
风控算法赛lgb实战-拍拍贷魔镜杯
写在开头,关注公众号:Python风控模型与数据分析、回复 风控实战1 ,即可获取本文数据集及完整代码,以及更多理论知识与代码分享
目录
1、导包
import warnings
warnings.filterwarnings('ignore')
import re
import os
import pandas as pd
import numpy as np
import toad
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import lightgbm as lgb
import matplotlib.pyplot as plt
import gc
from sklearn.model_selection import cross_val_predict,cross_validate
from bayes_opt import BayesianOptimization2、数据读取
原始数据3w条样本,含id、target标签、申请时间在内共228列,其中特征225列,包含UserInfo、WeblogInfo、ThirdParty_Info_Period、SocialNetwork四类
data=pd.read_csv('train.csv',encoding='gbk')
print(data.shape)
data.head()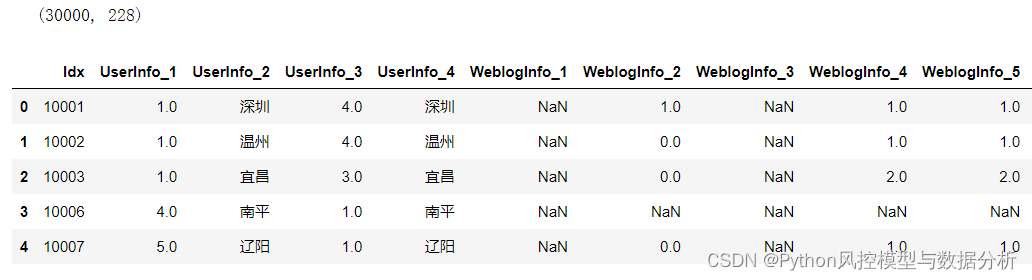
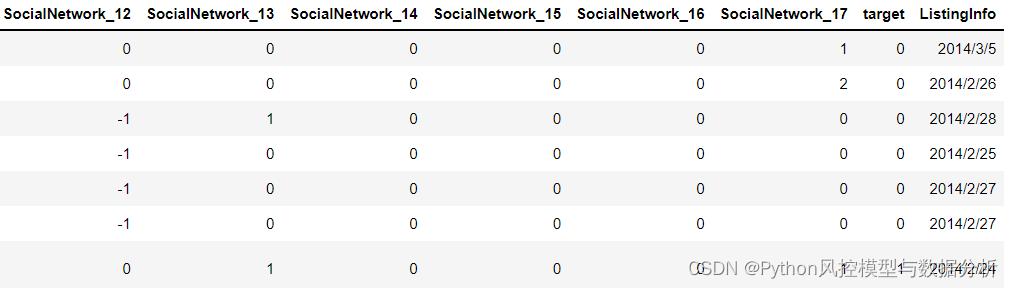
3、统计分析
3.1 样本分布
(1)查看样本的总体分布情况、不同月份的分布情况
总体分布来看,3w的样本量中好样本27802条、坏样本2198条,bad_rate仅有7.3%,存在较为严重的数据不均衡问题;
月度分布来看,2014年02月之前样本量很少、平均每月样本量不足1000,之后样本量逐渐提高、在2014年10月达到5000条;同时bad_rate也非常不稳定,整体随着样本量增加 、bad_rate反而下降,最低点在2014年9月逾期率 5.2%、最高点2013年12月逾期率11.3%,相差一倍
df['ListingInfo']=pd.to_datetime(df['ListingInfo'],format='%Y-%m-%d') # 将申请时间转化为正常的日期格式
def sample_mon_distribution(df,time_name,y_name):
df_copy=df[[time_name,y_name]].copy() # 减少内存占用、优化运行速度
df_copy['appl_mon']=pd.to_datetime(df_copy[time_name],format='%Y-%m-%d').astype('str').str[0:7]
mon_list=sorted(df_copy['appl_mon'].unique())
result=[]
all_cnt={
'y_label':y_name,
'mon':'all',
'count':df_copy[df_copy[y_name].isin([0,1])].shape[0],
'good':df_copy[df_copy[y_name]==0].shape[0],
'bad':df_copy[df_copy[y_name]==1].shape[0],
'bad_rate':round(df_copy[df_copy[y_name]==1].shape[0]/df_copy[df_copy[y_name].isin([0,1])].shape[0],3),
}
result.append(all_cnt)
for mon in mon_list:
df_mon=df_copy[df_copy['appl_mon']==mon][[y_name]]
mon_cnt={
'y_label':y_name,
'mon':mon,
'count':df_mon[df_mon[y_name].isin([0,1])].shape[0],
'good':df_mon[df_mon[y_name]==0].shape[0],
'bad':df_mon[df_mon[y_name]==1].shape[0],
'bad_rate':round(df_mon[df_mon[y_name]==1].shape[0]/df_mon[df_mon[y_name].isin([0,1])].shape[0],3),
}
result.append(mon_cnt)
return pd.DataFrame(result)
df_mon_distribution=sample_mon_distribution(df,'ListingInfo',y_name='target')
df_mon_distribution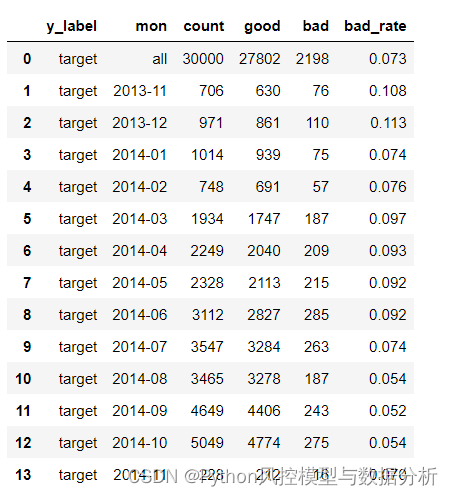
(2)样本月度分布图
import pyecharts.options as opts
from pyecharts.charts import Bar, Line
def bad_rate_curve(x_data,y_data_bar,y_data_line):
bar = (
Bar(init_opts=opts.InitOpts(width="1000px", height="600px"))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
"样本量",
mon_cnt,
label_opts=opts.LabelOpts(is_show=False),
)
.extend_axis(
yaxis=opts.AxisOpts(
name="bad_rate",
type_="value",
axislabel_opts=opts.LabelOpts(formatter="{value} "),
)
)
.set_global_opts(
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(rotate=25),
type_="category",
axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"),
),
yaxis_opts=opts.AxisOpts(
name="样本量",
type_="value",
axislabel_opts=opts.LabelOpts(formatter="{value}"),
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
line = (
Line()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="bad_rate",
yaxis_index=1,
y_axis=bad_rate,
label_opts=opts.LabelOpts(is_show=False),
)
)
return bar.overlap(line)
x_data = list(df_mon_distribution[df_mon_distribution.mon!='all']['mon'])
mon_cnt = list(df_mon_distribution[df_mon_distribution.mon!='all']['count'])
bad_rate = list(df_mon_distribution[df_mon_distribution.mon!='all']['bad_rate'])
bad_rate_curve(x_data,mon_cnt,bad_rate).render_notebook()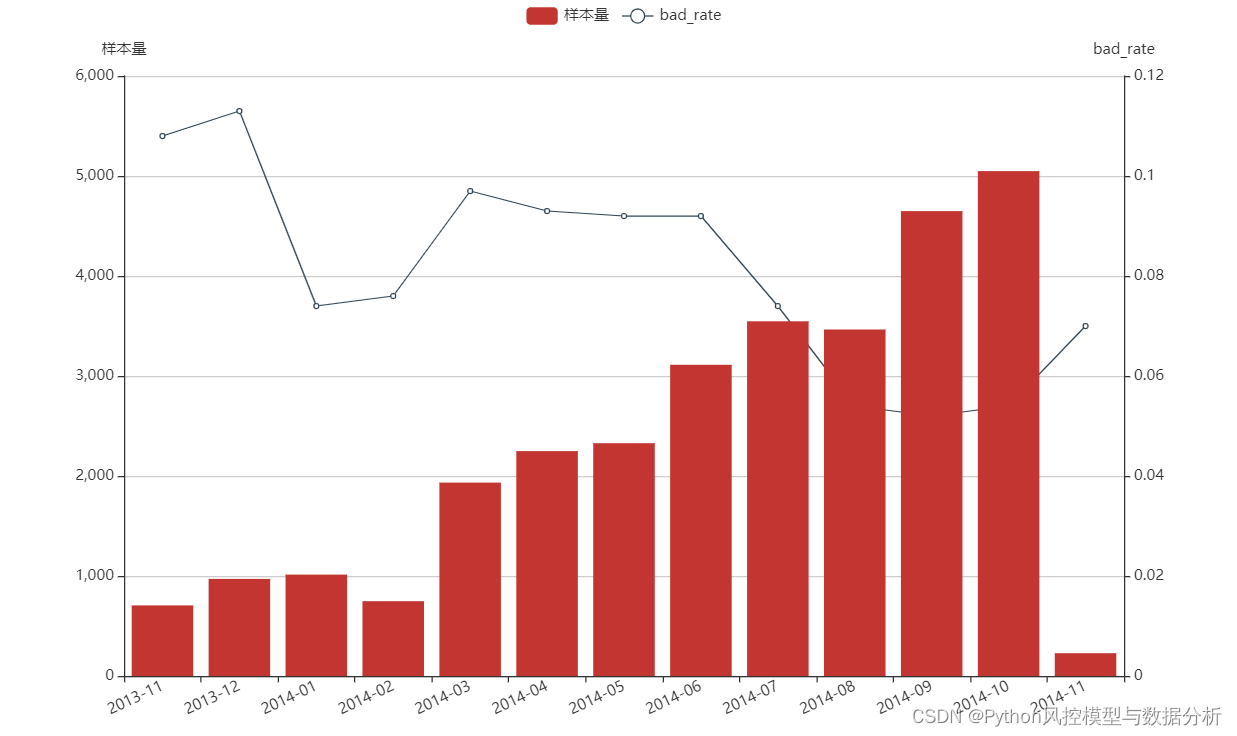
3.2 特征缺失统计
所有特征的缺失率统计:225个变量中,182个无缺失、仅有2个缺失率超过90%
# 所有特征的缺失率统计
pd.DataFrame(df[[col for col in df.columns if df[col].isnull().sum()>0]].isnull().sum()/df.shape[0],columns=['miss_rate'])
# 特征缺失率分布
(df.drop(['Idx','target','ListingInfo'],axis=1).isnull().sum()/df.shape[0]).value_counts().sort_index()
3.3 数据类型分布
特征225列,包括19列离散性变量,其余均为数值型
(1)UserInfo的特征中有多列地址,但格式不统一,需要对其进行数据清洗、方便后续特征衍生
(2)可以看到每列的数据填充值不一致,UserInfo的地址特征、手机运营商特征的缺失填充为"不详",后续特征中有些填充为"D"、有些填充为"E"。对这些填充暂不处理,在实际生产中只要保持离线模型训练的数据和线上数据的填充方式一致即可
# 特征类型分布
df.drop(['Idx','target','ListingInfo'],axis=1).dtypes.value_counts()
# 离散性特征
df.drop(['Idx','target','ListingInfo'],axis=1).select_dtypes(include=['object','string']).head(50)
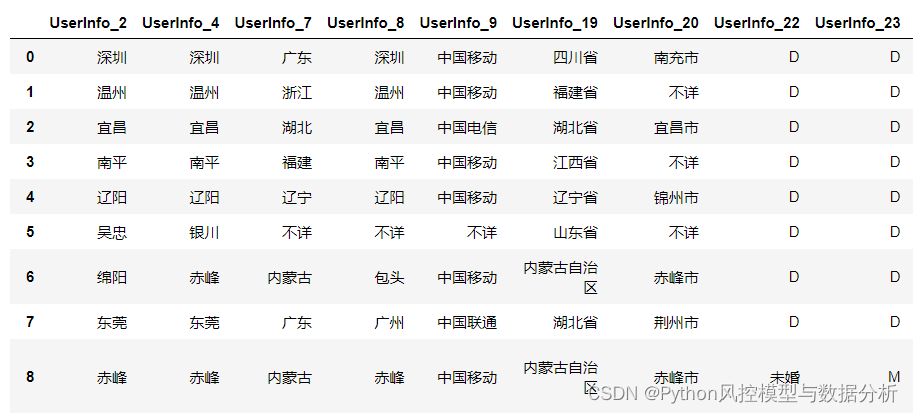
3.4 数据清洗
(1)省、市字段统一化
将UserInfo_19的省份数据与UserInfo_7对齐,删除"省"、"自治区";同理,删除UserInfo_20的"市"
df['UserInfo_19']=df['UserInfo_19'].str.replace('省','').str.replace('自治区','')
df['UserInfo_20']=df['UserInfo_20'].str.replace('市','')
df=df.replace('不详',np.nan)
df.drop(['Idx','target','ListingInfo'],axis=1).select_dtypes(include=['object','string']).head(50)
(2)手机运营商数据清洗
查看手机运内控营商数据,发现部分数据中包含空格,为避免其他离散变量中也存在这种情况、统一进行处理:使用replace将空格删除
df['UserInfo_9']=df['UserInfo_9'].str.replace(' ','')
df['UserInfo_9'].unique()
for col in df.select_dtypes(include=['object','string']).columns:
df[col]=df[col].str.replace(' ','')
3.5 类别型变量单变量分析
### 类别型变量的违约率分析
def cat_bad_rate(df,col_list,target):
result=[]
for col in col_list:
df1 = df.groupby(col)
df2 = pd.DataFrame()
df2['count'] = df1[target].count()
df2['good']=df1[col].count()-df1[target].sum()
df2['bad'] = df1[target].sum()
df2['bad_rate'] = round(df2['bad']/df2['count'],3)
df2.sort_values('bad_rate',ascending=False,inplace=True)
df2 = df2.reset_index()
df2['cum_count']=df2['count'].cumsum()
df2['cum_good']=df2['good'].cumsum()
df2['cum_bad']=df2['bad'].cumsum()
df2['ks']=df2['cum_bad']/df2['bad'].sum()-df2['cum_good']/df2['good'].sum()
result.append(df2)
return result
cat_bad_rate(df,col_list=['UserInfo_9'],target='target')[0]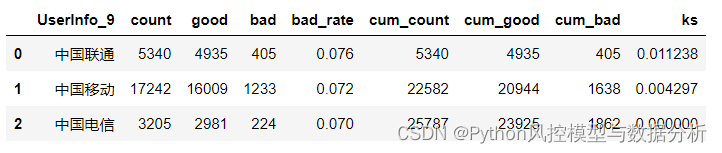
3.6 特征衍生
数据中包含两列省份特征、多列城市特征,可能涉及工作地址、户籍地址、家庭地址等等信息,此处针对地址信息做一致性特征衍生(如两列省份是否一致)
由于城市特征有4个,此处先找出所有的两两组合,分别进行一致性特征衍生
def pick2(list_):
'''
函数功能:根据输入的列表挑选出所有可能的两两组合,并以两层列表输出组合结果
'''
combination=[]
for i in range(len(list_)):
for j in range(i+1,len(list_),1):
combination.append([list_[i],list_[j]])
return combination
city_col=['UserInfo_2','UserInfo_4','UserInfo_8','UserInfo_20'] # 任意选出两列城市衍生一致性特征,4个特征6种组合
combination=pick2(city_col)
combination
生成一致性特征
df['UserInfo_7_19']=(df['UserInfo_7']==df['UserInfo_19']).astype('int') # 省份一致性特征衍生
for item in combination:
df[item[0]+item[1][-2:]]=(df[item[0]]==df[item[1]]).astype('int') # 城市一致性特征衍生
df[['UserInfo_2_4','UserInfo_2_8','UserInfo_7_19']]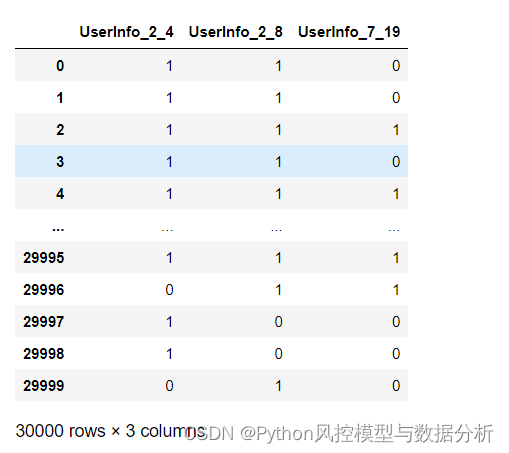
3.7 特征分组
因本文使用lgb、离散性变量可转为category或将类别变量名列表传参给模型,所以将数值型变量和离散性变量分组、方便后续模型训练前处理
float_fea=list(df.drop(['Idx','target','ListingInfo','UserInfo_24'],axis=1).select_dtypes(exclude=['string','object']).columns)
object_fea=list(df.drop(['Idx','target','ListingInfo','UserInfo_24'],axis=1).select_dtypes(include=['string','object']).columns)
all_fea=float_fea+object_fea
print('数值型变量个数:{}'.format(len(float_fea)))
print('离散型变量个数:{}'.format(len(object_fea)))
print('总变量个数:{}'.format(len(all_fea)))
3.8 IV计算
IV计算的代码其实很简单、难点在于内存和运算的优化(还涉及分箱问题),此处使用toad包的iv计算、速度比自己用pandas写的快很多
import toad
def iv_miss(df,var_list,y):
df_tmp=df[df[y].notnull()].copy()
iv_all=toad.quality(df_tmp[var_list+[y]], target=y, indicators = ['iv','unique'])[['unique','iv']]
iv_all.columns=['unique',y+'_iv']
miss_per=pd.DataFrame(df[var_list].isnull().sum()/(df.shape[0]))
miss_per.columns=['缺失率']
result=pd.concat([miss_per,iv_all],axis=1)
return result
df_iv=iv_miss(df,all_fea,'target')
df_iv.sort_values('target_iv',ascending=False).head(50)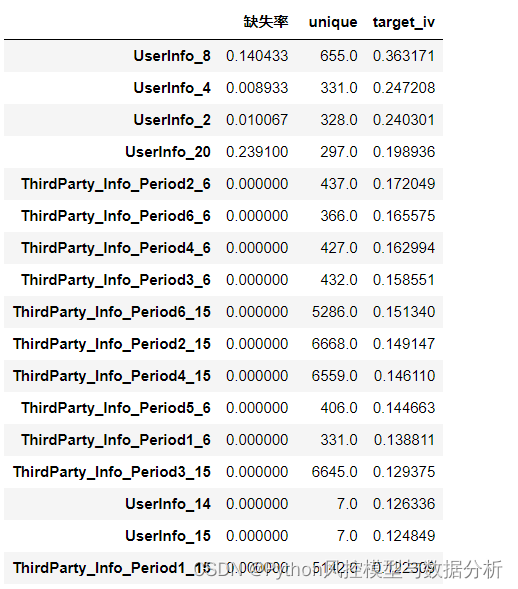
df_iv.describe(np.arange(0.1,1,0.1))
3.9 PSI计算
从训练集、测试集上的特征psi来看,有10个特征psi超出上限,如果将这些变量放入模型进行训练、大概率会有严重的过拟合现象,后续需要进行筛选
def psi_train_test(df1,df2,var_list):
result=[]
for col in var_list:
psi=toad.metrics.PSI(df1[col],df2[col])
result.append({'col':col,'psi':psi})
result=pd.DataFrame(result).set_index('col')
return result
x_train,x_test, y_train, y_test =train_test_split(train[all_fea],train['target'],test_size=0.2, random_state=123)
train_test_psi=psi_train_test(x_train,x_test,all_fea)
train_oot_psi=psi_train_test(x_train,oot,all_fea)
train_test_psi.sort_values('psi',ascending=False).head(20)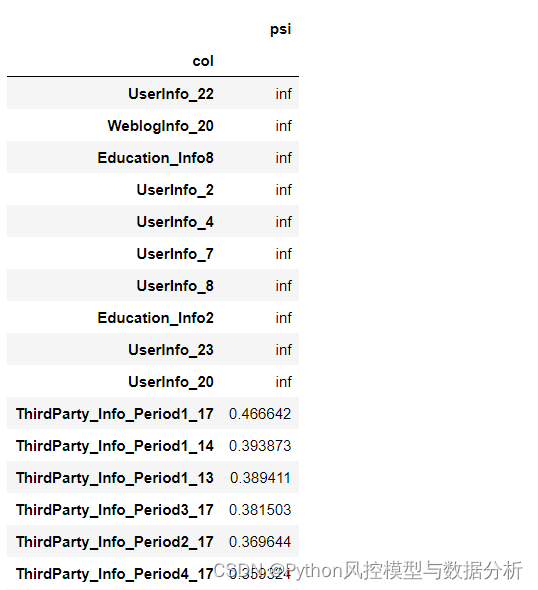
4、建模
4.1 划分oot
依据时间序列划分出一个oot,用于模型效果验证。一方面oot数据量、坏样本量不能太小;另一方面需要尽可能保证train、oot数据集的bad_rate相近,更加客观地评估模型效果
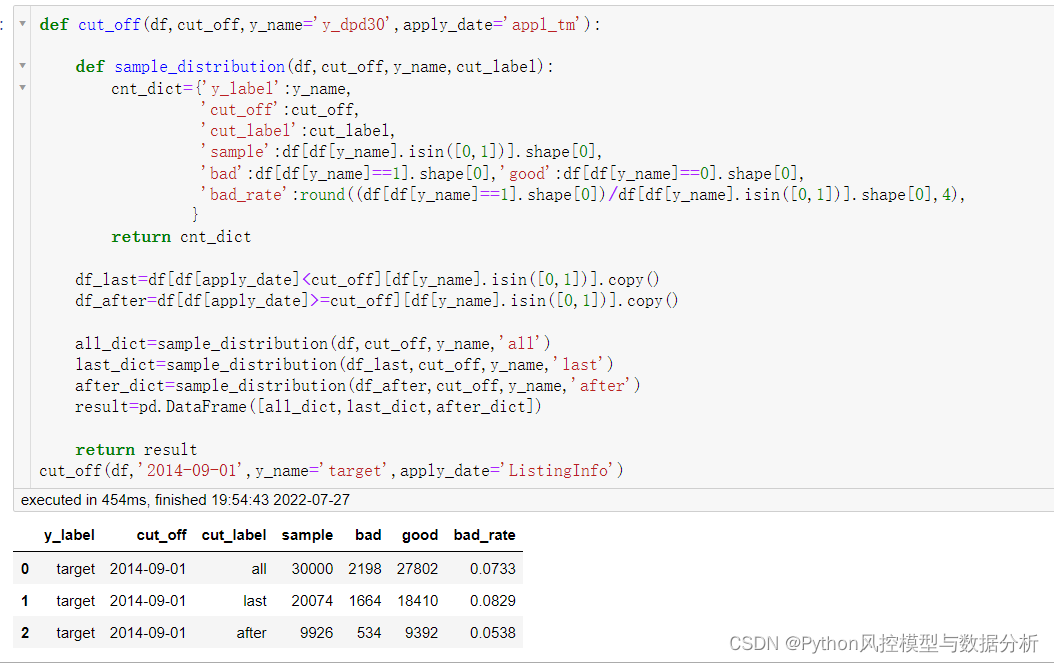

最终选择2014.9.15作为oot的拆分时间
split_time='2014-09-15'
train=df[df['ListingInfo']<split_time].copy()
oot=df[df['ListingInfo']>=split_time].copy()4.2 建模函数
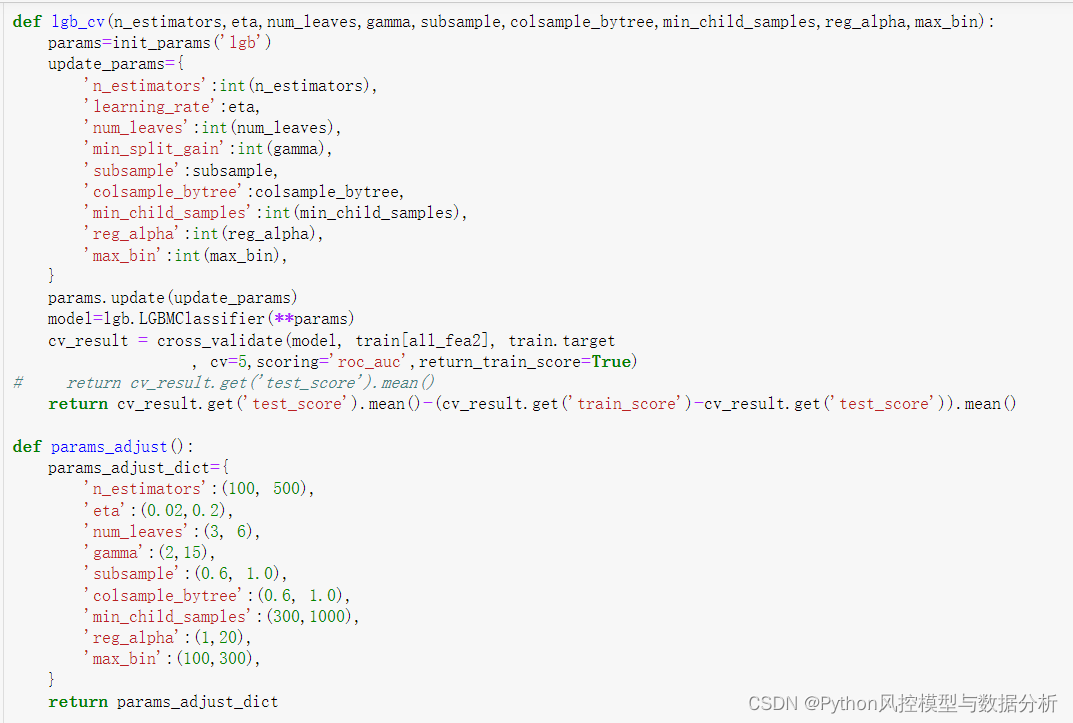
将初始参数、建模过程封装在函数中,方便复用


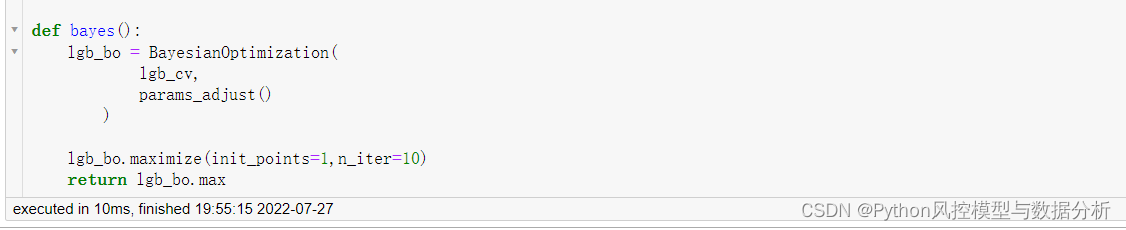
4.3 贝叶斯调参函数
此处使用 交叉验证下的平均测试集auc-训练集测试集的auc 的差值作为调参目标,一方面希望模型效果好,另一方面希望训练测试集的auc差异尽可能地小、避免过拟合
4.4 模型训练
(1)初步训练模型
在未筛选特征、未调参的情况下初步训练模型,可以明显看到有严重的过拟合现象,train_auc_0.88、而test和oot的auc仅0.68
result_dic,model=model_train2_sklearn('model',train,oot,'target',all_fea,model_select='lgb')
result_dic
(2)删除psi较高的变量
前面在计算psi时我们就已经知道,部分变量在训练集、测试集之间的稳定性很差,需要剔除以避免过拟合,此处删除psi>0.5的10个变量,剩余221个
drop_col=list(train_test_psi[train_test_psi.psi>0.5].index)
all_fea2=all_fea.copy()
for col in drop_col:
all_fea2.remove(col)
print(len(all_fea),len(all_fea2))![]()
删除psi较高的变量后重新训练模型,可以看到过拟合现象明显的而到了缓解,训练集测试集的auc仅相差0.05,接下来通过调参来调节过拟合的问题、并提高模型效果
result_dic,model=model_train2_sklearn('model',train,oot,'target',all_fea2,model_select='lgb')
result_dic
(3)贝叶斯调参
调用贝叶斯调参函数,寻找模型最佳效果与泛化能力强之间的平衡
result=bayes() # 返回贝叶斯调参结果
result

将最佳参数带入模型训练查看效果,可以看到在4折交叉验证下、已经没有明显过拟合的问题
params=init_params('lgb')
update_params={
'colsample_bytree': 0.66,
'learning_rate': 0.1,
'min_split_gain': 20,
'max_bin': 100,
'min_child_samples': 100,
'n_estimators': 100,
'num_leaves': 3,
'reg_alpha': 10,
'subsample': 0.628
}
params.update(update_params)
model=lgb.LGBMClassifier(**params)
cv_result = cross_validate(model, train[all_fea2], train.target
, cv=4,scoring='roc_auc',return_train_score=True)
cv_result
4.5 确定最终模型
params=init_params('lgb')
update_params={
'colsample_bytree': 0.66,
'learning_rate': 0.1,
'min_split_gain': 20,
'max_bin': 100,
'min_child_samples': 100,
'n_estimators': 100,
'num_leaves': 3,
'reg_alpha': 10,
'subsample': 0.628
}
params.update(update_params)
result_dic,model=model_train2_sklearn('model',train,oot,'target',all_fea2,model_select='lgb',params=params)
result_dic
特征重要性
def model_feature_importance_lgb(model):
split=pd.DataFrame(model._Booster.feature_importance(importance_type='split'),index=model.feature_name_)
gain=pd.DataFrame(model._Booster.feature_importance(importance_type='gain'),index=model.feature_name_)
split.columns=['split']
gain.columns=['gain']
result=pd.concat([split,gain],axis=1).sort_values('split',ascending=False)
return result
df_feature_importance=model_feature_importance_lgb(model)
df_feature_importance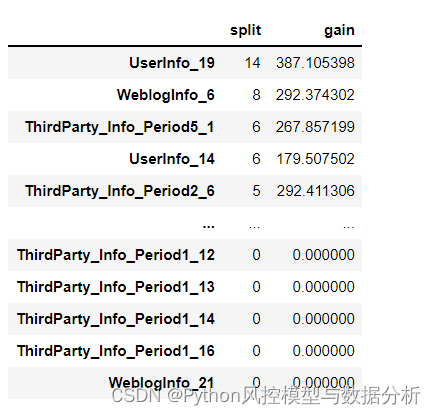
4.6 模型打包
import pickle
# 模型文件打包
with open('模型结果/model_doc','wb') as f:
pickle.dump(model,f)
# 模型文件读取
with open('模型结果/model_doc','rb') as f:
model_test=pickle.load(f)
model_test
写在结尾,关注公众号:Python风控模型与数据分析、回复 风控实战1 ,即可获取本文数据集及完整代码,以及更多理论知识与代码分享
往期精彩文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号