17、Object类
一、hashcode()方法
1、什么是hashcode()方法?
public native int hashCode();
hashcode()的返回值是实例对象运行时的内存地址(narive表示该方法为本地方法)
2、hash算法
-
什么是hash算法:hash(散列),把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出值就是散列值
-
hash算法的特点
- 只能通过原文计算出hash值,而且每次计算都一样,但不能通过hash值计算原文
- 原文的微小变化就是hash值发生巨大变化
- 一个好的hash算法应该尽量避免发生hash值重复的情况,也叫hash碰撞
-
hahs的用途
- 密码的保存:实际的工程中一般不存储明文密码,而是将密码使用hash算法计算成hash值进行保存,这样即使密码丢失也不会使密码完全曝光
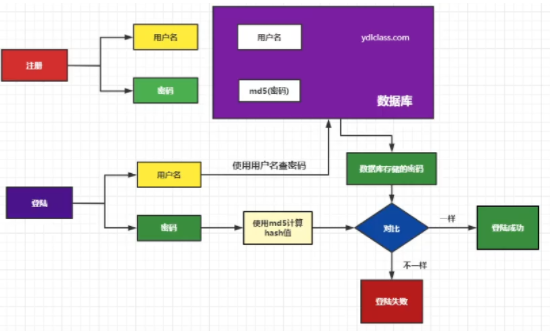
- 文件的校验:检查数据的一致性
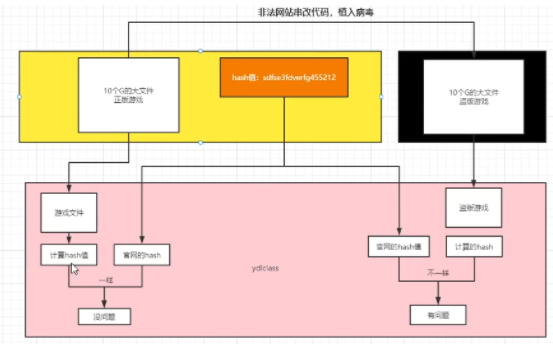
二、toString()方法
将一个实例对象转换成一个可打印的字符串
- 默认返回:全类名 + @ + 哈希值的十六进制
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
-
子类往往重写toString方法,用于返回对象的属性信息——使用
alt+insert即可重写 -
当直接输出对象时,toString方法被默认调用
三、equals()方法和“==”
1、“==”是一个比较运算符
- 既可以判断基本类型,有可以判断引用类型
- 判断基本类型时,判断值是否相等
- 判断引用类型时,判断地址是否相等,即判断是否为同一对象
2、equals方法
public boolean equals(Object obj) {
return (this == obj);
}
equals方法是Object类中的方法,只能判断引用类型- 默认判断地址是否相等,子类一般重写了该方法,用于判断内容是否相等
四、finalize()方法
(1)当对象被回收时,系统自动调用该对象的finalize方法,子类可以重写该方法,做一些释放资源的动作
(2)回收机制:当某个对象没有任何引用时,则JVM认为此对象为垃圾对象,会使用垃圾回收机制来销毁该对象,销毁前,会调用finalize方法
(3)垃圾回收机制的调用,由系统来决定(系统有自己的GC算法),也可以通过System.gc()主动触发
注:实际开发中几乎不会运用
五、clone()方法
克隆就是在内存里面赋值一个实例对象,但是Object的克隆方法只能是浅拷贝,同时必须实现Cloneable接口
六、浅拷贝和深拷贝
1、浅拷贝
(1) 浅拷贝介绍
浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。即默认拷贝构造函数只是对对象进行浅拷贝复制(逐个成员依次拷贝),即只复制对象空间而不复制资源。
(2) 浅拷贝特点
(1) 对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个。
(2) 对于引用类型,比如数组或者类对象,因为引用类型是引用传递,所以浅拷贝只是把内存地址赋值给了成员变量,它们指向了同一内存空间。改变其中一个,会对另外一个也产生影响
2、深拷贝
1. 深拷贝介绍
通过上面的例子可以看到,浅拷贝会带来数据安全方面的隐患,例如我们只是想修改了 studentB 的 subject,但是 studentA 的 subject 也被修改了,因为它们都是指向的同一个地址。所以,此种情况下,我们需要用到深拷贝。
深拷贝,在拷贝引用类型成员变量时,为引用类型的数据成员另辟了一个独立的内存空间,实现真正内容上的拷贝。
2. 深拷贝特点
(1) 对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个(和浅拷贝一样)。
(2) 对于引用类型,比如数组或者类对象,深拷贝会新建一个对象空间,然后拷贝里面的内容,所以它们指向了不同的内存空间。改变其中一个,不会对另外一个也产生影响。
(3) 对于有多层对象的,每个对象都需要实现 Cloneable 并重写 clone() 方法,进而实现了对象的串行层层拷贝。
(4) 深拷贝相比于浅拷贝速度较慢并且花销较大。

