Kafka学习笔记
1. 相关概念
1. kafka是一个分布式的消息缓存系统
2. kafka集群中的服务器都叫做broker
3. kafka有两类客户端,一类叫producer(消息生产者),一类叫做consumer(消息消费者),客户端和broker服务器之间采用tcp协议连接
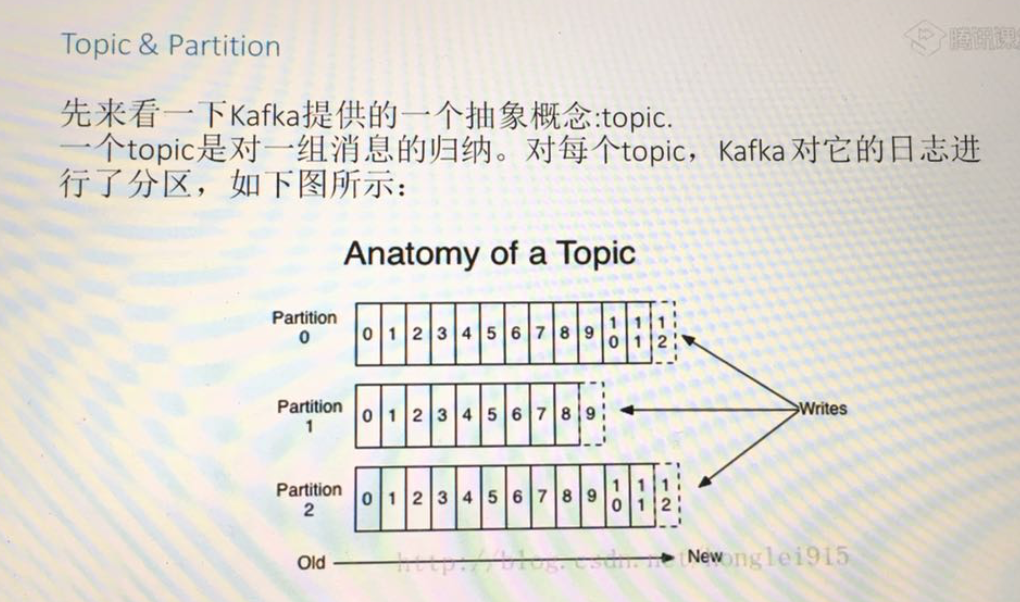
4. kafka中不同业务系统的消息可以通过topic进行区分,而且每一个消息topic都会被分区,以分担消息读写的负载
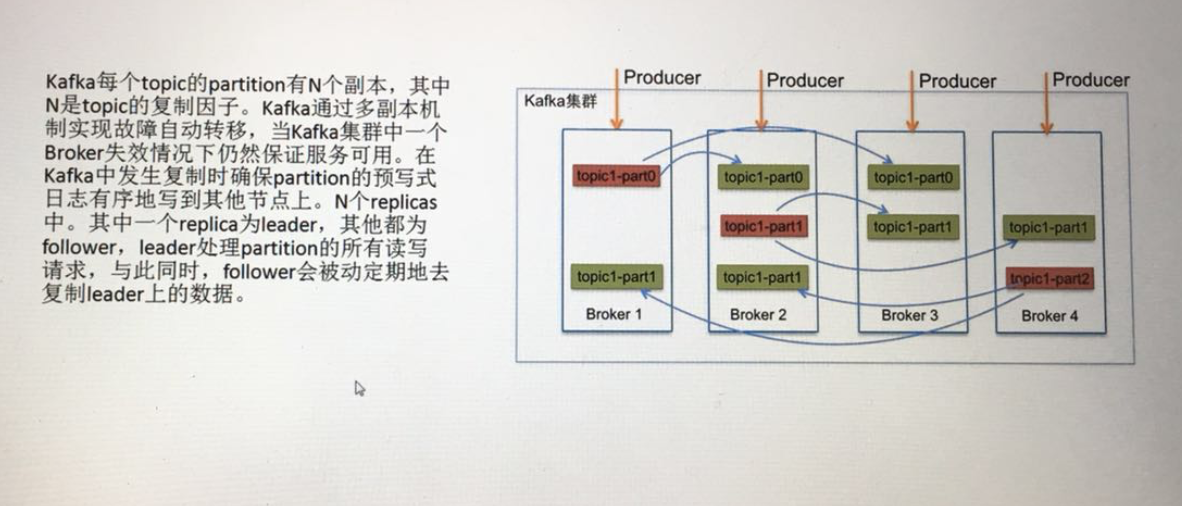
5. 每一个分区都可以有多个副本,以防止数据的丢失
6. 某一个分区中的数据如果需要更新,都必须通过该分区所有副本中的leader来更新
7. 消费者可以分组,比如有两个消费者组A和B,共同消费一个topic:order_info,A和B所消费的消息不会重复
比如 order_info 中有100个消息,每个消息有一个id,编号从0-99,那么,如果A组消费0-49号,B组就消费50-99号
8. 消费者在具体消费某个topic中的消息时,可以指定起始偏移量
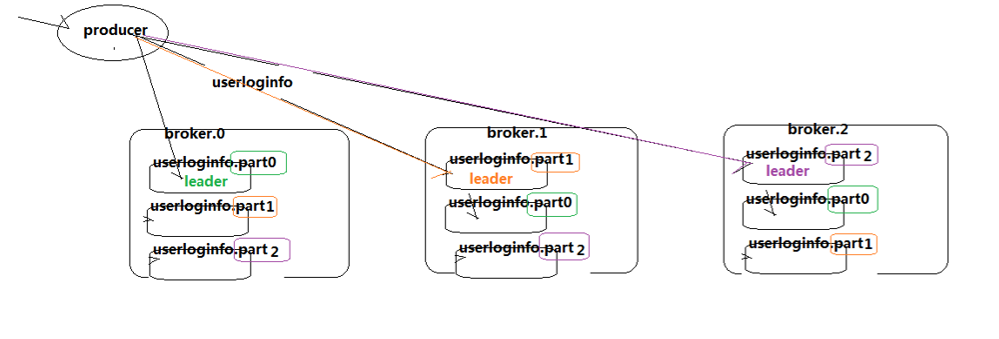
kafka的业务架构:

2. 集群安装
1、解压
2、修改config/server.properties
broker.id=1(每台机器上的id要唯一,可以写成0,1,2,3,4……)
zookeeper.connect=weekend01:2181,weekend02:2181,weekend03:2181
3、将zookeeper集群启动
4、在每一台节点上启动broker
bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
5、在kafka集群中创建一个topic
bin/kafka-topics.sh --create --zookeeper weekend01:2181 --replication-factor 3 --partitions 1 --topic order
修改分区个数
bin/kafka-topics.sh –zookeeper localhost:2181 -alter --partitions 5 --topic order
查看该topic
bin/kafka-topics.sh --list --zookeeper weekend01:2181
6、用一个producer向某一个topic中写入消息
bin/kafka-console-producer.sh --broker-list weekend01:9092 --topic order
7、用一个comsumer从某一个topic中读取信息
bin/kafka-console-consumer.sh --zookeeper weekend01:2181 --from-beginning --topic order
8、查看一个topic的分区及副本状态信息
bin/kafka-topics.sh --describe --zookeeper weekend01:2181 --topic order
下面是一个演示:
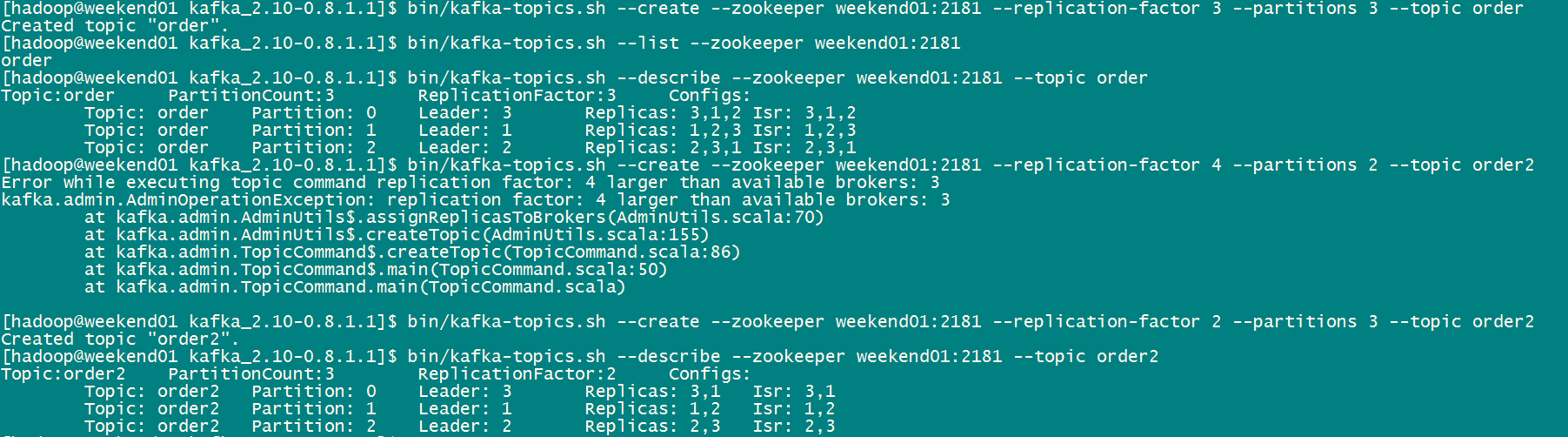
我们可以这么理解:副本的数量不能大于broker的数量,如果是2就随机在三个broker中选择两个,如果是3就在每个broker中都有一个副本。分区是几,就是topic最终被分成了几份,看leader,就知道该份被分到了哪一台broker上,图中的1,2,3对应的就是配置文件中broker服务器的id。其中的Isr指的是当前这份Partition在哪些broker上处于同步状态。
3. 可能的错误
启动服务器broker报错:
Unrecognized VM option 'UseCompressedOops'
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.

原因:
需要JDK1.8,而安装的版本低于1.8。
解决办法:
换成JDK1.8,或者改脚本bin/kafka-run-class.sh文件。
去搜索UseCompressedOops关键词,找到那一行的代码如下:
KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseCompressedOops -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -Djava.awt.headless=true"
改成:
KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -Djava.awt.headless=true"
问题解决。


4. 发送消息的主要步骤
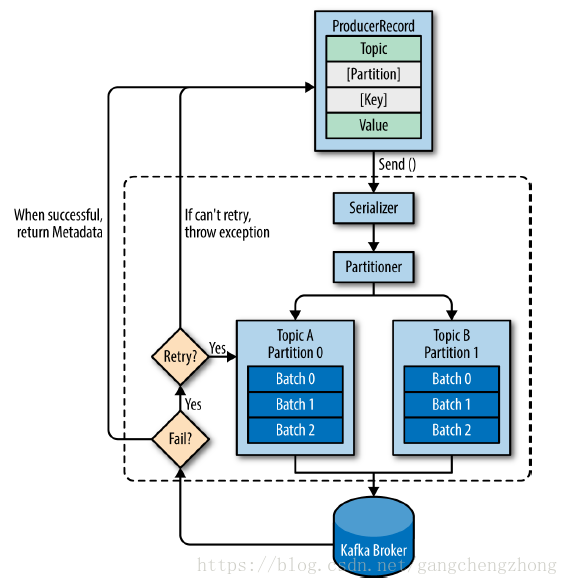
首先创建ProducerRecord对象,此对象除了包括需要发送的数据value之外还必须指定topic,另外也可以指定key和分区。当发送ProducerRecord的时候,生产者做的第一件事就是把key和value序列化为ByteArrays,以便它们可以通过网络发送。
接下来,数据会被发送到分区器。如果在ProducerRecord中指定了一个分区,那么分区器会直接返回指定的分区;否则,分区器通常会基于ProducerRecord的key值计算出一个分区。一旦分区被确定,生产者就知道数据会被发送到哪个topic和分区。然后数据会被添加到同一批发送到相同topic和分区的数据里面,一个单独的线程会负责把那些批数据发送到对应的brokers。
当broker接收到数据的时候,如果数据已被成功写入到Kafka,会返回一个包含topic、分区和偏移量offset的RecordMetadata对象;如果broker写入数据失败,会返回一个异常信息给生产者。当生产者接收到异常信息时会尝试重新发送数据,如果尝试失败则抛出异常。
内容补充:





 浙公网安备 33010602011771号
浙公网安备 33010602011771号