【JUC】线程池及Executor
线程池介绍
线程池(thread pool):一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,对线程统一管理。
线程池就是存放线程的池子,池子里存放了很多可以复用的线程。
创建线程和销毁线程的花销是比较大的(手动new Thread 类),创建和消耗线程的时间有可能比处理业务的时间还要长。这样频繁的创建线程和销毁线程是比较消耗资源的。(我们可以把创建和销毁的线程的过程去掉)。
使用线程池的优势
- 提高效率,创建好一定数量的线程放在池中,等需要使用的时候就从池中拿一个,这要比需要的时候创建一个线程对象要快的多。
- 减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
- 提升系统响应速度,假如创建线程用的时间为T1,执行任务用的时间为T2,销毁线程用的时间为T3,那么使用线程池就免去了T1和T3的时间;
1、线程池的实现原理
1.1 线程池的处理流程
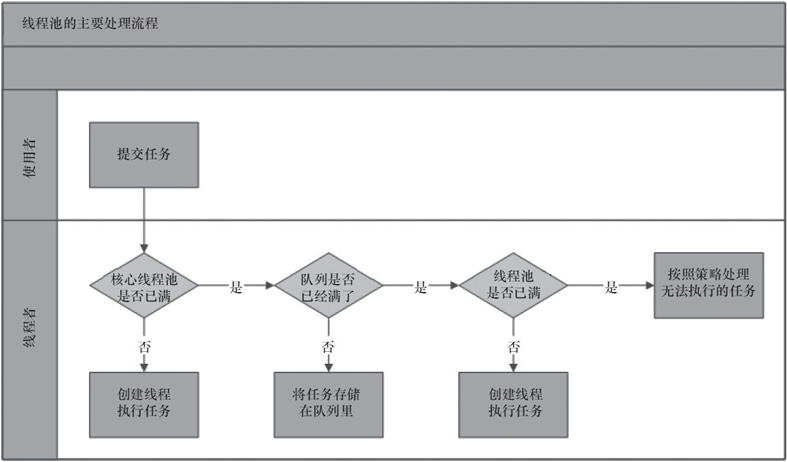
(1)线程池判断核心线程池里的线程是否都在执行任务。如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下个流程。
(2)线程池判断工作队列是否已经满。如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
(3)线程池判断线程池的线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
1.2 处理流程的具体分析
-
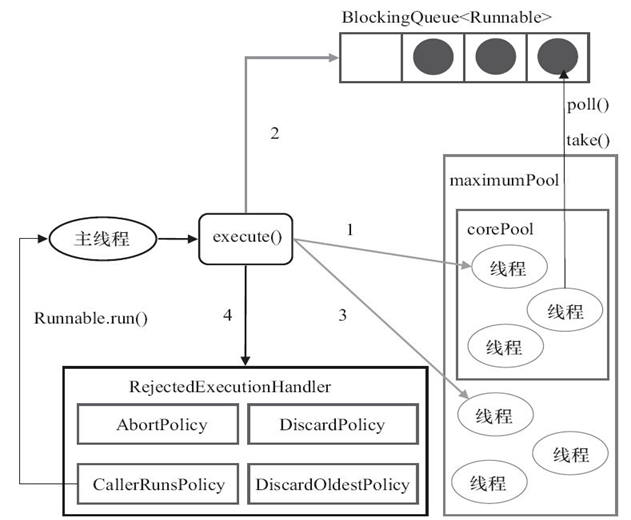
如果当前工作线程数量小于核心线程数量
corePollSize,执行器总是优先创建一个任务线程(注意,执行这一步骤需要获取全局锁),而不是从线程队列中获取一个空闲线程 -
如果线程池中总的任务数量大于核心线程池数量
corePollSize,新接收的任务将被加入阻塞队列中,一直到阻塞队列已满。当完成一个任务的执行时,执行器总是优先从阻塞队列中获取下一个任务,并开始执行,一直到阻塞队列为空
-
在核心线程池数量已经用完、阻塞队列
BlockingQueue也已经满了的场景下,如果线程池接收到新的任务,将会为新任务创建一个线程(非核心线程)(注意,执行这一步骤需要获取全局锁),并且立即开始执行新任务 -
在核心线程都用完、阻塞队列已满的情况下,一直会创建新线程去执行新任务,直到池内的线程总数超出maximumPoolSize。如果线程池的线程总数超过maximumPoolSize,线程池就会拒绝接收任务,当新任务过来时,会为新任务执行拒绝策略(
RejectedExecutionHandler.rejectedExecution()方法)
ThreadPoolExecutor采取上述步骤的总体设计思路,是为了在执行execute()方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁。
注意点:
- 核心和最大线程数量、BlockingQueue队列等参数如果配置得不合理,可能会造成异步任务得不到预期的并发执行,造成严重的排队等待现象
- 线程池的调度器创建线程的一条重要的规则是:在corePoolSize已满之后,还需要等阻塞队列已满,才会去创建新的线程
example: 设置核心线程数量为1,阻塞队列为100,有5个任务待执行(假设极端情况下任务一直执行不接受),则只有1个任务可以被执行,其他4个任务在阻塞队列中,而不是创建新线程进行处理(阻塞队列未满)
1.3 线程池为什么要有一个核心线程数和最大线程数的区分呢?
(1)首先要明确,核心线程数和最大线程数中间还有一个 BlockingQueue,如果核心线程数够用,不一定先去创建其他的非核心线程,因为需要看阻塞队列中是否还能够继续容纳新的请求;如果没有所谓的最大的线程数,只有一个核心线程数,那么当我们的核心线程数配置小了的话,那么很多任务都会添加到 queue 中,如果 queue 满了,我们就没有其他的办法创建新的额外的线程了。
(2)如果仅仅依靠核心线程数,比如将核心线程数的值设置的非常大,每次有新任务过来,都有可能在核心线程数里面创建新的线程(总是优先创建新的线程而不是获取空闲的线程),可能会造成全局锁的获取,导致性能瓶颈。
1.4 全局锁是什么东西?
当 ThreadPollExecutor 进行 execute() 方法的执行的时候,如果当前的工作线程小于 CoreSize,就会进行一个新的工作线程的添加,调用 addWorker() 方法,这个方法里,当我们进行最终的 worker.add() 的时候,是在一个 rentrantlock 里执行的。也就是说,此处不允许并发地添加新的 worker,如果同时有多个线程进来,且都小于 coresize,只能排队添加
2、线程池的参数
(1)corePollSize:线程池的基本的大小
当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的 prestartAllCoreThreads() 方法,线程池会提前创建并启动所有的基本线程。
(2)runnableTaskQueue:任务队列
建议选用有界队列设置队列长度。
- 如果是无界队列,那么 queue 永远不会满,永远不会处罚到 maximumPollSize。意味着 maximumPollSize 这个参数就失去了他的作用
- 最重要的是,无界队列无法控制队列最终包含的数据量,导致内存资源的极大消耗甚至耗尽
- 选用有界队列并合理的配置 maximumPollSize
- 饱和策略的使用根据需求选择。一旦触发了饱和策略,就说明:要么是我们的线程池配置有问题,要么真的是并发量太高,任务太多,导致的问题。警醒我们进行深入的参数调查及合理的配置
(3)maximumPollSize:线程池允许创建的最大线程数量
如果任务队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如果任务队列使用了无界队列,这个参数就没有效果了
(4)ThreadFactory:用于设置创建线程名字的工厂
可以通过线程工厂给每个创建出来的线程设置更有意义的名字,使用开源框架guava提供的ThreadFactoryBuilder可以快速给线程池里的线程设置有意义的名字
(5)RejectedExecutionHandler:饱和策略
当线程池和任务队列都处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是 AbortPolicy,表示无法处理新任务时抛出异常。在 JDK1.5 中Java线程池框架提供了以下四种策略:
AbortPolicy:直接抛出异常。使用的相对多一些,因为我们会再异常处理的过程中进行各种手段,如记录日志,存入数据库等待 retryCallerRunsPolicy:只用调用者所在线程来执行任务。用的相对少一些,因为调用者线程也是系统资源,说明线程数量已经很多了,调用者线程的加入其实是变相地增加了 maximumPollSizeDiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。(几乎没人使用)DiscardPolicy:不处理,丢弃掉(使用的很少)
(6)keepAliveTime:线程活动保持时间
线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多,并且每个任务执行的时间较短,可以调大时间,提高线程的利用率
(7)TimeUnit:线程活动保持时间的单位
可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微秒)
3、合理配置线程池
想要合理地配置线程池,就必须要首先分析任务特性,可以从一下几个角度来分析:
- 任务的性质:CPU密集型任务、IO密集型任务和混合型任务
- 任务的优先级:高、中、低
- 任务的执行时间:长、中、短
- 任务的依赖性:是否依赖其他系统资源,如数据库链接(我们的线程池是 20 coresize,但是数据库同时只支持 10 个链接,这个时候要选择不能够大于数据库的连接数的一个数字,最大选 10, maxSize也是10)
性质不同的任务可以用不同规模的线程池分开处理。CPU 密集型任务应配置尽可能少的线程,如配置 Ncpu+1 个线程的线程池。由于 IO 密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如 2*Ncpu。
【建议使用有界队列。有界队列能增加系统的稳定性和预警能力】
【总结】
(1)我们的线程池是生存在一个复杂的系统环境里,我们还有其他的接口需要使用我们的服务器资源,所以在进行线程池coresize的配置以及maxsize的配置的时候,我们需要明确我们当前的接口的重要性,如果当前接口占据了未来业务访问的50%,那么就可以分配50%的系统资源给当前接口。(我们一个服务,总有一些重要接口和非重要接口,在我们进行项目开发初期,需求就定好了。)
(2)一定要基于压测。来评估线程池的参数是否合理。(全服务压测。)
(3)我们要给线程池开后门,可以动态的调整线程池的参数。(我们现在很多大型项目都有自己的配置中心,appolo是一个非常好的配置组件,你可以将coresize和maxsize配置到配置中心,一旦发生不可控的高并发场景,可以随时修改配置中心的参数,我们的项目就会按照新的标准进行调整。)
4、线程池的监控与关闭
如果在系统中大量使用线程池,则有必要对线程池进行监控,方便在出现问题时,可以根据线程池的使用状况快速定位问题。可以通过线程池提供的参数进行监控,在监控线程池的时候可以使用以下属性。
- taskCount:线程池需要执行的任务数量。
- completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于taskCount。
- largestPoolSize:线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是否曾经满过。如该数值等于线程池的最大大小,则表示线程池曾经满过。
- getPoolSize:线程池的线程数量。如果线程池不销毁的话,线程池里的线程不会自动销毁,所以这个大小只增不减。
- getActiveCount:获取活动的线程数。
通过扩展线程池进行监控。可以通过继承线程池来自定义线程池,重写线程池的beforeExecute、afterExecute和terminated方法,也可以在任务执行前、执行后和线程池关闭前执行一些代码来进行监控。例如,监控任务的平均执行时间、最大执行时间和最小执行时间等。这几个方法在线程池里是空方法。
关闭线程池:
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别,shutdownNow首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,而shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
4、Executor框架介绍
java的线程既是工作单元,也是执行机制。从jdk5开始,把工作单元与执行机制分离开来。工作单元包括 Runnable 和 Callable,而执行机制由 Executor 框架提供。
4.1 Executor框架的两级调度模型
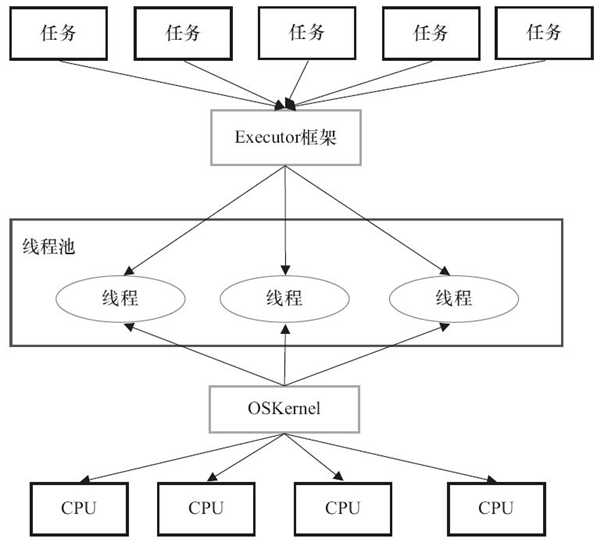
在HotSpot VM的线程模型中,Java线程(java.lang.Thread)被一对一映射为本地操作系统线程。Java线程启动时会创建一个本地操作系统线程;当该Java线程终止时,这个操作系统线程也会被回收。操作系统会调度所有线程并将它们分配给可用的CPU。
在上层,Java多线程程序通常把应用分解为若干个任务,然后使用用户级的调度器(Executor框架)将这些任务映射为固定数量的线程;在底层,操作系统内核将这些线程映射到硬件处理器上。
这种两级调度模型的示意图如图:
4.2 Executor的框架结构
Executor 框架主要由三大部分组成:
(1)任务
包括被执行任务需要实现的接口,Runnable接口或Callable接口
(2)任务的执行
包括任务执行机制的核心借口 Executor,以及继承自 Executor的 ExecutorService接口。Executor框架有两个关键类实现了 ExecutorService接口(ThreadPoolExecutor和ScheduledThreadPoolExecutor)
(3)异步计算的结果
包括接口Future和实现Future接口的FutureTask类
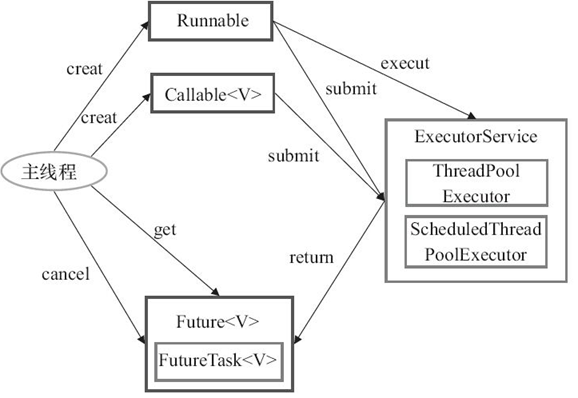
【Executor框架包含的主要类与接口如图所示】
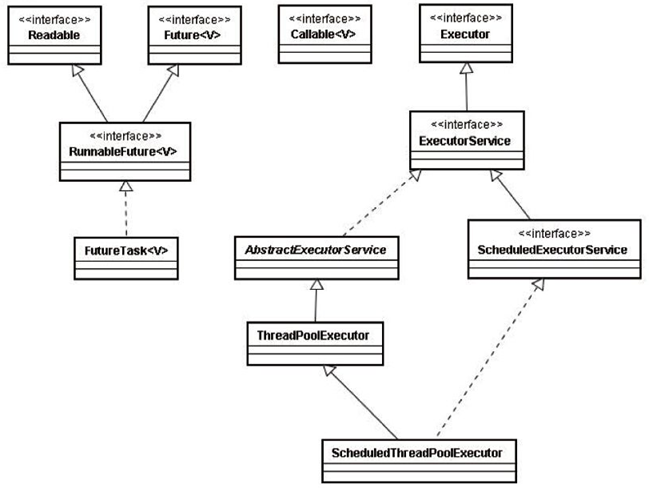
Executor:是一个接口,是 Executor 框架的基础,它将任务的提交与任务的执行分离开来ThreadPollExecutor:是线程池的核心实现类,用来执行被提交的任务ScheduledThreadPoolExecutor:是一个实现类,可以在给定的延迟后运行命令,或者定期执行命令Future接口和实现 Future 接口的FutureTask类,代表异步计算的结果Runnable接口和Callable接口的实现类,都可以被 ThreadPoolExecutor 或Scheduled-ThreadPoolExecutor 执行。
4.3 Executor 框架的使用
(1)主线程首先要创建实现Runnable或者Callable接口的任务对象。工具类Executors可以把一个Runnable对象封装为一个Callable对象。
(2)然后可以把Runnable对象直接交给ExecutorService执行(ExecutorService.execute(Runnable command));或者也可以把Runnable对象或Callable对象提交给ExecutorService执行(Executor-Service.submit(Runnable task)或ExecutorService.submit(Callable
(3)如果执行ExecutorService.submit(…),ExecutorService将返回一个实现Future接口的对象(到目前为止的JDK中,返回的是FutureTask对象)。由于FutureTask实现了Runnable,程序员也可以创建FutureTask,然后直接交给ExecutorService执行。
(4)最后,主线程可以执行FutureTask.get()方法来等待任务执行完成。主线程也可以执行FutureTask.cancel(boolean mayInterruptIfRunning)来取消此任务的执行。
【代码示例】
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolSimpleTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10,
200, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(5));
for(int i=0;i<15;i++){
MyTask myTask = new MyTask(i);
// executor.execute(myTask);
Future<?> submit = executor.submit(myTask);
System.out.println("线程池中线程数目:"+executor.getPoolSize()+",队列中等待执行的任务数目:"+
executor.getQueue().size()+",已执行完的任务数目:"+executor.getCompletedTaskCount());
}
executor.shutdown();
}
}
class MyTask implements Runnable {
private int taskNum;
public MyTask(int num) {
this.taskNum = num;
}
@Override
public void run() {
System.out.println("正在执行task " + taskNum);
try {
Thread.currentThread().sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("task " + taskNum + "执行完毕");
}
}
5、ThreadPoolExecutor
Executor框架最核心的类是ThreadPoolExecutor,它是线程池的实现类。通过Executor框架的工具类Executors,可以创建4种类型的ThreadPoolExecutor。
- FixedThreadPool
- SingleThreadExecutor
- CachedThreadPool
- 自定义创建的类型(最大的类型)
【问题】为什么同是 ThreadPoolExecutor 命名不同呢?(不同的pool都是return new ThreadPoolExecutor)
是因为 ThreadPoolExecutor 参数不同导致的。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
@NotNull
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
@NotNull
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
5.1 FixedThreadPool详解
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
FixedThreadPool被称为可重用固定线程数的线程池。FixedThreadPool的corePoolSize和maximumPoolSize都被设置为创建FixedThreadPool时指定的参数nThreads。
当线程池中的线程数大于corePoolSize时,keepAliveTime为多余的空闲线程等待新任务的最长时间,超过这个时间后多余的线程将被终止。这里把keepAliveTime设置为0L,意味着多余的空闲线程会被立即终止。FixedThreadPool的execute()方法的运行示意图如图所示。
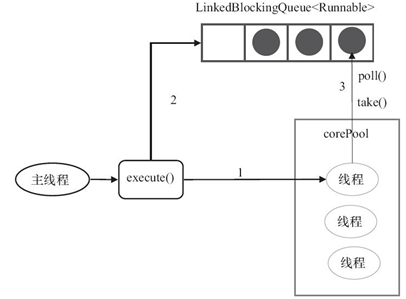
执行流程:
(1)如果当前运行的线程数少于corePoolSize,则创建新线程来执行任务。
(2)在线程池完成预热之后(当前运行的线程数等于corePoolSize),将任务加入LinkedBlockingQueue。
(3)线程执行完1中的任务后,会在循环中反复从LinkedBlockingQueue获取任务来执行。(明白了)
FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。使用无界队列作为工作队列会对线程池带来如下影响:
(1)当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中的线程数不会超过corePoolSize。
(2)由于1,使用无界队列时maximumPoolSize将是一个无效参数。
(3)由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
(4)由于使用无界队列,运行中的FixedThreadPool(未执行方法shutdown()或shutdownNow())不会拒绝任务(不会调用RejectedExecutionHandler.rejectedExecution方法)。
【问题】LinkedBkockingQueue到底是有界还是无界的?
想解决这个问题,首先我们要知道无界和有界代表的意义是什么?
有界队列:指在创建队列时,必须要传入一个指定的大小
无界队列:在创建的时候无需传入指定大小
而 LinkedBlockingQueue 的默认大小是:Integer.MAX_VALUE。
难道是一个有界队列吗?不是,此处正说明了它是无界队列
ArrayBlockingQueue arrayBlockingQueue = new ArrayBlockingQueue(10);//必须传入指定的最大容量
LinkedBlockingQueue linkedBlockingQueue = new LinkedBlockingQueue(); //创建无界队列,FixedThreadPool 创建的就是无界队列
LinkedBlockingQueue linkedBlockingQueue1 = new LinkedBlockingQueue(10); //创建有界队列
PriorityBlockingQueue priorityBlockingQueue = new PriorityBlockingQueue();
5.2 SingleThreadExecutor详解
SingleThreadExecutor是使用单个worker线程的Executor。
@NotNull
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
SingleThreadExecutor的corePoolSize和maximumPoolSize被设置为1。其他参数与FixedThreadPool相同。SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。SingleThreadExecutor使用无界队列作为工作队列对线程池带来的影响与FixedThreadPool相同,这里就不赘述了。
如果我们创建 FixedThreadPool的时候将线程设为 1的话,就跟我们SingleThreadPool有几乎一样的效果。
5.3 CachedThreadPool详解
CachedThreadPool是一个会根据需要创建新线程的线程池
@notNull
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
CachedThreadPool的corePoolSize被设置为0,即corePool为空;maximumPoolSize被设置为Integer.MAX_VALUE,即maximumPool是无界的。这里把keepAliveTime设置为60L,意味着CachedThreadPool中的空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。
FixedThreadPool和SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列。CachedThreadPool使用没有容量的SynchronousQueue作为线程池的工作队列,但CachedThreadPool的maximumPool是无界的。这意味着,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,CachedThreadPool会不断创建新线程。极端情况下,CachedThreadPool会因为创建过多线程而耗尽CPU和内存资源。
5.4 总结
对于fixed,single和 cache,我们在实际的工作中最多使用到的(相对于fixed和cache)是 single。
一般情况下,对于并发量不高的场景,并且需要单条异步线程进行处理的时候,会使用一下 single。
真正的业务处理中,如果使用线程池,99%的情况下,需要自定义线程池(自己传入参数)。只有1%的情况会使用fixed,single和 cache。在这1%里,single稍微多一些。
Fixed和 single 容易造成我们的quque的消息无限积压,还会导致无法触发拒绝策略。所以一般没人用;
Cache,可能高并发下,无法控制最高的线程创建数量,造成cpu和内存资源的消耗(消耗完)。 这种破线程池谁用?
这三个,仅仅是为了让我们创建线程池的时候方便一些,不代表他们很实用。
6、ScheduledThreadPoolExecutor
建议先不要看书。因为书籍《Java并发编程的艺术》里边的介绍非常杂乱。如果先看书的话,很多地方可能明白不了。书里边的介绍有些过于浅显了,没有说一些细节的问题。
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor。它主要用来在给定的延迟之后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor的功能与Timer类似,但ScheduledThreadPoolExecutor功能更强大、更灵活。Timer对应的是单个后台线程,而ScheduledThreadPoolExecutor可以在构造函数中指定多个对应的后台线程数(创建线程池)。
示例代码:ScheduledThreadPoolExecutorTest.java (这里边会有引申内容。)
import lombok.SneakyThrows;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ScheduledThreadPoolExecutorTest {
public static void main(String[] args) {
// 创建 ScheduledThreadPool的方式及源码
// ScheduledThreadPool 其实是我们 ThreadPoolExecutor的一个子类,所以构造函数使用的是 ThreadPool的
// 但是,它使用的是 delayQueue new DelayedWorkQueue()
// 这两种创建方式有什么不同呢?Executors.newScheduledThreadPool(5);调用的方法也是 new ScheduledThreadPoolExecutor(5);
// ScheduledThreadPoolExecutor 是我们的 ScheduledExecutorService 的一个子类
// 建议选择第一种创建方式 和 第三种创建方式。更倾向于第三种创建方式。
// ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(5);
// ScheduledExecutorService service = Executors.newScheduledThreadPool(5);
ScheduledThreadPoolExecutor pool
= (ScheduledThreadPoolExecutor) Executors.newScheduledThreadPool(5);
// schedule 方法只适用于 一次性的执行。一个任务只执行一次就完事儿了。
// pool.schedule(new STask(1), 5, TimeUnit.SECONDS);
// 如果我想要重复执行一个任务。怎么办?
// 这个方法是以固定的频率进行循环执行。5s以后开始第一次执行,之后每2秒再次执行一次。
// 这个方法不会考虑前一次执行的时间。
// 如果第一次执行的时间超过了时间间隔,那么不可以在预期的时间执行第二次。
//因为: 我们task 是周期执行的,每次执行完一次之后,我们的ScheduledThreadPoolExecutor会从新计算下次的执行时间
// 然后将下次的执行时间修改完后再次 add 到我们的 delayQUEUE 里。现在如果是一个 while循环,那么永远不能执行结束
//我们的ScheduledThreadPoolExecutor就没有办法再次的从新计算时间,并且从新添加到我们的delayqueue中。
pool.scheduleAtFixedRate(new STask(1), 5, 5, TimeUnit.SECONDS);
//5s以后开始第一次执行,执行完毕之后 2s 后开始执行第二次; 第二次执行完成后,2s后执行第三次。
// 考虑前一次执行的时间,只有前一次执行完成之后,才会计算2s的时间间隔。
// pool.scheduleWithFixedDelay(new STask(1), 5, 5, TimeUnit.SECONDS);
}
private static class STask implements Runnable {
private int taksNum;
public STask(int taksNum) {
this.taksNum = taksNum;
}
@SneakyThrows
@Override
public void run() {
System.out.println("Scheduled task is running! taskNum = " + taksNum);
Thread.sleep(6000);
}
}
}
7、FutureTask
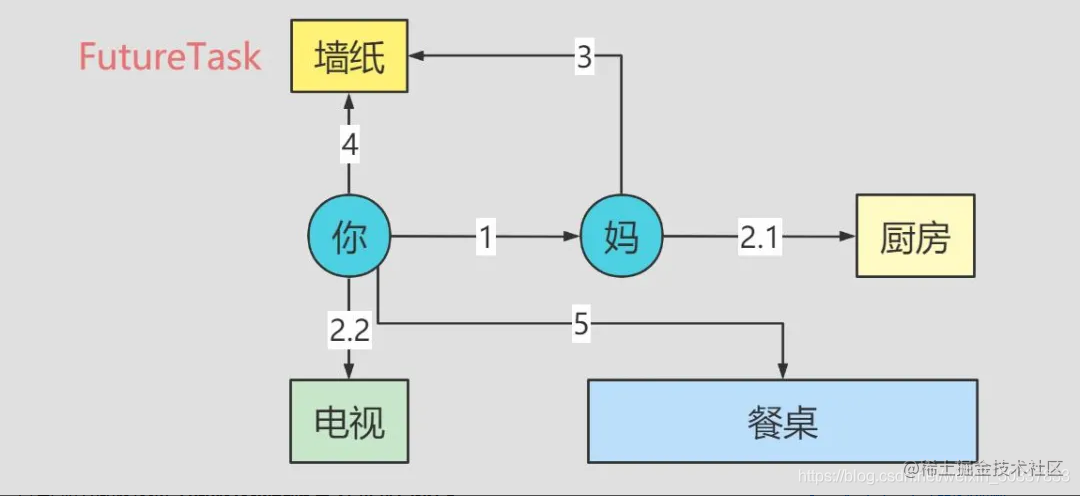
有一天你饿了,想吃饭,但是你不会做,这时候你就跟你妈说:妈,我饿了,我要吃饭。然后你妈就去厨房做饭,同时你就去看球赛了(但是你不想被打扰,就跟你妈说,饭做好了贴个墙纸就好了)。你妈把饭做好并端到餐桌上了,并贴了个墙纸,也不告诉你,然后你饿的受不了了,看了一下墙,已经有贴纸了,你就去餐桌上吃饭了,如果没有贴纸你就继续看球赛。FutureTask就是这张墙纸。
Future接口和实现Future接口的FutureTask类,代表异步计算的结果。
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask;
public class FutureTaskTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
TaskTest task = new TaskTest();
// 放到线程池中执行
// Future submit = Executors.newSingleThreadExecutor().submit(task);
// System.out.println(submit.get());
FutureTask<String> futureTask = new FutureTask<>(task);
futureTask.run();
System.out.println(futureTask.get());
}
private static class TaskTest implements Callable {
@Override
public String call() throws Exception {
Thread.sleep(5000);
return "Hello world!";
}
}
}
FutureTask除了实现Future接口外,还实现了Runnable接口。因此,FutureTask可以交给Executor执行,也可以由调用线程直接执行(FutureTask.run())。根据FutureTask.run()方法被执行的时机,FutureTask可以处于下面3种状态。
(1)未启动。FutureTask.run()方法还没有被执行之前,FutureTask处于未启动状态。当创建一个FutureTask,且没有执行FutureTask.run()方法之前,这个FutureTask处于未启动状态。
(2)已启动。FutureTask.run()方法被执行的过程中,FutureTask处于已启动状态。
(3)已完成。FutureTask.run()方法执行完后正常结束,或被取消(FutureTask.cancel(…)),或执行FutureTask.run()方法时抛出异常而异常结束,FutureTask处于已完成状态。
当FutureTask处于未启动或已启动状态时,执行FutureTask.get()方法将导致调用线程阻塞;当FutureTask处于已完成状态时,执行FutureTask.get()方法将导致调用线程立即返回结果或抛出异常。
当FutureTask处于未启动状态时,执行FutureTask.cancel()方法将导致此任务永远不会被执行;当FutureTask处于已启动状态时,执行FutureTask.cancel(true)方法将以中断执行此任务线程的方式来试图停止任务;当FutureTask处于已启动状态时,执行FutureTask.cancel(false)方法将不会对正在执行此任务的线程产生影响(让正在执行的任务运行完成);当FutureTask处于已完成状态时,执行FutureTask.cancel(…)方法将返回false。(FutureTaskTest.java)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号