条件过滤检索
 向量检索服务DashVector支持条件过滤和向量相似性检索相结合,在精确满足过滤条件的前提下进行高效的向量检索。
向量检索服务DashVector支持条件过滤和向量相似性检索相结合,在精确满足过滤条件的前提下进行高效的向量检索。
背景介绍
在大多数业务场景中,单纯使用向量进行相似性检索并无法满足业务需求,通常需要在满足特定过滤条件、或者特定的"标签"的前提下,再进行相似性检索。
向量检索服务DashVector支持条件过滤和向量相似性检索相结合,在精确满足过滤条件的前提下进行高效的向量检索。
条件过滤检索示例
说明
-
需要使用您的api-key替换示例中的 YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
-
本示例需要参考新建Collection-使用示例
插入带有Field的数据
Python
import dashvector
import numpy as np
client = dashvector.Client(
api_key='YOUR_API_KEY',
endpoint='YOUR_CLUSTER_ENDPOINT'
)
collection = client.get(name='quickstart')
ret = collection.insert([
('1', np.random.rand(4), {'name':'zhangsan', 'age': 10, 'male': True, 'weight': 35.0}),
('2', np.random.rand(4), {'name':'lisi', 'age': 20, 'male': False, 'weight': 45.0}),
('3', np.random.rand(4), {'name':'wangwu', 'age': 30, 'male': True, 'weight': 75.0}),
('4', np.random.rand(4), {'name':'zhaoliu', 'age': 5, 'male': False, 'weight': 18.0}),
('5', np.random.rand(4), {'name':'sunqi', 'age': 40, 'male': True, 'weight': 70.0})
])
assert ret
说明
在新建Collection-使用示例中,创建了名称为quickstart的Collection,该Collection定义了3个Field({'name': str, 'weight': float, 'age': int})。DashVector具有Schema Free的特性,因此可以在插入Do时,随意指定创建Collection时未定义的Field,如上述示例中的maleField。
通过filter进行条件过滤检索
Python
import dashvector
client = dashvector.Client(
api_key='YOUR_API_KEY',
endpoint='YOUR_CLUSTER_ENDPOINT'
)
collection = client.get(name='quickstart')
# 要求年龄(age)大于18,并且体重(weight)大于65.0的男性(male=true)
docs = collection.query(
[0.1, 0.1, 0.1, 0.1],
topk=10,
filter = 'age > 18 and weight > 65.0 and male = true'
)
print(docs)
DashVector支持的数据类型
当前DashVector支持Python的4种基础数据类型:
-
str
-
float
-
int
-
bool
重要
Python的int类型可表达无限大小的整数,当前DashVector仅支持32位整数,范围为-2,147,483,648~2,147,483,647,需要用户自行保证数据未溢出。
比较运算符
通过Field 比较运算符 常量的组合生成比较表达式,说明及示例如下:
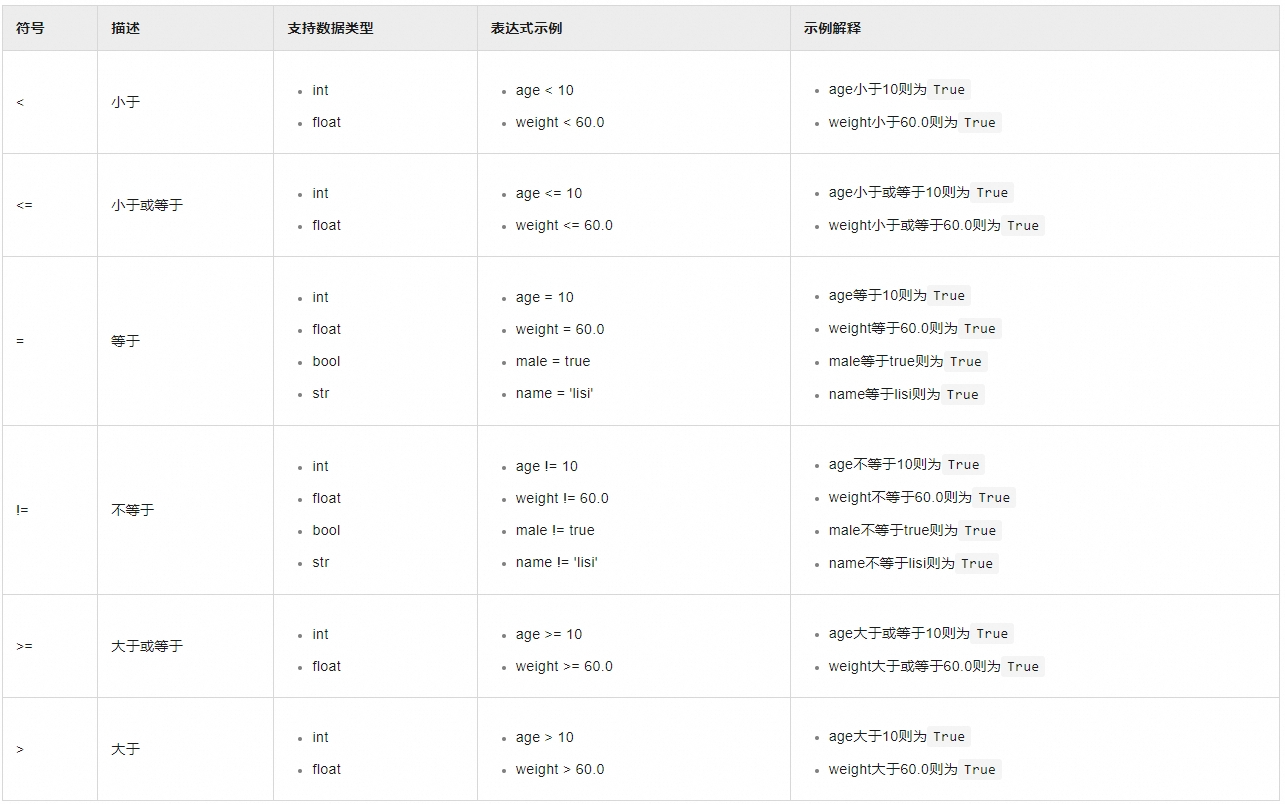
成员运算符
通过Field 成员运算符 常量的组合生成比较表达式,说明及示例如下:
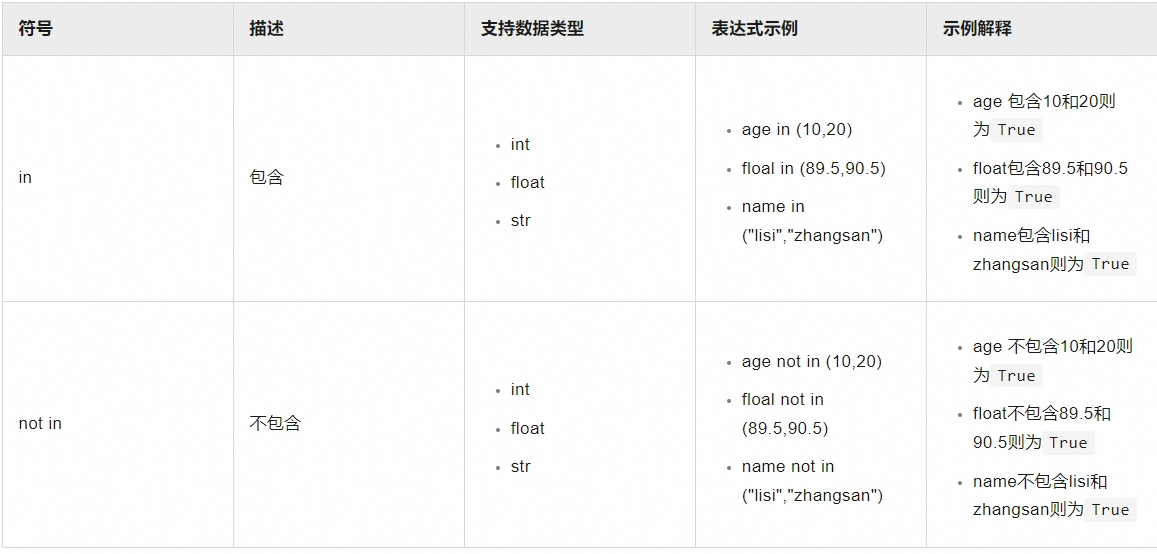
字符串运算符
通过Field 字符串运算符 常量的组合生成匹配表达式,说明及示例如下:

逻辑运算符
逻辑运算符用于组合多个表达式。

说明
可通过括号()组合逻辑运算符,()拥有更高优先级,如:expr1 and (expr2 or expr3),会优先计算(expr2 or expr3)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号