【openGauss】记录一次关于对openGauss(postgresql)数据类型的摸索经过及感想
背景
起因是这样的,本来想写一篇文章来描述Oracle及openGauss中raw/blob类型的差异,但是写到一半,发现对官方文档中raw存储的是十六进制字符串这点有点不理解
https://opengauss.org/zh/docs/3.0.0/docs/Developerguide/%E4%BA%8C%E8%BF%9B%E5%88%B6%E7%B1%BB%E5%9E%8B.html
它到底是存储的实际数据的二进制数据?还是实际数据转成十六进制文本再把文本转换成二进制数据存储?
思考经过
如果是在oracle里,可以使用dump函数来获得实际存储的信息,但是在openGauss/pg里却没有找到对应的函数(可能有,但我没找到)。于是我想到compat-tools里提供了dump的兼容函数,于是试着查了一下,发现报错,原因是这个函数内直接用"::bytea"来将输入参数强制转换成二进制类型,但实际上并不是所有类型都能这么转的,甚至连自带的int类型都不能直接转换成bytea
然后想到,我之前整理raw类型相关的函数时,有个rawsend可以把raw转换成bytea,而且貌似看见过其他的以type名称开头以send结尾的函数,我就在想,pg是不是有什么机制,要求所有的类型都要有send函数,而且极有可能有个配置存储了类型与send函数之间的关系,自然而然的联想到会不会有个叫pg_type的表里面刚好存了?
一查,果然
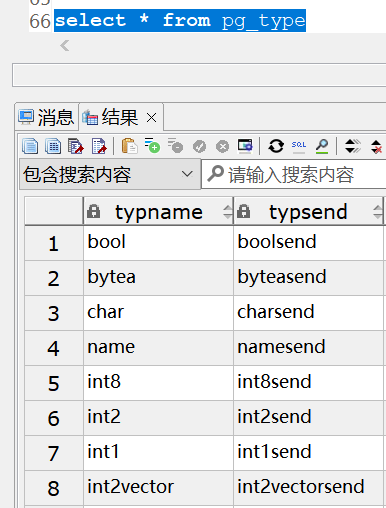
然后我顺便去搜了下官方文档,发现官方文档其实有介绍这个表
https://opengauss.org/zh/docs/3.0.0/docs/Developerguide/PG_TYPE.html
| 名称 | 类型 | 描述 |
|---|---|---|
| typinput | regproc | 输入转换函数(文本格式)。 |
| typoutput | regproc | 输出转换函数(文本格式)。 |
| typreceive | regproc | 输入转换函数(二进制格式),如果没有则为0。 |
| typsend | regproc | 输出转换函数(二进制格式),如果没有则为0。 |
(关于如何创建内置类型以及如何绑定类型与转换函数,可以参考pg文档http://postgres.cn/docs/13/xtypes.html)
解决方案近在眼前了,现在只要能找到一种方式,能识别anyelement类型的实际类型,就能搞定任意类型转bytea了。
可惜的是,搜索引擎不给力,没搜到。
于是我在同事群里问,然后马上有同事告诉我是pg_typeof,然后我立马去搜官方文档,
https://opengauss.org/zh/docs/3.0.0/docs/Developerguide/系统信息函数.html
pg_typeof(any)
描述:获取任何值的数据类型。
返回类型:regtype
备注:pg_typeof返回传递给他的值的数据类型OID。这可能有助于故障排除或动态构造SQL查询。声明此函数返回regtype,这是一个OID别名类型(请参考对象标识符类型);这意味着它是一个为了比较而显示类型名称的OID。
虽然查出来是个描述,但它实际上是个OID,于是我马上写了下面这个极其简单的函数
解决方案
create function any_send(anyelement)
return bytea
IS
v_typsend text;
v_result bytea;
begin
select typsend into v_typsend from pg_type
where oid= pg_typeof($1);
EXECUTE 'select '||v_typsend||'(:1)' into v_result using $1;
return v_result;
end;
/
select any_send('1234FF'::raw);
---\x1234FF
看似到这里,我最前面的问题已经解决了,但下一步我的实验,让我陷入了更深的困惑。
困惑
在orafce插件里,也有dump这个函数,我尝试使用这个dump函数转换了一些值,但它解析出来的十进制转换成十六进制的值,与我用上面这个函数得到的十六进制值,并不一致。而且我发现无论输入什么类型,它的输入其实只有两种类型,一种是按bytea的二进制数据,其余的全部是按文本,包括字符串、数值(包括浮点)、时间等。
select public.dump(11111.1::NUMERIC),public.dump('11111.1');
上面这个sql,两个查出来的都是
Typ=25 Len=11: 44,0,0,0,49,49,49,49,49,46,49
"Typ=25"其实就是oid=25的pg_type,即text类型,"Len=11"表示长度为11,前4个字节"44,0,0,0"其实也是长度信息,44除以4就是11(已验证加1位数,就变成48了,再加1位数就变成52了,因此判断这个44也是表示长度),后面的7个字节其实就是'11111.1'这个文本.....把数字都当文本了.....
然后我又测试了一下把值存到表里,再用orafce的dump函数来查
create table dump_test(n NUMERIC,t text);
insert into dump_test values (11111.1::NUMERIC,'11111.1')
select public.dump(n), public.dump(t) from dump_test;
Typ=25 Len=11: 44,0,0,0,49,49,49,49,49,46,49 Typ=25 Len=8: 17,49,49,49,49,49,46,49
结果长度发生了变化,但类型和值串依旧都还是文本表示。
然后再查下float类型和int类型
select public.dump(1::float),public.dump(1::int)
Typ=25 Len=5: 20,0,0,0,49 Typ=25 Len=5: 20,0,0,0,49
Oracle里绝对不会这样!不同类型数据的二进制编码规则应该都是不一样的,甚至同样是数字的number类型和integer类型,存同样的值,对应的二进制数据也应该不一样。(这篇文章里有介绍number和integer类型是如何存储的https://www.darkathena.top/archives/about-utl-raw-and-emulate-cal)
此时,我脑海里冒出了两种可能性
- orafce这个插件的dump函数写得不对
- postgresql的机制就是除了bytea以外的数据类型全部当文本
首先,我觉得2不太可能,因为我以前查过pg官方文档里有描述float是按IEEE标准754二进制浮点算术来处理的,而orafce的dump函数查出来却是文本的"1",明显不合理。
于是我把目光聚焦到orafce这个插件上,这个插件是开源的,我先克隆下来看看
https://github.com/orafce/orafce
然后找到它调用的函数
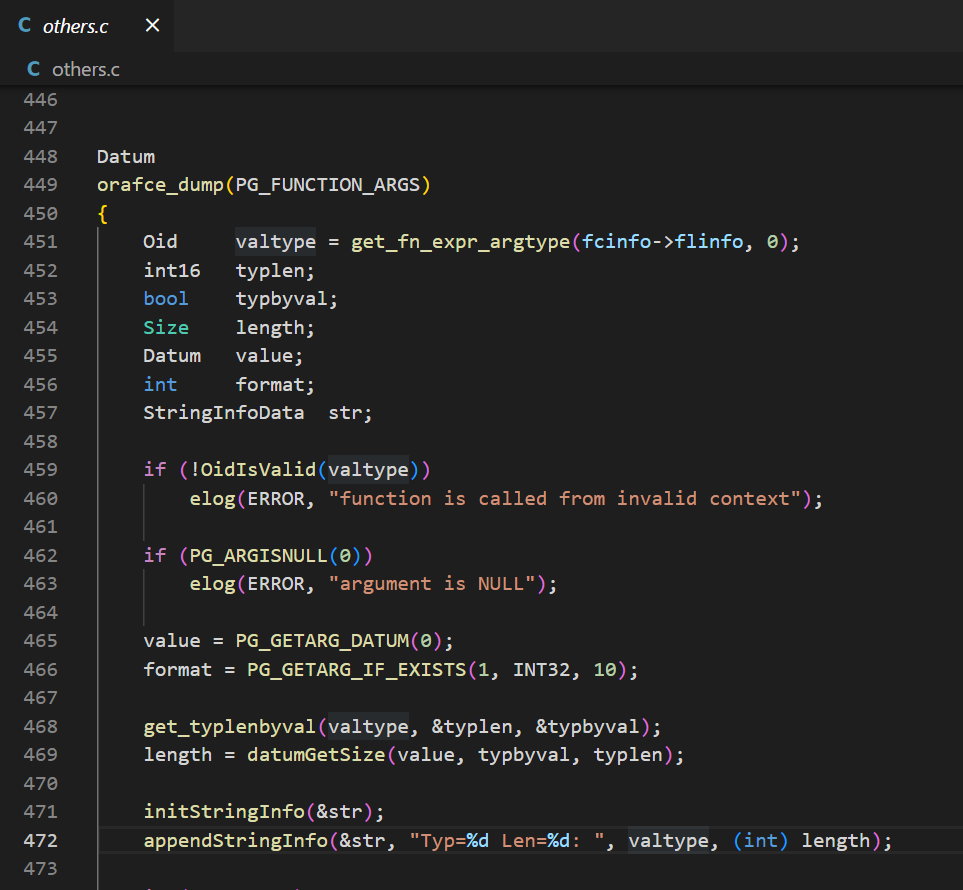
可以看到它这里使用了get_fn_expr_argtype来获取类型,而这个函数同样大量出现在pg数据库源码内,其中就包括了前面提到的pg_typeof函数。

可是,pg_typeof能输出正确的类型,而orafce的dump输出的却是错误的类型,那么肯定还有哪里不一样。
可惜我知识水平能力只能到这里了。
总结
其实可以发现,这篇文章里,我大部分是靠逻辑推理加一些经验,而非书本知识的积累。单靠逻辑的确是可以处理很多问题的,因为书本和文档并不会把所有相关的东西都串起来,就算去学了PG学了C语言,也不一定会想到能用我上面那个自定义函数的方法来获得所有类型的二进制数据,也不会去挖掘出orafce这个插件的问题。
当然,最终,为什么orafce这个插件输出结果不对的原因,我还是没找到,这一块的确是我知识的欠缺,有待加强。但靠着这一系列的逻辑推理,我的确也已经找到了文章最开始问题的答案。所以,个人觉得,相比书本知识,经验和逻辑能力同样重要。
另外,如果有个团队,且团队的成员能互相补足短板,比如我找会pg的同事得到了一个pg里的函数,同样也可以找C语言厉害的同事进行咨询,这样没准也可以让这个问题画上一个完美的句号。
我刚到新公司,虽然目前同事间还不太熟,但我知道这个团队一定有很多特定技术方向上的牛人,之后打算参与更多部门交叉项目,可不能浪费在这个"人才知识库"里的宝贵时间。
- 本文作者: DarkAthena
- 本文链接: https://www.darkathena.top/archives/think-about-opengauss-datatype
- 版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 3.0 许可协议。转载请注明出处!
posted on 2022-05-14 01:38 DarkAthena 阅读(190) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号