HashSet源码分析
一、HashSet概述
(1)HashSet实现Set接口,底层基于HashMap实现,但与HashMap不同在于HashMap存储键值对,HashSet仅存储对象——key
(2)HashSet使用成员对象来计算hashcode值
(3)HashSet的特点
- 无序性
- 唯一性(允许使用null)
- 本质上讲就是HashMap
- HashSet没有提供get方法,和HashMap一样,因为Set内部是无序的,只能通过迭代的方式获得
二、源码分析
1、继承结构
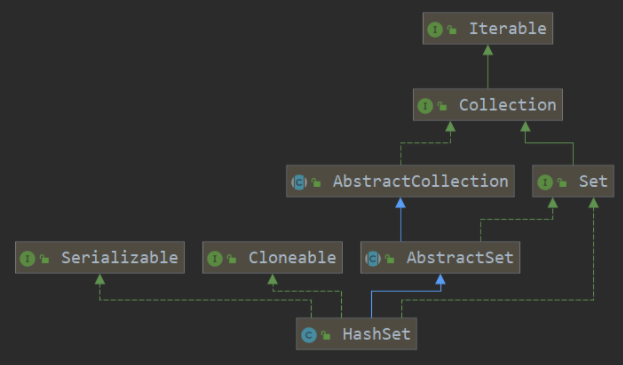
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.SerializableP{}
(1)继承
- AbstractSet:与ArrayList和LinkedList一样,贼他们的抽象父类中,都提供了equals方法和hashCode方法,本身并不实现这两个方法
AbstractSet中的equals()
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Set))//o没有实现Set接口
return false;//返回false
Collection<?> c = (Collection<?>) o;//向下转换
if (c.size() != size())//元素个数不相等
return false;//返回false
try {
return containsAll(c);//组个判断集合是否包含其他元素
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
(2)接口
- Serializable接口,表明它支持序列化
- Cloneable接口,表明它支持克隆,可以调用超类的clone()方法进行浅拷贝
2、属性
//版本号
static final long serialVersionUID = -5024744406713321676L;
//底层使用HashMap存储数据
private transient HashMap<E,Object> map;
//用来填充底层数据结构HashMap中的value,因为HashSet只用key存储数据
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
3、构造器
(1)无参构造器
构建了一个空的set集合,其底层的HashMap实例使用默认的初始容量(16)和加载因子(0.75)
public HashSet() {
map = new HashMap<>();//实例化了一个HashMap
}
(2)HashSet(Collection<? extends E> c)
使用HashMap(int)构造器,创建了一个新的HashSet
初始容量由对象c的临界值和默认初始化容量的最大值决定
临界值 = 数组长度容量 * 负载因子
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
AbstractCollection类中的addAll方法
public boolean addAll(Collection<? extends E> c) {
boolean modified = false;//失败返回false
for (E e : c)
if (add(e))//添加成功
modified = true;//返回true
return modified;
}
(3)HashSet(int initialCapacity)
使用HashMap(int)构造器,创建了一个新的HashSet
初始化容量为initialCapacity
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
(4)HashSet((int initialCapacity, float loadFactor)
使用HashMap(int, float)构造器,创建了一个新的HashSet
初始化容量为initialCapacity
负载因子为loadFactor
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
4、方法
4.1 add(E):boolean
添加一个新的元素
调用HashMap的put(Key, Value):V方法,进行添加,添加成功返回null,覆盖返回旧值
PRESENT用来填充底层数据结构HashMap中的value,因为HashSet只用key存储数据
public boolean add(E e) {
return map.put(e, PRESENT)==null;//动态绑定,执行HashMap的put方法
}
4.2 remove(Object):boolean
删除一个元素
调用HashMap的remove(Object):V的方法,移除成功返回被删除的键对应的值,删除失败返回null
HashSet底层HashMap中所有键值对的值都是PRESENT
如果remove返回PRESENT说明已存在该元素,且删除成功
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
4.3 size():int
返回HashMap中元素的个数
public int size() {
return size;
}
4.4 contains(Object):boolean
调用HashMap的containsKey()方法,判断HashMap中是否包含某个key
这里检查set中是否包含某个元素
public boolean contains(Object o) {
return map.containsKey(o);
}
4.5 isEmpty():boolean
调用HashMap的isEmpty方法,判断HashMap是否为空
public boolean isEmpty() {
return map.isEmpty();
}
4.6 iterator():iterator e
public Iterator<E> iterator() {
return map.keySet().iterator();
}
三、总结
(1)①HashSet内部通过使用HashMap的键来存储集合中的元素,而且内部的HashMap的所有值都是null。(因为在为HashSet添加元素的时候,内部HashMap的值都PRESENT),而PRESENT在实例域的地方直接初始化了,而且不允许改变
(2)hashSet底层是基于hashMap实现的
(3)hashSet存储的元素对应hashMap的key,因为hashMap不能存储重复的Key,所以hashSet不能存放重复元素,HashMap中的key不可重复,重复的key会覆盖其value
(4)由于hashMap的key是基于hashCode存储对象的,所以hashSet中存放的对象也是无序的
(5)hashSet也没有提供get方法,可以通过Iterator迭代器获取数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号