文本分类-One Hot+DNN
目录
上篇介绍了常规统计特征及tf-idf关键词特征的文本分类方法,本篇介绍One-Hot+DNN,读者掌握了这些基础,后续就可以逐步深入理解和学习了。
一、原理介绍
1、One-Hot
独热编码(One-Hot Encoding)是一种常用的特征编码方法,用于将离散型特征表示为二进制向量的形式。它通常用于将分类变量转换为机器学习算法可以处理的数值型数据。
(1)离散型变量
对于一个具有 N 个不同取值的离散特征,独热编码将该特征转换为一个长度为 N 的二进制向量。每个取值对应向量中的一个维度,其中只有一个维度为 1,表示该样本属于该类别,其他维度都为 0。
示例:假设有一个特征 "颜色",可能的取值为 {"红色", "绿色", "蓝色"}。使用独热编码后,每个取值都将转换为一个二进制向量。
"红色":[1, 0, 0]
"绿色":[0, 1, 0]
"蓝色":[0, 0, 1]
(2)拓展到文本数据
对于一条文本而言可以分成多个词、整个文本列表就需要维护一个大词典,那么一条文本就可以表示为词典内的词是否被包含。
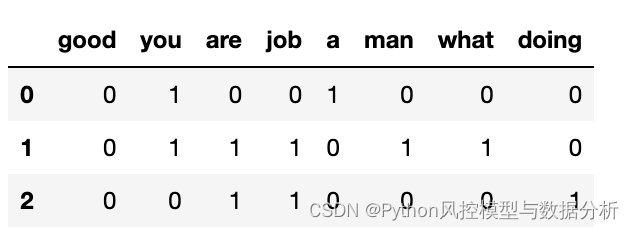
示例:对于文本列表 ['good job!' , 'you are a good man' , 'what are you doing?'],转化为One-Hot形式如下
2、DNN
DNN(深度神经网络)的网络结构通常由输入层、隐藏层和输出层组成。每个层都由多个神经元(或称为节点)组成,这些神经元之间通过连接权重相互连接;神经元内部含有激活函数,包括线性、非线性(relu、tanh、prelu等等),可以对对数据进行非线性变换和特征提取。
(1)输入层(Input Layer):接收原始数据作为输入,并将其传递给下一层隐藏层。
(2)隐藏层(Hidden Layers):在DNN中,可以有一个或多个隐藏层。每个隐藏层都由多个神经元组成。隐藏层的作用是对输入数据进行非线性变换和特征提取。每个隐藏层的输出将作为下一层隐藏层或输出层的输入。
(3)输出层(Output Layer):DNN的最后一层是输出层,它负责产生模型的预测结果。输出层的神经元数量通常取决于具体的任务要求,例如二分类问题只有一个神经元,而多分类问题可能有多个神经元。
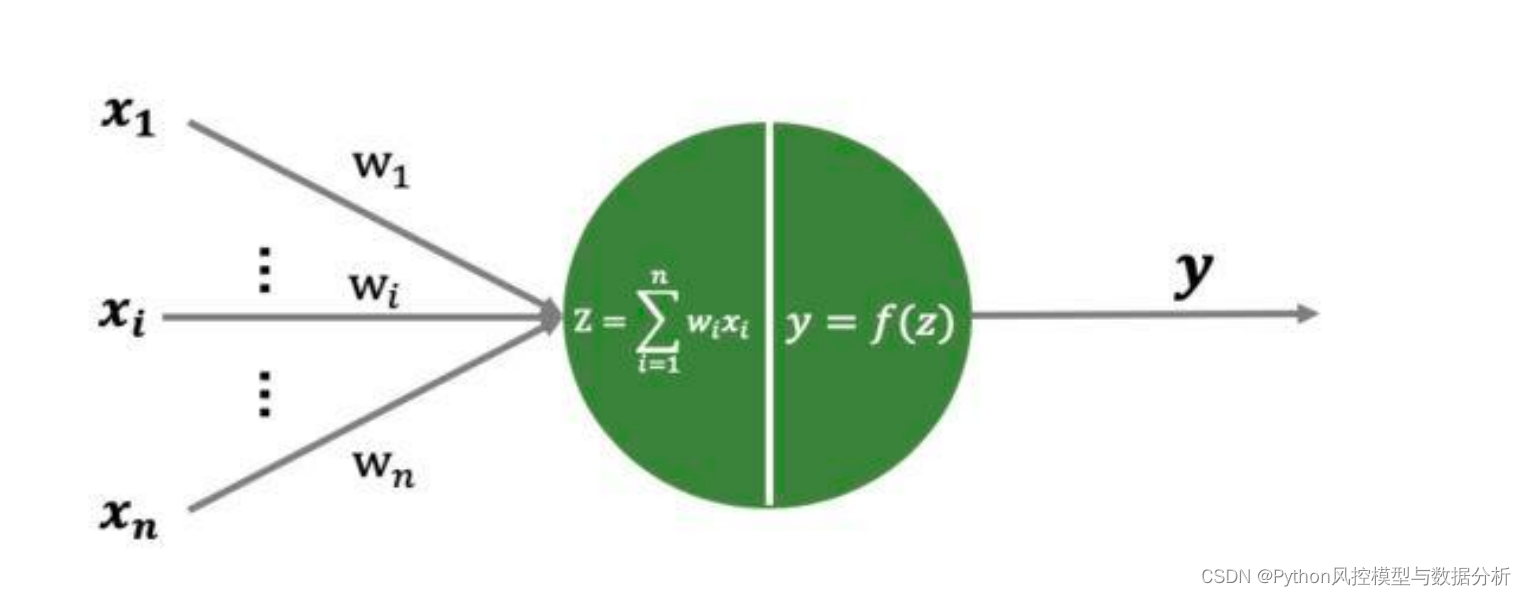
在DNN中,每个神经元都与上一层的所有神经元相连接。每个连接都有一个权重,表示该连接的重要程度,输入数据通过权重矩阵线性加权求和、然后再通过神经元的激活函数变换作为当前层的输出。在训练过程中,DNN通过调整这些权重来逐渐优化模型,使其能够更好地拟合训练数据和泛化到新数据。
二、文本分类实战
数据集同前文,使用YouTube、India Today两类文章做二分类
1、导包
import re
import os
from sqlalchemy import create_engine
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
import matplotlib.pyplot as plt
import gc
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras import optimizers2、数据读取+预处理
data=pd.read_excel('Inshorts Cleaned Data.xlsx')
def data_preprocess(data):
df=data.drop(['Publish Date','Time ','Headline'],axis=1).copy()
df.rename(columns={'Source ':'Source'},inplace=True)
df=df[df.Source.isin(['YouTube','India Today'])].reset_index(drop=True)
df['y']=np.where(df.Source=='YouTube',1,0)
df=df.drop(['Source'],axis=1)
return df
df=data.pipe(data_preprocess)
print(df.shape)
df.head()
3、导入英文停用词
从nltk包倒入停用词
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize
stop_english=stopwords.words('english')
stop_spanish=stopwords.words('spanish')
stop_english4、文本预处理
处理简写、小写化、去除停用词、词性还原
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize
import nltk
def replace_abbreviation(text):
rep_list=[
("it's", "it is"),
("i'm", "i am"),
("he's", "he is"),
("she's", "she is"),
("we're", "we are"),
("they're", "they are"),
("you're", "you are"),
("that's", "that is"),
("this's", "this is"),
("can't", "can not"),
("don't", "do not"),
("doesn't", "does not"),
("we've", "we have"),
("i've", " i have"),
("isn't", "is not"),
("won't", "will not"),
("hasn't", "has not"),
("wasn't", "was not"),
("weren't", "were not"),
("let's", "let us"),
("didn't", "did not"),
("hadn't", "had not"),
("waht's", "what is"),
("couldn't", "could not"),
("you'll", "you will"),
("i'll", "i will"),
("you've", "you have")
]
result = text.lower()
for word_replace in rep_list:
result=result.replace(word_replace[0],word_replace[1])
# result = result.replace("'s", "")
return result
def drop_char(text):
result=text.lower()
result=re.sub('[^\w\s]',' ',result) # 去掉标点符号、特殊字符
result=re.sub('\s+',' ',result) # 多空格处理为单空格
return result
def stemed_words(text,stop_words,lemma):
word_list = [lemma.lemmatize(word, pos='v') for word in text.split() if word not in stop_words]
result=" ".join(word_list)
return result
def text_preprocess(text_seq):
stop_words = stopwords.words("english")
lemma = WordNetLemmatizer()
result=[]
for text in text_seq:
if pd.isnull(text):
result.append(None)
continue
text=replace_abbreviation(text)
text=drop_char(text)
text=stemed_words(text,stop_words,lemma)
result.append(text)
return result
df['short']=text_preprocess(df.Short)
df[['Short','short']]5、划分训练、测试集
test_index=list(df.sample(2000).index)
df['label']=np.where(df.index.isin(test_index),'test','train')
df['label'].value_counts()
6、One-Hot
使用训练集文本构建分词模型应用于one-hot结果
from tensorflow.keras.preprocessing.text import Tokenizer
def word_dict_fit(train_text_list,num_words):
'''
train_text_list: ['some thing today ','some thing today2']
'''
tok_params={
'num_words':num_words, # 词典的长度,仅保留词频top的num_words个词
'filters':'!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
'lower':True,
'split':' ',
'char_level':False,
'oov_token':None, # 设定词典外的词编码
}
tok = Tokenizer(**tok_params) # 分词
tok.fit_on_texts(train_text_list)
return tok
def word_dict_apply_onehot(tok_model,text_list):
'''
text_list: ['some thing today ','some thing today2']
'''
list_tok = tok_model.texts_to_matrix(text_list, mode='binary') # 编码映射
return list_tok
num_words,len_vec = 6000,40
tok_model= word_dict_fit(df[df.label=='train'].short,num_words) # 仅使用训练集训练on e-hot模型
bow_train = word_dict_apply_onehot(tok_model,df[df.label=='train'].short)
bow_test = word_dict_apply_onehot(tok_model,df[df.label=='test'].short)
bow_test
7、模型构建及训练
构建一个两层全连接层+sigmoid输出层的神经网络,用于训练文本二分类数据。
def dnn_model(x_train,y_train,x_test,y_test):
model = models.Sequential([
layers.Dense(16,activation="relu",input_shape=(6000,)),
layers.Dropout(rate=0.4,seed=1),
layers.Dense(16,activation="relu"),
layers.Dropout(rate=0.4,seed=1),
layers.Dense(1,activation="sigmoid")
])
model.compile(
optimizer = optimizers.RMSprop(lr=0.001),
loss = "binary_crossentropy",
metrics = ["accuracy"],
)
history=model.fit(
x_train,y_train,
batch_size=520,
epochs=5,
validation_data=(x_test,y_test)
)
return model,history
model,history=dnn_model(bow_train,df[df.label=='train'].y,bow_test,df[df.label=='test'].y)
model.summary()
8、迭代过程精度
def epoch_curve(model_train):
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.plot(model_train.history['accuracy'], c='g', label='train')
plt.plot(model_train.history['val_accuracy'], c='b', label='validation')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Model accuracy')
plt.subplot(122)
plt.plot(model_train.history['loss'], c='g', label='train')
plt.plot(model_train.history['val_loss'], c='b', label='validation')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Model loss')
plt.show()
epoch_curve(history)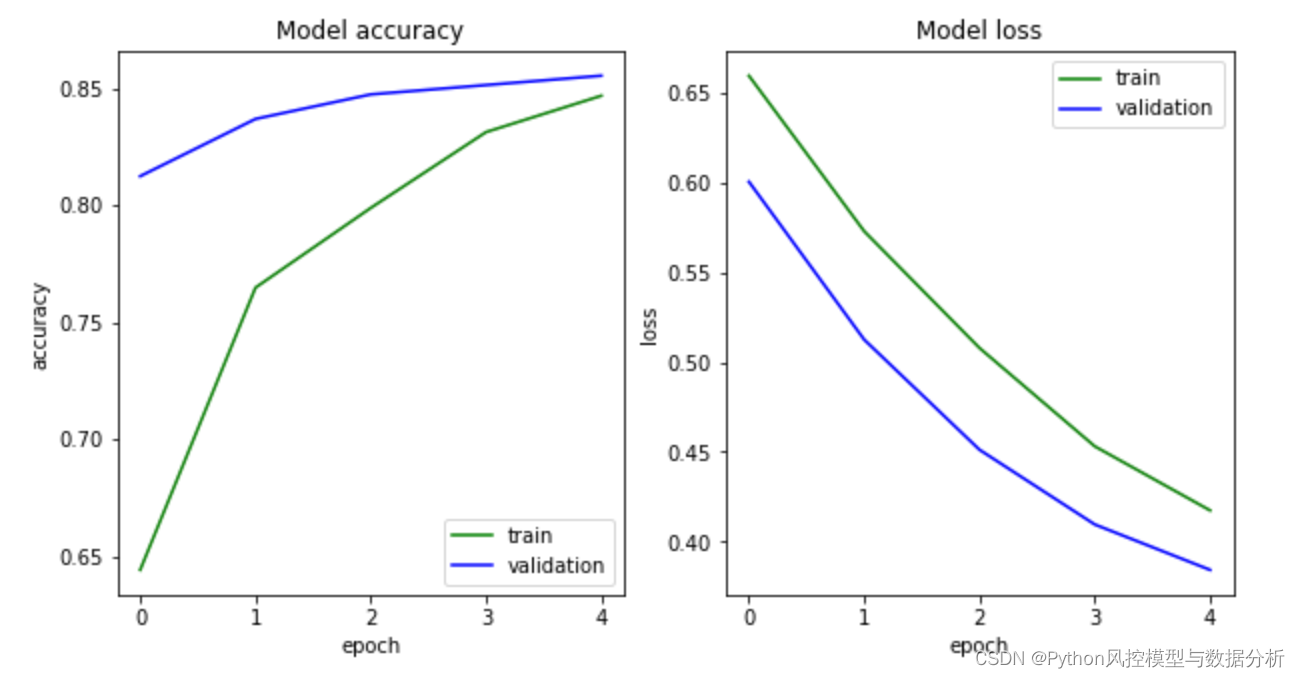
9、模型效果评估
相比于传统特征和tf-idf特征,在这个数据集上,one-hot+神经网络的效果明显更高,测试集auc轻松达到0.91
def ks_auc_value(y_value,y_pred):
fpr,tpr,thresholds= roc_curve(list(y_value),list(y_pred))
ks=max(tpr-fpr)
auc= roc_auc_score(list(y_value),list(y_pred))
return ks,auc
ks_auc_value(df[df.label=='train'].y,bow_train,model)
'''
output
(0.792300466328842, 0.9482740929379625)
'''
ks_auc_value(df[df.label=='test'].y,bow_test,model)
'''
output
(0.7236812624031752, 0.9128766964342871)
'''三、划重点
少走10年弯路
关注威信公众号Python风控模型与数据分析,回复 文本分类2 获取本篇数据及代码
还有更多理论、代码分享等你来拿

 浙公网安备 33010602011771号
浙公网安备 33010602011771号