恼人的“龙天“(䶮)--谈谈从GBK转到GB18030的特殊情况
背景
最近在做一个去O迁移适配,刚好也有友商在一起做,两边测试方式不一样。友商先遇到了一个问题,就是在ORACLE中某个的2字节GBK字符到迁移到友商的库中变成了4字节,刚好那个字段在这个字是2字节的时候,已经存满了,转换成4字节后就会超长,死活都导不进去,经分析,是因为友商建库时选择了GB18030字符集,可是为什么2字节的GBK字符到了GB18030会变成4字节?而我在MogDB中建GBK的库,这个字能正常导入,不会超长。
这个字有何神奇之处?
在经过一些调查及测试验证后,特整理此文。
分析过程
这个字的外形是 ,上面是“龙”,下面是“天”。其实正常的输入法是可以输入这个外形的字的,但是,实际上你用输入法输入的这个字,并不是我上面提到的这个字,它们只是外形完全一样的“两个字”,这里我说“两个字”是对于unicode编码而言,或者换种说法,这个外形的字,在GB(GBK/GB18030)字符集的演进历史中,曾经占据了两个unicode编码,在windows中文区域里,使用ANSI时 ,这两个unicode编码的字符都可以正常显示字形。而在流行的UTF8编码的网页上,其中一个字可能是无法正常显示的,而这个字就是数据库迁移中存在问题的字,而这个字的起源,要追述到GBK编码定义

(https://www.zhihu.com/question/403694151)
如上图 右下角的位置,GBK+FE9F 这个编码,对应的unicode编码为U+E863,然后我们去查下unicode官网,找找这个编码,
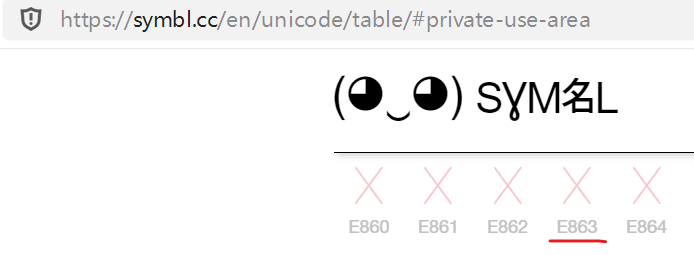
在unicode官网里,这个编码并没有字形对应,而且该位置属于PUA(私人编码区)。
我们再来看GB18030-2022中U+E863是什么
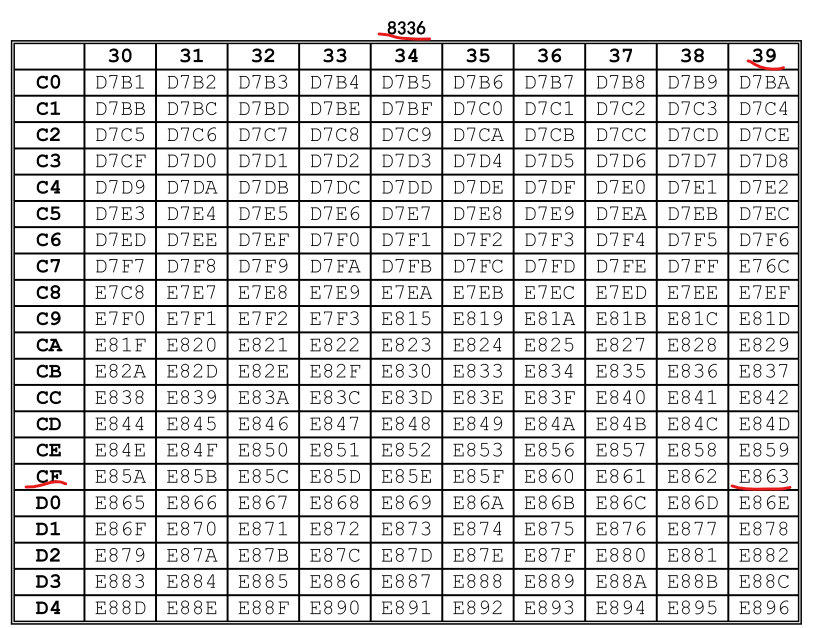
U+E863对应的GB18030编码为 GB18030+8336CF39 ,此处也没有字形。也就是说,GBK编码的FE9F这个字,既不被UNICODE承认,也不在最新的国家强制标准GB18030-2022里。
可是,不是说GB18030比GBK能支持更多的生僻字么?其实,这个字并不是没有了,而是GB18030把它"直接兼容"了。
我们直接用GBK编码的FE9F在GB18030标准里找
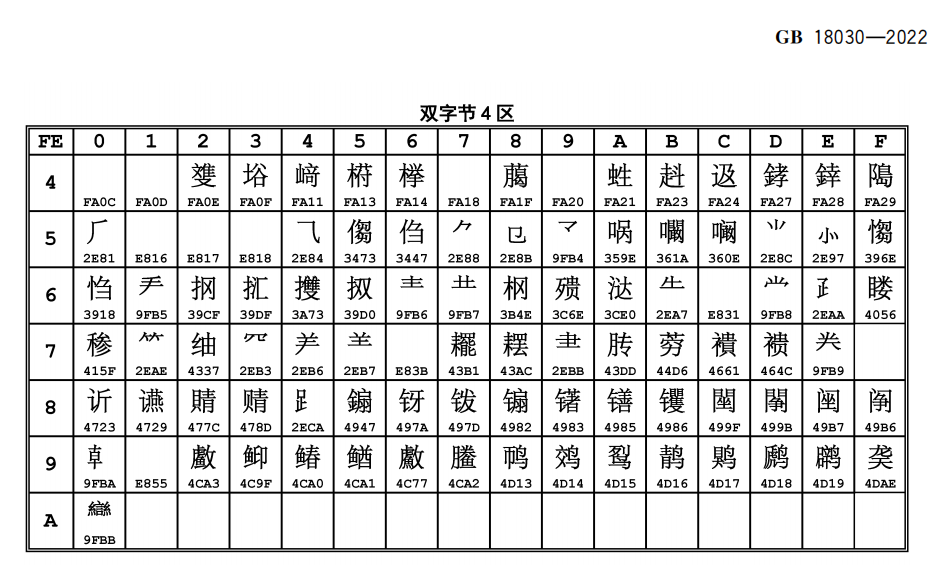
可以看到这里的确有对应的字形,而且就是“龙天”,这个字对应的UNICODE编码为U+4DAE,于是我们再去UNICODE官网找找

果然在这里也能找到。
我们以UNICODE编码来整理一下这两个字的各种编码(由于这个字在UTF8中没有字形对应,所以可能部分网页上会显示方框,如果复制出来放到中国区域的windows的记事本里,就可以正常显示对应的字,因为当成GBK显示了)
| 䶮 | | |
|---|---|---|
| UNICODE | 4DAE | E863 |
| UTF8 | E4B6AE | EEA1A3 |
| GB18030 | FE9F | 8336CF39 |
| GBK | 无 | FE9F |
然后我测试了,在较新版本的ORACLE中,使用UTL_I18N里的raw_to_char/string_to_raw函数,也可以得到上述相同的结果
SQL> WITH T AS
2 (SELECT UTL_I18N.RAW_TO_CHAR('4DAE','AL16UTF16') U4DAE ,
3 UTL_I18N.RAW_TO_CHAR('E863','AL16UTF16') UE863 FROM DUAL)
4 SELECT 'AL32UTF8' encoding, UTL_I18N.STRING_TO_RAW(U4DAE,'AL32UTF8') "4DAE",
5 UTL_I18N.STRING_TO_RAW(UE863,'AL32UTF8') "E863" FROM T
6 UNION ALL
7 SELECT 'ZHS32GB18030',UTL_I18N.STRING_TO_RAW(U4DAE,'ZHS32GB18030'),
8 UTL_I18N.STRING_TO_RAW(UE863,'ZHS32GB18030') FROM T
9 UNION ALL
10 SELECT 'ZHS16GBK',UTL_I18N.STRING_TO_RAW(U4DAE,'ZHS16GBK'),
11 UTL_I18N.STRING_TO_RAW(UE863,'ZHS16GBK') FROM T;
ENCODING 4DAE E863
------------ ------- ---------
AL32UTF8 E4B6AE EEA1A3
ZHS32GB18030 FE9F 8336CF39
ZHS16GBK A3BF FE9F
SQL>
这里注意ORACLE中的 U+4DAE 在ZHS16GBK其实并不是 "A3BF",而是因为并没有对应的字符,ORACLE把它转换成了全角问号(转成什么符号与当前环境的区域语言有关)。
引发的问题
所以,这里出现一个很尴尬的情况:
在去O过程中,原本在Oracle中使用的是GBK字符集,存入了GBK字符集支持的"FE9F"这个字符,如果迁移的目标库也是使用GBK字符集,那当然皆大欢喜。可是GBK目前已被国家标准废弃,必须要使用GB18030,而编码转换软件如果按照UNICODE标准进行转换,那么这个字将被转换成GB18030的"8336CF39" ,且不说数据可能会变长导致无法存入数据库,更大的问题是,GB18030中的"8336CF39"并没有对应的字形,会导致很多软件的UI无法显示这个字!
于是对于GBK和GB18030的转换,就不应该使用UNICODE的码点对应关系来进行转换了,这对于现有的绝大多数会涉及到文本转码的软件带来灾难。现有很多开发语言的内部都是默认使用的UTF8(比如JAVA、GO),各种字符的转入转出几乎都是通过UNICODE来进行中转,遇到这种转换的场景,很有可能会出现问题。相关报道有很多,这里随便列两篇:
2.# 一个名字叫“䶮”的人的苦恼:开不了银行账户,用不了微信、支付宝
处理建议
- 对于软件开发商,转码软件或者转码模块应该单独编写GBK到GB18030的转码规则。比如本文的例子,GBK的 "FE9F" ,就应该映射到 GB18030的 "FE9F" ,而非通过UNICODE编码进行中转得到的 "8336CF39";或者更新GBK的映射,使其unicode码和GB18030的映射关系一致(windows就是这么处理的 : windows-936-2000)
- 对于对被强制执行标准的软件用户,应提前采取措施应对GBK编码转到GB18030所带来的影响(原本用UTF8转到GB18030的没有此类问题),不是所有的软件开发商都会细致地去考虑编码转换问题,GB18030强制标准只要求能支持输入输出标准里的字符,并不要求支持和其他字符集进行转换。
- 对于所有的新软件开发,不应再使用GBK字符集,推荐使用UTF8(或者GB18030)
- 本文作者: DarkAthena
- 本文链接: https://www.darkathena.top/archives/longtian-yan-encoding-gbk-gb18030
- 版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 3.0 许可协议。转载请注明出处!
posted on 2024-01-12 19:03 DarkAthena 阅读(343) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号