Storm手写WordCount
建立一个maven项目,在pom.xml中进行如下配置:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.darrenchan</groupId> <artifactId>StormDemo</artifactId> <version>0.0.1-SNAPSHOT</version> <name>StormDemo</name> <dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>0.9.5</version> <!--<scope>provided</scope> --> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>cn.itcast.bigdata.hadoop.mapreduce.wordcount.WordCount</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> </plugins> </build> </project>
项目目录为:
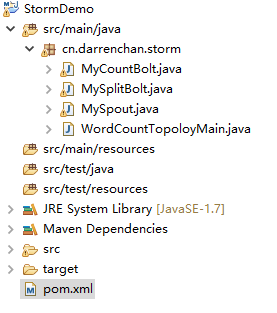
MySpout.java:
package cn.darrenchan.storm; import java.util.Map; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichSpout; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; public class MySpout extends BaseRichSpout { private SpoutOutputCollector collector; //storm框架不停地调用nextTuple方法
//values继承ArrayList
@Override public void nextTuple() { collector.emit(new Values("i am lilei love hanmeimei")); } //初始化方法 @Override public void open(Map config, TopologyContext context, SpoutOutputCollector collector) { this.collector = collector; } //声明本spout组件发送出去的tuple中的数据的字段名 @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("love")); } }
MySplitBolt.java:
package cn.darrenchan.storm; import java.util.Map; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; public class MySplitBolt extends BaseRichBolt { private OutputCollector collector; //storm框架不停地调用,传入参数是tutle @Override public void execute(Tuple input) { String line = input.getString(0); String[] words = line.split(" "); for (String word : words) {
//Values有两个,对应下面Fields有两个 collector.emit(new Values(word, 1)); } } //初始化方法 @Override public void prepare(Map config, TopologyContext context, OutputCollector collector) { this.collector = collector; } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) {
//Fields有两个,对应上面Values有两个 declarer.declare(new Fields("word", "num")); } }
MyCountBolt.java:
package cn.darrenchan.storm; import java.util.HashMap; import java.util.Map; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Tuple; public class MyCountBolt extends BaseRichBolt { private OutputCollector collector; private Map<String, Integer> map; @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; map = new HashMap<String, Integer>(); } @Override public void execute(Tuple input) { String word = input.getString(0); Integer num = input.getInteger(1); if(map.containsKey(word)){ map.put(word, map.get(word) + num); } else { map.put(word, 1); } System.out.println(map); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
WordCountTopoloyMain.java:
package cn.darrenchan.storm; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; import backtype.storm.tuple.Fields; public class WordCountTopoloyMain { public static void main(String[] args) throws Exception { //1.准备一个TopologyBuilder TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("mySpout", new MySpout(), 1); builder.setBolt("mySplitBolt", new MySplitBolt(), 2).shuffleGrouping("mySpout"); builder.setBolt("myCountBolt", new MyCountBolt(), 2).fieldsGrouping("mySplitBolt", new Fields("word")); //2.创建一个configuration,用来指定当前的topology需要的worker的数量 Config config = new Config(); config.setNumWorkers(4); //3.任务提交 两种模式————本地模式和集群模式 //集群模式 //StormSubmitter.submitTopology("myWordCount", config, builder.createTopology()); //本地模式 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("myWordCount", config, builder.createTopology()); } }
三种求wordcount方式 比较:
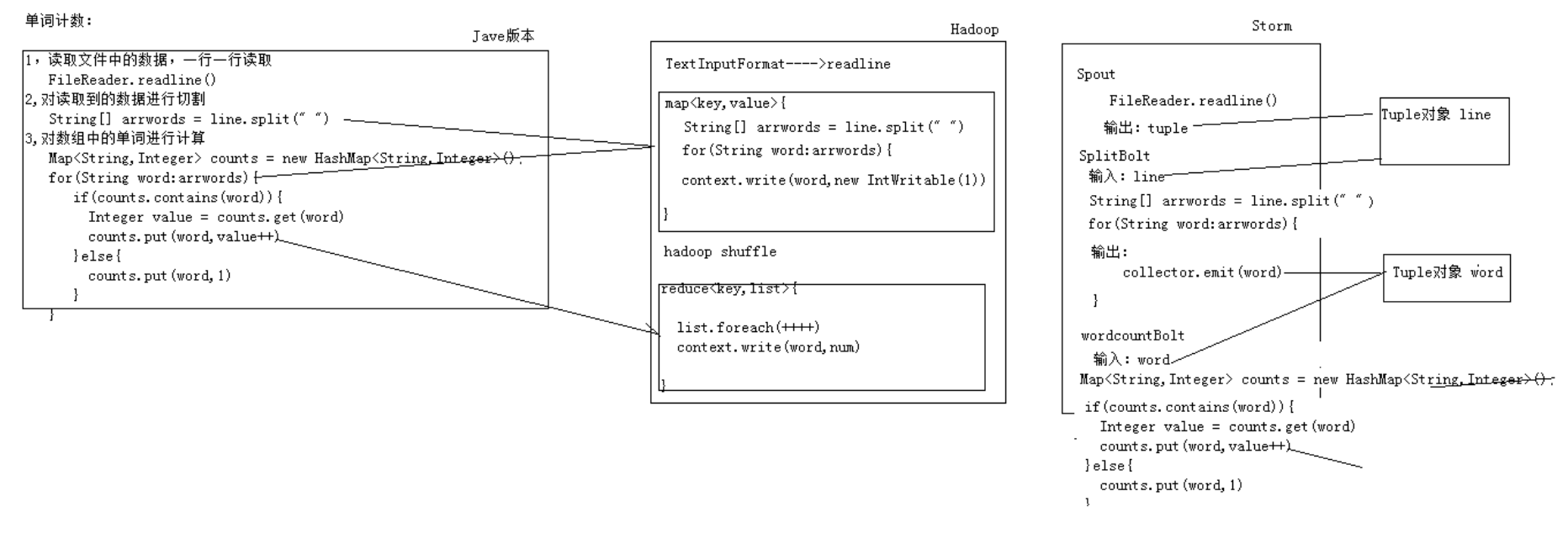
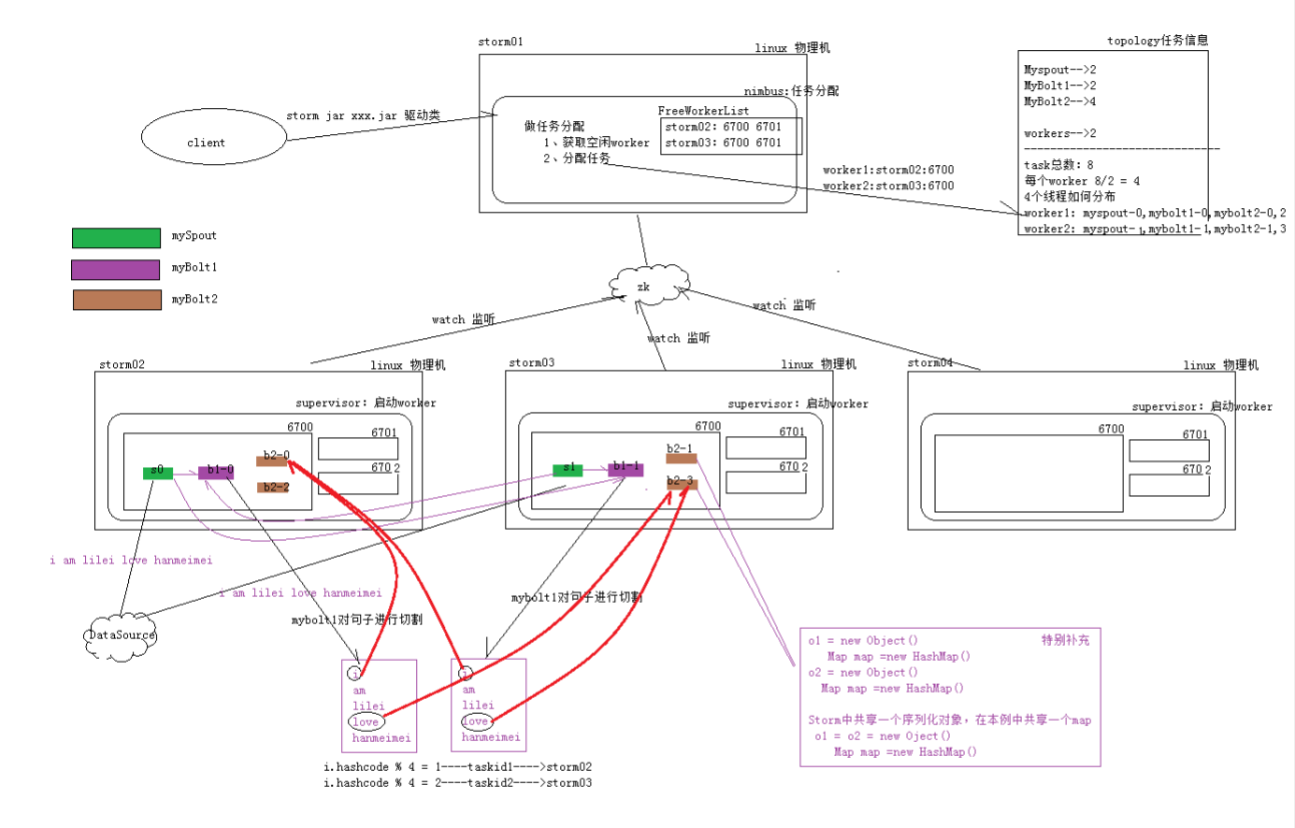
整体运行架构图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号