOrReplaceTempView("person")
graduateProgram.createOrReplaceTempView("graduateProgram")
sparkStatus.createOrReplaceTempView("sparkStatus")
Inner Joins
Inner joins are the default join, so we just need to specify our left DataFrame and join the right in the JOIN expression:
// in Scala
val joinExpression = person.col("graduate_program") === graduateProgram.col("id")
val wrongJoinExpression = person.col("name") === graduateProgram.col("school")
person.join(graduateProgram, joinExpression).show()
We can also specify this explicitly by passing in a third parameter, the joinType:
// in Scala
var joinType = "inner"
person.join(graduateProgram, joinExpression, joinType).show()
Outer Joins
joinType = "outer"
person.join(graduateProgram, joinExpression, joinType).show()
Left Outer Joins
joinType = "left_outer"
graduateProgram.join(person, joinExpression, joinType).show()
Right Outer Joins
joinType = "right_outer"
person.join(graduateProgram, joinExpression, joinType).show()
Left Semi Joins
Semi joins are a bit of a departure from the other joins. They do not actually include any values from the right DataFrame. They only compare values to see if the value exists in the second DataFrame. If the value does exist, those rows will be kept in the result, even if there are duplicate keys in the left DataFrame. Think of left semi joins as filters on a DataFrame, as opposed to the function of a conventional join:
joinType = "left_semi"
graduateProgram.join(person, joinExpression, joinType).show()
Left Anti Joins
Left anti joins are the opposite of left semi joins. Like left semi joins, they do not actually include any values from the right DataFrame. They only compare values to see if the value exists in the second DataFrame. However, rather than keeping the values that exist in the second DataFrame, they keep only the values that do not have a corresponding key in the second DataFrame. Think of anti joins as a NOT IN SQL-style filter:
joinType = "left_anti"
graduateProgram.join(person, joinExpression, joinType).show()
Natural Join
Natural joins make implicit guesses at the columns on which you would like to join. It finds matching columns and returns the results. Left, right, and outer natural joins are all supported.
警告:Implicit is always dangerous! The following query will give us incorrect results because the two DataFrames/tables share a column name (id), but it means different things in the datasets. You should always use this join with caution. SELECT * FROM graduateProgram NATURAL JOIN person
Cross (Cartesian) Joins
Cross-joins in simplest terms are inner joins that do not specify a predicate. Cross joins will join every single row in the left DataFrame to ever single row in the right DataFrame. This will cause an absolute explosion in the number of rows contained in the resulting DataFrame.
For this reason, you must very explicitly state that you want a cross-join by using the cross join keyword:
不正确
joinType = "cross"
graduateProgram.join(person, joinExpression, joinType).show()
正确
graduateProgram.crossJoin(person).count()
警告:You should use cross-joins only if you are absolutely, 100 percent sure that this is the join you need. There is a reason why you need to be explicit when defining a cross-join in Spark. They’re dangerous! Advanced users can set the session-level configuration spark.sql.crossJoin.enable to true in order to allow cross-joins without warnings or without Spark trying to perform another join for you.
Challenges When Using Joins
Joins on Complex Types
Any expression is a valid join expression, assuming that it returns a Boolean:
import org.apache.spark.sql.functions.expr
person.withColumnRenamed("id", "personId")
.join(sparkStatus, expr("array_contains(spark_status, id)")).show()
Handling Duplicate Column Names
One of the tricky things that come up in joins is dealing with duplicate column names in your results DataFrame. In a DataFrame, each column has a unique ID within Spark’s SQL Engine, Catalyst. This unique ID is purely internal and not something that you can directly reference. This makes it quite difficult to refer to a specific column when you have a DataFrame with duplicate column names.
This can occur in two distinct situations:
- The join expression that you specify does not remove one key from one of the input DataFrames and the keys have the same column name
- Two columns on which you are not performing the join have the same name
val gradProgramDupe = graduateProgram.withColumnRenamed("id", "graduate_program")
val joinExpr = gradProgramDupe.col("graduate_program") === person.col(
"graduate_program")
person.join(gradProgramDupe, joinExpr).show()
person.join(gradProgramDupe, joinExpr).select("graduate_program").show()
+---+----------------+----------------+---------------+----------------+-------+--------------------+-----------+
| id| name|graduate_program| spark_status|graduate_program| degree| department| school|
+---+----------------+----------------+---------------+----------------+-------+--------------------+-----------+
| 0| Bill Chambers| 0| [100]| 0|Masters|School of Informa...|UC Berkeley|
| 2|Michael Armbrust| 1| [250, 100]| 1| Ph.D.| EECS|UC Berkeley|
| 1| Matei Zaharia| 1|[500, 250, 100]| 1| Ph.D.| EECS|UC Berkeley|
+---+----------------+----------------+---------------+----------------+-------+--------------------+-----------+
Out[13]:
Name: org.apache.spark.sql.AnalysisException
Message: Reference 'graduate_program' is ambiguous, could be: graduate_program, graduate_program.;
StackTrace: at org.apache.spark.sql.catalyst.expressions.package$AttributeSeq.resolve(package.scala:259)
Approach 1: Different join expression
When you have two keys that have the same name, probably the easiest fix is to change the join expression from a Boolean expression to a string or sequence. This automatically removes one of the columns for you during the join:
val gradProgramDupe = graduateProgram.withColumnRenamed("id", "graduate_program")
person.join(gradProgramDupe,"graduate_program").select("graduate_program").show()
Approach 2: Dropping the column after the join
Another approach is to drop the offending column after the join. When doing this, we need to refer to the column via the original source DataFrame. We can do this if the join uses the same key names or if the source DataFrames have columns that simply have the same name:
person.join(gradProgramDupe, joinExpr).drop(person.col("graduate_program"))
.select("graduate_program").show()
val joinExpr = person.col("graduate_program") === graduateProgram.col("id")
person.join(graduateProgram, joinExpr).drop(graduateProgram.col("id")).show()
This is an artifact of Spark’s SQL analysis process in which an explicitly referenced column will pass analysis because Spark has no need to resolve the column. Notice how the column uses the .col method instead of a column function. That allows us to implicitly specify that column by its specific ID.
Approach 3: Renaming a column before the join
How Spark Performs Joins
To understand how Spark performs joins, you need to understand the two core resources at play: the node-to-node communication strategy and per node computation strategy.
Communication Strategies
Spark approaches cluster communication in two different ways during joins. It either incurs a shuffle join, which results in an all-to-all communication or a broadcast join.
The core foundation of our simplified view of joins is that in Spark you will have either a big table or a small table. Although this is obviously a spectrum (and things do happen differently if you have a “medium-sized table”), it can help to be binary about the distinction for the sake of this explanation.
- Big table–to–big table
When you join a big table to another big table, you end up with a shuffle join, such as that illustrates
![]()
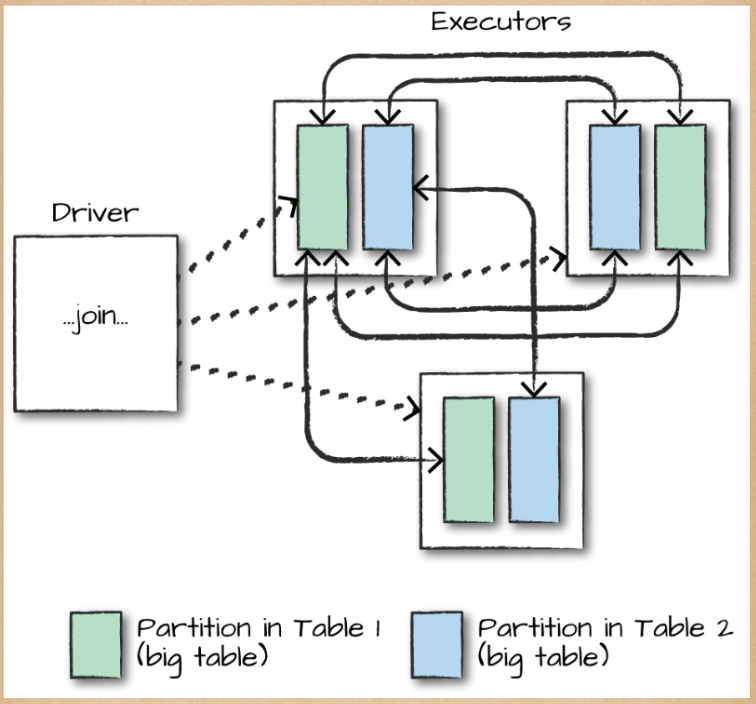
In a shuffle join, every node talks to every other node and they share data according to which node has a certain key or set of keys (on which you are joining). These joins are expensive because the network can become congested with traffic, especially if your data is not partitioned well.
This means that all worker nodes (and potentially every partition) will need to communicate with one another during the entire join process (with no intelligent partitioning of data).
- Big table–to–small table
When the table is small enough to fit into the memory of a single worker node, with some breathing room of course, we can optimize our join. Although we can use a big table–to–big table communication strategy, it can often be more efficient to use a broadcast join. What this means is that we will replicate our small DataFrame onto every worker node in the cluster (be it located on one machine or many). Now this sounds expensive. However, what this does is prevent us from performing the all-to-all communication during the entire join process. Instead, we perform it only once at the beginning and then let each individual worker node perform the work without having to wait or communicate with any other worker node, as is depicted in
![]()
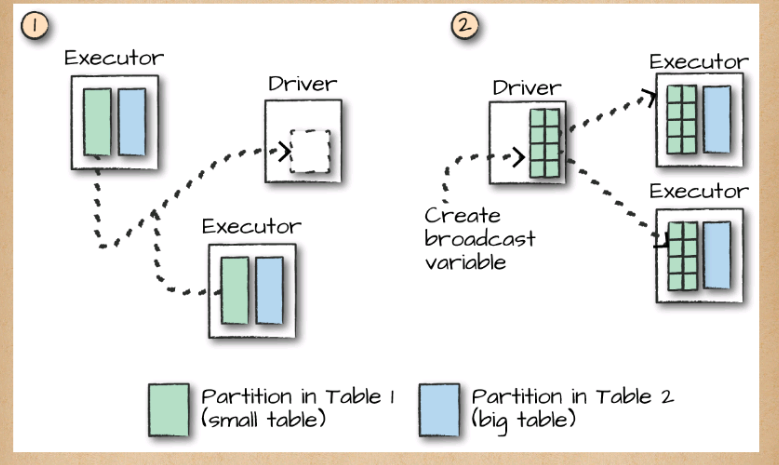
At the beginning of this join will be a large communication, just like in the previous type of join. However, immediately after that first, there will be no further communication between nodes. This means that joins will be performed on every single node individually, making CPU the biggest bottleneck.
For our current set of data, we can see that Spark has automatically set this up as a broadcast join by looking at the explain plan:
val joinExpr = person.col("graduate_program") === graduateProgram.col("id")
person.join(graduateProgram, joinExpr).explain()
With the DataFrame API, we can also explicitly give the optimizer a hint that we would like to use a broadcast join by using the correct function around the small DataFrame in question. In this example, these result in the same plan we just saw; however, this is not always the case:
import org.apache.spark.sql.functions.broadcast
val joinExpr = person.col("graduate_program") === graduateProgram.col("id")
person.join(broadcast(graduateProgram), joinExpr).explain()
The SQL interface also includes the ability to provide hints to perform joins. These are not enforced, however, so the optimizer might choose to ignore them. You can set one of these hints by using a special comment syntax. MAPJOIN, BROADCAST, and BROADCASTJOIN all do the same thing and are all supported
-- in SQL
SELECT /*+ MAPJOIN(graduateProgram) */ * FROM person JOIN graduateProgram
ON person.graduate_program = graduateProgram.id
This doesn’t come for free either: if you try to broadcast something too large, you can crash your driver node (because that collect is expensive).
- Little table–to–little table
When performing joins with small tables, it’s usually best to let Spark decide how to join them. You can always force a broadcast join if you’re noticing strange behavior
Conclusion
One thing we did not mention but is important to consider is if you partition your data correctly prior to a join, you can end up with much more efficient execution because even if a shuffle is planned, if data from two different DataFrames is already located on the same machine, Spark can avoid the shuffle. In Chapter 9, we will discuss Spark’s data source APIs. There are additional implications when you decide what order joins should occur in. Because some joins act as filters, this can be a low-hanging improvement in your workloads, as you are guaranteed to reduce data exchanged over the network.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号