AI,DM,ML,PR的区别与联系
数据挖掘和机器学习的区别和联系,周志华有一篇很好的论述《机器学习与数据挖掘》可以帮助大家理解。数据挖掘受到很多学科领域的影响,其中数据库、机器学习、统计学无疑影响最大。简言之,对数据挖掘而言,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。由于统计学往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。从数据分析的角度来看,绝大多数数据挖掘技术都来自机器学习领域,但机器学习研究往往并不把海量数据作为处理对象,因此,数据挖掘要对算法进行改造,使得算法性能和空间占用达到实用的地步。同时,数据挖掘还有自身独特的内容,即关联分析。
而模式识别和机器学习的关系是什么呢,传统的模式识别的方法一般分为两种:统计方法和句法方法。句法分析一般是不可学习的,而统计分析则是发展了不少机器学习的方法。也就是说,机器学习同样是给模式识别提供了数据分析技术。
至于,数据挖掘和模式识别,那么从其概念上来区分吧,数据挖掘重在发现知识,模式识别重在认识事物。
机器学习的目的是建模隐藏的数据结构,然后做识别、预测、分类等。
因此,机器学习是方法,模式识别是目的。
-----------------------------------------------------------------
人工智能(Artificial Intelligence,AI) 、机器学习(Machine Learning,ML) 、模式识别 (Pattern Recognition, PR)、数据挖掘 (Data Mining, DM)、信息检索(Information Retrieval,IR)……我想起之前在 BeBeyond 的一个同学,我说我做 ML 的,他说“我 做 DM 的,我们都是搞计算机的呢!”后来我才明白,ML 和 DM 根本就没有多大区 别。其实,上面列的这些学科本质上都没有太大区别,只不过它们要解决的核心问 题不同,而运用的数学模型如出一辙。
先说 AI。这个词大众比较熟悉,通常一个电子游戏的 AI 直接决定了游戏的可玩 性。简单的 AI 比如超级玛丽里会扔刺猬的云怪,复杂的 AI 比如红色警戒中需要操 纵整个国家的电脑敌人。我很小的时候就在想这些算法得有多么复杂。慢慢地我意 识到电脑控制方式与我不一样。 我是单线程的, 在一个时间点上要么控制坦克进攻, 要么控制基地建设;而电脑的每个单位都有独立的思考能力和通信能力。这些是通 过设计逻辑来实现的(难怪在 98 年买的电脑上跑一点也不卡) ,比如坦克的逻辑可 能是“IF 附近的友军收到攻击,THEN 前去支援”,矿车的逻辑可能是“IF 受到攻击, THEN 向基地撤退”……等等。 AI 其实就是计算机自动做决策。做决策的原则可以是上面简单的条件判断,可以 是穷举,也可以是多个因素连接成的网络,比如下图(称为贝叶斯网络,Bayesian Network) ,这是一个通过判断是否有地震和盗窃的简单的智能系统。 用贝叶斯网络做决策,需要设置的参数都是概率形式的,比如地震发生的概率是 2.6%,盗窃发生的概率是 12.4%,地震发生时警报响的概率是 72%……等等。这些 参数有了之后,当有一天警报响起,系统就能够回溯地计算出警报响是由地震发生 还是盗窃发生引起的。
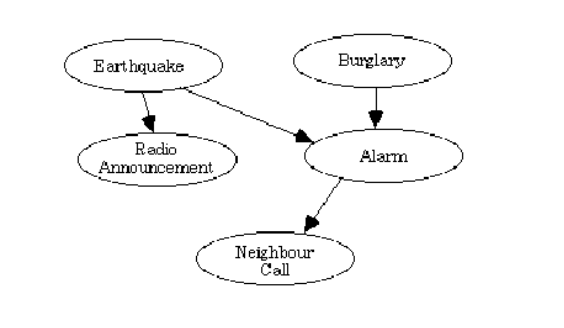
下面说 ML。ML 是最可怕的部分。上面说的 AI 系统的规则都是人为设定的,所 以它的表现绝大多数情况在人们的期待以内。而 ML 算法可能使系统变得过分地聪 明。一个绝佳的 ML 例子见以下链接。
http://en.akinator.com/
这是一个网络小游戏,你在心中想一个人物,然后算法会问你一系列的一般疑问 句(比如“这个人是科学家吗?”)你回答 Yes 或者 No。若干个问题后,算法会知道 你心中的人物是谁了(通常比你预计的要快) 。 之所以说这是一个 ML 系统,是因为它不仅做决策下一个问题该问什么、已经问 的问题和答案能推出什么结果,它还在不断地自我改进。比如说,我心中想的人物 是亚运会的吉祥物阿和 (几年前这个游戏推出时它肯定不知道阿和是谁) ,于是在很 多个问题过后,这个 ML 算法猜成喜羊羊了,然后我告诉它“你猜错了,我想的是阿 和”,于是,它会更新它的决策网络,增加阿和这个节点,改变各个概率值。下次有 人想阿和的,它就可能猜中了。 所以,从上面的例子可以看出,ML 重点研究的是算法的学习过程,强调的是一 个反馈的框架。一开始系统可能很弱智,但是经过长期训练后它能做出很高超的决 策。
举个我的例子。比如说,我老板希望能做一个自动作曲的系统,要求能做莫扎特 风格的钢琴奏鸣曲,而听起来不能像海顿和贝多芬。想一想这个决策规则就复杂得 看似不可能实现, 也许 10000 个 IF...THEN...也不能实现。 但是从 ML 的角度来思考, 就变得有可能了。我可以把莫扎特已有的乐谱输入给系统,告诉它这是好结果;再 把海顿和贝多芬的给系统,告诉它这是坏结果。然后就期待这个系统能够学到点什 么。当然,真正实现起来设计这个学习框架是有难度的,不过 ML 是正确的思路。
接下来说的是 PR。我本科时北邮的课程就叫模式识别。PR 充满了工程的思维方 式,“解决问题是关键,不关心系统在理论上是否最优”。比如人脸识别、癌细胞识 别、语言识别、入侵检测等等,拿各种分类器(SVM、神经网络神马的)一个一个 试,用最好的那个分类器来应用就 OK 了。
然后是 DM。DM 是一项应运而生的科学,正因为互联网蓬勃发展,才吸引那么 多人研究 DM。个人认为 Google 之所以比百度聪明,就是因为 Google 的 DM 牛。 对于成千上万个网页(看做是众多单词组成的序列) ,DM 算法可能发现“新闻”、“报 导”、“记者”等词语是具有关联性的,于是用户在搜索“新闻”这个关键词时,与“新 闻”相关的词也可能提供对用户有价值的信息。总之,DM 是从数据中挖掘出高层的 语义关联信息。
再举个我的例子。我前一段时间做了一个音乐结构分段的算法,旨在将音乐中主 歌、副歌这些结构单元自动分离。DM 中就有一个热门的算法能够达到我的目的, 如下图,把《Creep》分解成为两个部分。技术细节就省略吧。 最后,提一提 IR。IR 的目的希望互联网能够变得更加人性化。比如你在搜索引 擎中输入“推荐个便宜的可以玩桌游的地方”, 算法一方面从这句话中提取 IR (retrieve) 出有用的信息:是个地方,要可以玩桌游,便不便宜自己看着办;另一方面从网络 上取出(retrieve)合理的网页给用户。
总结一下吧。只要跟决策有关系的都能叫 AI,所以说 PR、DM、IR 属于 AI 的具 体应用应该没有问题。 研究的东西则不太一样, ML 强调自我完善的过程。 Anyway, 这些学科都是相通的,Google 也是越来越聪明的,不是么。 前一段时间看到关于机器阅卷比人工靠谱的消息。也许在不久的将来会有一大批 人失业,机器会代替会记、医生、甚至程序员。也许,机器的智能会产生很多很多 的争议, 但是我们必须承认, 在不太需要创造性的工作中, 我们真的比不上机器的。 最好的方式大概就是机器与人协同合作。 CCRMA 的 Jonathan Berger 来北京演讲, 他提到的 sonification 给我挺大的启发。他说:“我们买西瓜时拍一拍就知道西瓜是 否熟了,因为人耳对于这种音色可以做决策,而机器目前还很难做到。监测工作很 辛苦,比如核电站工作人员需要成天盯着很多很多数据,不停地做决策,判断是否 出异常。为什么不能把数据通过某种算法变换出某种音色,工作人员只需要学习什 么是正常的声音,什么是异常的声音,听就行了,这与听拍西瓜的声音是一样的道 理。”
摘录于:http://www.cnblogs.com/growup/archive/2011/04/26/2029393.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号