Linux下配置Hadoop伪分布式环境
1. 准备Linux环境
提示:我用的系统是CentOS 6.4。
1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:192.168.1.0 子网掩码:255.255.255.0 -> apply -> ok
回到windows --> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.1.100 子网掩码:255.255.255.0 -> 点击确定
在虚拟软件上 --My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok
1.1修改主机名
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=weekend110 ###
1.2修改IP
两种方式:
第一种:通过Linux图形界面进行修改(强烈推荐)
进入Linux图形界面 -> 右键点击右上方的两个小电脑 ->
点击Edit connections ->
选中当前网络System eth0 ->
点击edit按钮 ->
选择IPv4 ->
method选择为manual ->
点击add按钮 ->
添加IP:192.168.230.134
子网掩码:255.255.255.0
网关:192.168.230.1 -> apply
第二种:修改配置文件方式
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" ###
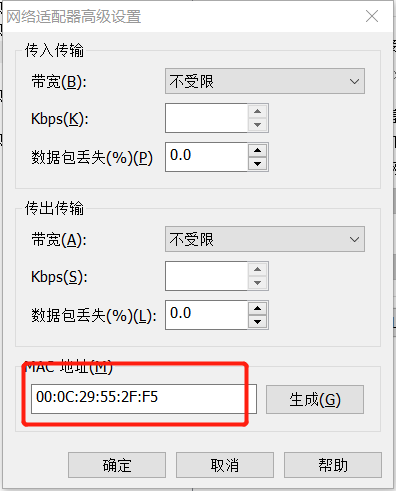
HWADDR="00:0C:29:3C:BF:E7"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.230.134" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.168.230.1" ###
修改完成后,执行sudo service network restart
但是可能会报错:Error:No suitable device found: no device found for connection "System eth0"
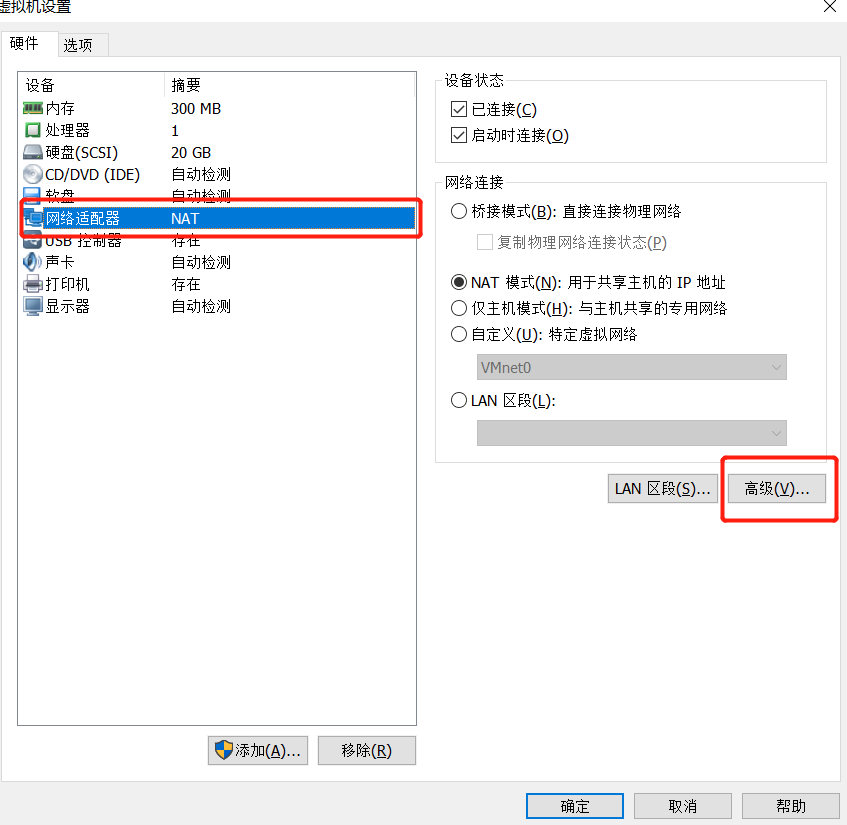
按照下面的方式找MAC地址,然后把刚才配置文件中的HWADDR进行修改即可。
参考:https://blog.csdn.net/seven_zhao/article/details/43429571
https://jingyan.baidu.com/article/ff42efa9d58ae4c19e2202a1.html
=======================================================
DEVICE=eth2
BOOTPROTO=static
HWADDR=00:0C:29:66:ED:93
ONBOOT=yes
NETMASK=255.255.255.0
IPADDR=10.129.64.11
USERCTL=no
IPV6INIT=no
NM_CONTROLLED=yes
GATEWAY=10.129.64.1
TYPE=Ethernet
1.3修改主机名和IP的映射关系
vim /etc/hosts
192.168.230.134 weekend110
1.4关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
1.5重启Linux
reboot
注:Ubuntu系统可能用secureCRT无法连接,是因为Ubuntu默认没有ssh,安装一个即可
sudo apt-get install openssh-server openssh-client
2. 安装JDK
2.1上传alt+p 后出现sftp窗口,然后put d:\xxx\yy\ll\jdk-7u_65-i585.tar.gz
2.2解压jdk
#创建文件夹
mkdir /home/hadoop/app
#解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app
2.3将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585

#刷新配置
source /etc/profile
3. 安装hadoop
先上传hadoop的安装包到服务器上去/home/hadoop/
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
3.1配置hadoop
第一个:hadoop-env.sh
vim hadoop-env.sh
#第27行
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
第二个:core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://weekend110:9000(端口号默认就是9000)</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.4.1/data</value>
</property>
第三个:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 下面是配置SecondaryNameNode的IP,可以不用配置 -->
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.230.134:50090</value>
</property>
第四个:mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
第五个:yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>weekend110</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.2将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1

source /etc/profile
3.3格式化namenode(是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
3.4启动hadoop
先启动HDFS
sbin/start-dfs.sh
再启动YARN
sbin/start-yarn.sh
3.5验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.230.134:50070 (HDFS管理界面)
http://192.168.230.134:8088 (MR管理界面)
4. 配置SSH免登录
在hadoop主机上,
#删除.ssh文件
rm -rf ~/.ssh
#生成ssh免登陆密钥
ssh-keygen -t rsa (三个回车)
ssh-copy-id localhost
下面是不用ssh-copy-id localhost的另外一种方式(了解即可)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆(chenchi)的机器上
sudo scp id_rsa.pub chenchi:/home/chenchi
接下来,在chenchi主机上,先去到目录/home/hadoop/.ssh
再touch authorized_keys
改权限sudo chmod 600 authorized_keys
将拷贝过来的公钥追加到authorized_keys文件后面
cat ../id_rsa.pub >>authorized_keys
与此同时,在hadoop主机上,先去到目录/home/hadoop/.ssh
再touch authorized_keys
改权限sudo chmod 600 authorized_keys
将自己的公钥追加到authorized_keys文件后面
cat id_rsa.pub >>authorized_keys

 浙公网安备 33010602011771号
浙公网安备 33010602011771号