HDFS的HA机制
传统的HDFS机制如下图所示:
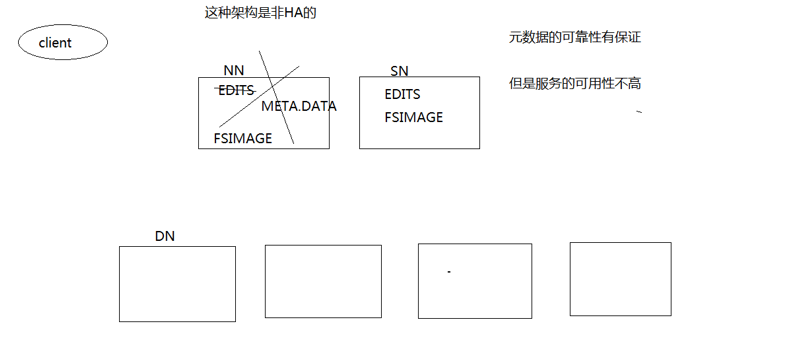
也就是存在一个NameNode,一个SecondaryNameNode,然后若干个DataNode。这样的机制虽然元数据的可靠性得到了保证(靠edits,fsimage,meta.data等文件),但是服务的可用性并不高,因为一旦NameNode出现问题,那么整个系统就陷入了瘫痪。所以,才引入了HDFS的HA机制。我们先来看一下关于HDFS的HA机制和Federation机制的简介:
HA解决了HDFS的NameNode的单点问题;
Federation解决了整个HDFS集群中只有一个名字空间,并且只有单独的一个NameNode管理所有DataNode的问题。
一、HA机制(High Availability)
1.HA集群
HDFS 的高可用性(HA, High Availability)是为了解决集群不可用的问题引入的,集群不可用主要是宕机、 NameNode 软硬件升级等导致的。 HA 机制通过提供选择运行在同一集群中的一个热备用的“主/备”两个冗余 NameNode ,使得在机器宕机或维护的过程中可以快速转移到另一个 NameNode。
典型的 HA 集群会配置两个独立机器为 NameNode ,分别为主 NameNode 和副本 NameNode 。正常情况下,主 NameNode 为 alive 状态而副本 NameNode 为休眠状态,活动 NameNode 负责处理集群中所有的客户端操作,待机时仅仅作为一个 slave ,保持足够的状态,如果有必要会提供一个快速的故障转移。
关于保持同步。为了保持备用节点与活动节点状态的同步,两个节点同时访问一个共享存储设备(例如从 NAS、NFS 挂载)到一个目录。
2.HA机制作用
HA 机制出现的作用主要是为了:
1.解决单点故障;
2.提升集群容量和集群性能。
二、Federation机制
为了防止单点失效(Single PointFailure),在 NameNode 只有命名空间的情况下。其最主要的原因是对 HDFS 系统的文件隔离,Federation 可以解决大部分单 NameNode HDFS 的问题。
总之,HDFSFederation就是使得HDFS支持多个命名空间,并且允许在HDFS中同时存在多个NameNode。
1.Federation架构
HDFS Federation使用多个独立的 NameNode / NameSpace 使得 HDFS 的命名服务能水平扩展,HDFS Federation中的 NameNode 之间为独立且不需要相互协调,Federation 中的 NameNode 提供了名字空间和块管理功能。Federation 中的 DataNode 被所有的 NameNode 用作公共存储块的地方。每个 DataNode 都会向所在集群中所有的 NameNode 注册,并且周期性发送心跳和块信息报告,同时处理来自 NameNode 的指令。
HDFS 只有一个名字空间 NameSpace 时,它使用全部的块,而 Federation HDFS 中有多个独立的NameSpace ,并且每个名字空间使用一个块池Block Pool(注:就是属于单个名字空间的一组 Block ),每个DataNode 为所有的块池存储块,DataNode是个物理概念,而块池是另一个重新将块划分的逻辑概念。
HDFS 中只有一组块。而Federation HDFS中有多组独立的块,块池就是属于同一个名字空间的一组块。
HDFS 由一个 NameNode 和一组 DataNode 组成,而 Federation HDFS 由多个 NameNode 和一组 DataNode 组成,每个 DataNode 会为多个块池存储块。同一个 DataNode 中可以存着属于多个块池的多个块。块池允许一个名字空间在不通知其他名字空间的情况下为一个新的 Block 创建 Block ID ,同时一个 NameNode 失效不会影响其下的 DataNode 为其他的 NameNode 服务。
在 HDFS 中,所有的更新、回滚都是以 NameNode 和 Block Pool 为单元发生的,即同 HDFS Federation 中不同的 NameNode/Block Pool 之间没有什么关系。
在 DataNode 中,对应于每个 NameNode 都有一个相应的线程。每个 DataNode 会去每个 NameNode 注册,并周期性地给所有的 NameNode 发送心跳和使用报告,DataNode 还会给 NameNode 发送其所在的块池报告 block report,由于有多个 NameNode 同时存在,因此任何一个 NameNode 都可以随时动态加入、删除和更新。
2.多名字空间管理
在一个集群中需要唯一的名字空间还是多个名字空间,核心问题是名字空间中数据的共享和访问的问题。解决数据共享和访问的一种方法:使用全局唯一的名字空间,在多个名字空间下,还可以使用 Client Side Mount Table 方式做到数据共享和访问。
HDFS Federation 名字空间管理基本原理:将各个名字空间挂载到全局 mount-table 中,就可以将数据到全局共享;同样,名字空间挂载到个人 mount-table 中,就成为应用程序可见的名字空间视图。
而HA架构图如下图所示:


我们需要两台NameNode,那么我们就需要保证信息的同步,因为前面介绍HDFS时讲过,edits日志里面总是存储最新的数据,所以我们就让edits共享,两台NameNode每次都往同一个edits里面进行读写。但是只有一个edits,难免会出问题,所以我们就同时有多个edits,并把他们部署到集群上。多个,又部署到集群上,肯定会涉及数据同步,切换等多个问题,这不就是之前我们讨论的Zookeeper问题吗?所以我们做了一个分布式应用qjournal,并用它管理这么多edits,每个edits又叫做journalnode。qjournal底层是基于Zookeeper实现的,所以journalnode只要有半数以上的节点活着,qjournal就不会瘫痪。
两台NameNode不能同时处于active状态,一台处于active状态,另外一台就必须是standby状态。当一台NameNode死了,另外一台就会变成active状态了。但是两台NameNode之间的切换是怎么保证的呢?
这里开了两个进程,时时刻刻监控本地NameNode的状态。当前active状态的NameNode的进程如果发现不正常,就往zookeeper里面写一些数据。另外一个进程时时刻刻从zookeeper里面读数据,来随时掌握
对方NameNode的状态,如果发现对方死了,就可以进行NameNode的切换,这个状态管理的进程就叫做zkfc。用来做两个NameNode的切换管理,包括失败切换。具体功能依赖于zookeeper实现。
这里还有一个问题,就是brain split:
所谓brain split,就是一台NameNode出现假死,而另外一台NameNode以为它真死了,所以也变成active了,等一下假死的NameNode恢复了,这样就会两台NameNode都处于active状态,显然这是不可以的。
我们有两个解决办法:
1.ssh发送kill指令,直接杀死对方NameNode进程,再进行切换。
2.ssh指令不能保证每次都执行成功,那就设置一个时间,如果一定时间ssh指令还没有返回值,就会运行自定义的脚本,将对方NameNode杀死,再进行切换。
这种解决的机制叫做fencing机制。
我们将上面一对NameNode叫做一个nameservice,访问它可以用ns1(name service 1)来表示。若干个这样的NameNode对叫做Federation。
这里需要提醒一下:不光HDFS有高可用,YARN也有高可用,只不过相对HDFS就简单多了,ResourceManager主从切换即可。
最后,介绍一下namenode的安全模式:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号