【ORACLE】关于多态表函数PTF(Polymorphic Table Functions)的使用
前言
从ORACLE 18C开始,ORACLE添加了PTF功能,目前在关系型数据库中,只有ORACLE支持此功能,简单来说,这个功能就是传入一个表作为参数,返回一个查询结果,而返回的这个表可以进行各种各样的定义或者修改,比如让返回的结果中自动屏蔽某些字段、自动对所有字段进行TRIM、自动对所有字段进行NVL、自动对所有number字段保留4位小数、自动添加一些字段、自动将所有date类型的字段修改为VARCHAR2类型,而且值得一提的是,一旦创建一个这样的函数,那么这个函数对所有的例子都通用,下面举几个例子来说明这个函数怎么使用。
1.将要查询的表中的所有date类型格式化成VARCHAR2类型输出,其他字段保持不变
众所周知,oracle中的date类型是个让人又爱又恨的类型,计算日期超方便,既可以表示年月日又可以表示年月日时分秒,麻烦的是,查询date类型默认输出的值是根据会话环境变量自动格式化的,经常会出现 “23-APR-21”或者“23-四月-21”这样的内容,在与其他系统进行数据交换时,经常会忘记使用"to_char"函数对日期进行格式化,导致其他系统接收失败,而且一个查询sql中date类型的字段多了,也要写好多个“to_char”,那么,有没有一种方式可以通用的,将所有要查询的数据中的date类型自动的进行to_char呢?
--先创建一个包说明
CREATE OR REPLACE PACKAGE ptf_date_to_char AS
FUNCTION describe(tab IN OUT dbms_tf.table_t)RETURN dbms_tf.describe_t;
PROCEDURE FETCH_ROWS;
END ptf_date_to_char;
/
--然后创建一个包体
CREATE OR REPLACE PACKAGE BODY ptf_date_to_char AS
FUNCTION describe(tab IN OUT dbms_tf.table_t) RETURN dbms_tf.describe_t AS
new_cols DBMS_TF.COLUMNS_NEW_T;
BEGIN
FOR i IN 1 .. tab.column.count LOOP --对所有字段循环
IF tab.column(i).description.type IN (dbms_tf.type_date) THEN --如果字段是日期类型
tab.column(i).pass_through := FALSE;
tab.column(i).for_read := TRUE; --是否多态表的列
NEW_COLS(i) := DBMS_TF.COLUMN_METADATA_T(name => tab.column(i).description.name, --字段名不变
type => DBMS_TF.TYPE_VARCHAR2 --字段类型改成varchar2
);
END IF;
END LOOP;
RETURN DBMS_TF.describe_t(new_columns => new_cols,
row_replication => true);
END;
PROCEDURE FETCH_ROWS AS
inp_rs DBMS_TF.row_set_t;
out_rs DBMS_TF.row_set_t;
rows PLS_INTEGER;
BEGIN
--只有上面进入了NEW_COLS的字段才会执行下面这段,其他字段保持不变
--inp_rs 表示原始数据
--out_rs 表示要输出的数据,默认情况下为空
DBMS_TF.get_row_set(inp_rs, rows); --获取原始数据
FOR c IN 1 .. inp_rs.count() LOOP --对列进行循环
FOR r IN 1 .. rows LOOP --对行进行循环
if inp_rs(c).tab_date(r) = trunc(inp_rs(c).tab_date(r)) then
--这里做了个特殊处理,兼容年月日和年月日时分秒两种
out_rs(c).tab_varchar2(r) := to_char((inp_rs(c).tab_date(r)),
'yyyy-mm-dd');
else
out_rs(c).tab_varchar2(r) := to_char((inp_rs(c).tab_date(r)),
'yyyy-mm-dd hh24:mi:ss');
end if;
END LOOP;
END LOOP;
DBMS_TF.put_row_set(out_rs, replication_factor => 1);
END;
END ptf_date_to_char;
/
--再创建个供直接调用的函数
CREATE OR REPLACE FUNCTION ptf_date_to_char_F(tab TABLE)
RETURN TABLE pipelined row polymorphic USING ptf_date_to_char;
/
以上准备工作就做好了,让我们来测试一下
select * from ptf_date_to_char_F(hr.job_history);
| EMPLOYEE_ID | JOB_ID | DEPARTMENT_ID | START_DATE | END_DATE |
|---|---|---|---|---|
| 102 | IT_PROG | 60 | 2001-01-13 | 2006-07-24 |
| 101 | AC_ACCOUNT | 110 | 1997-09-21 | 2001-10-27 |
| 101 | AC_MGR | 110 | 2001-10-28 | 2005-03-15 |
| 201 | MK_REP | 20 | 2004-02-17 | 2007-12-19 |
| 114 | ST_CLERK | 50 | 2006-03-24 | 2007-12-31 |
| 122 | ST_CLERK | 50 | 2007-01-01 | 2007-12-31 |
| 200 | AD_ASST | 90 | 1995-09-17 | 2001-06-17 |
| 176 | SA_REP | 80 | 2006-03-24 | 2006-12-31 |
| 176 | SA_MAN | 80 | 2007-01-01 | 2007-12-31 |
| 200 | AC_ACCOUNT | 90 | 2002-07-01 | 2006-12-31 |
这样好像看不出字段类型,没关系,我们用这个sql创建一个表就知道了
create table temp_test as
select * from ptf_date_to_char_F(hr.job_history);
select TABLE_NAME, COLUMN_NAME, DATA_TYPE,DATA_LENGTH,COLUMN_ID
from DBA_TAB_COLS WHERE TABLE_NAME = 'TEMP_TEST';
| TABLE_NAME | COLUMN_NAME | DATA_TYPE | DATA_LENGTH | COLUMN_ID |
|---|---|---|---|---|
| TEMP_TEST | EMPLOYEE_ID | NUMBER | 22 | 1 |
| TEMP_TEST | JOB_ID | VARCHAR2 | 10 | 2 |
| TEMP_TEST | DEPARTMENT_ID | NUMBER | 22 | 3 |
| TEMP_TEST | START_DATE | VARCHAR2 | 4000 | 4 |
| TEMP_TEST | END_DATE | VARCHAR2 | 4000 | 5 |
对比下原表
select TABLE_NAME, COLUMN_NAME, DATA_TYPE,DATA_LENGTH,COLUMN_ID
from DBA_TAB_COLS WHERE TABLE_NAME = 'JOB_HISTORY';
| TABLE_NAME | COLUMN_NAME | DATA_TYPE | DATA_LENGTH | COLUMN_ID |
|---|---|---|---|---|
| JOB_HISTORY | EMPLOYEE_ID | NUMBER | 22 | 1 |
| JOB_HISTORY | START_DATE | DATE | 7 | 2 |
| JOB_HISTORY | END_DATE | DATE | 7 | 3 |
| JOB_HISTORY | JOB_ID | VARCHAR2 | 10 | 4 |
| JOB_HISTORY | DEPARTMENT_ID | NUMBER | 22 | 5 |
我们可以发现字段类型的确由DATE类型变成了VARCHAR2类型,说明我们方案是可行的,以后只要使用这个函数,任何查询sql或者表都可以自动进行此类转换了。这里要注意的一点,修改后的字段,顺序都排到最后面去了,而且varchar2类型,默认是给的最长的4000,这个可以通过如下方式进行定义
NEW_COLS(i) := DBMS_TF.COLUMN_METADATA_T(name => tab.column(i).description.name, --字段名不变
type => DBMS_TF.TYPE_VARCHAR2 --字段类型改成varchar2,
max_len =>20
);
同理,number类型的有效位数和小数点精确度也可以通过precision,scale这两个参数来定义。
另外,上述创建了两个数据库对象,这对某些“代码洁癖”的开发者是很不爽的,其实这个函数和包可以合并成一个包,把这个函数单独放到包说明中即可,如下
CREATE OR REPLACE PACKAGE ptf_date_to_char AS
FUNCTION input(tab TABLE)
RETURN TABLE pipelined row polymorphic USING ptf_date_to_char;
FUNCTION describe(tab IN OUT dbms_tf.table_t)RETURN dbms_tf.describe_t;
PROCEDURE FETCH_ROWS;
END ptf_date_to_char;
/
CREATE OR REPLACE PACKAGE BODY ptf_date_to_char AS
FUNCTION describe(tab IN OUT dbms_tf.table_t) RETURN dbms_tf.describe_t AS
new_cols DBMS_TF.COLUMNS_NEW_T;
BEGIN
FOR i IN 1 .. tab.column.count LOOP --对所有字段循环
IF tab.column(i).description.type IN (dbms_tf.type_date) THEN --如果字段是日期类型
tab.column(i).pass_through := FALSE;
tab.column(i).for_read := TRUE; --是否多态表的列
NEW_COLS(i) := DBMS_TF.COLUMN_METADATA_T(name => tab.column(i).description.name, --字段名不变
type => DBMS_TF.TYPE_VARCHAR2 --字段类型改成varchar2
);
END IF;
END LOOP;
RETURN DBMS_TF.describe_t(new_columns => new_cols,
row_replication => true);
END;
PROCEDURE FETCH_ROWS AS
inp_rs DBMS_TF.row_set_t;
out_rs DBMS_TF.row_set_t;
rows PLS_INTEGER;
BEGIN
--只有上面进入了NEW_COLS的字段才会执行下面这段,其他字段保持不变
--inp_rs 表示原始数据
--out_rs 表示要输出的数据,默认情况下为空
DBMS_TF.get_row_set(inp_rs, rows); --获取原始数据
FOR c IN 1 .. inp_rs.count() LOOP --对列进行循环
FOR r IN 1 .. rows LOOP --对行进行循环
if inp_rs(c).tab_date(r) = trunc(inp_rs(c).tab_date(r)) then --这里做了个特殊处理,兼容年月日和年月日时分秒两种
out_rs(c).tab_varchar2(r) := to_char((inp_rs(c).tab_date(r)),
'yyyy-mm-dd');
else
out_rs(c).tab_varchar2(r) := to_char((inp_rs(c).tab_date(r)),
'yyyy-mm-dd hh24:mi:ss');
end if;
END LOOP;
END LOOP;
DBMS_TF.put_row_set(out_rs, replication_factor => 1);
END;
END ptf_date_to_char;
/
select * from ptf_date_to_char.input(hr.job_history);
我们稍微分析一下这个功能结构,
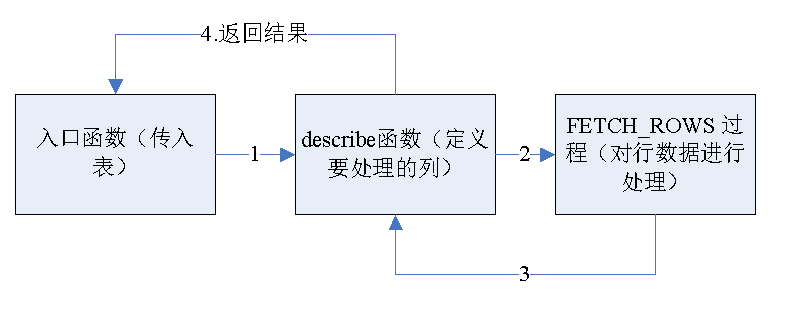
了解这个处理顺序后,我们就可以发挥想象来做一些其他PTF功能了,比如对所有字段进行nvl处理或者对所有字段进行trim处理等。
2.自动屏蔽指定字段
假设我们有一张表,有100多个字段(别问字段为什么这么多,siebel系统里就有一个),我们想要得到一个查询结果,这个查询结果中显示98个字段,有2个指定的字段不要显示,我们要如何写这个sql查询?
98个字段名都要列出来,想想都疯了吧,虽然我们可以用listagg加dba_tab_cols视图来拼接字符串,或者用pl/sql developer工具的自动完成来输入,但是,这个98个字段要放在程序里,也太长了,阅读和修改极为不便。这个时候我们就想要有一个函数,我们只要指定表名和不要的列名,就能查询出结果
CREATE OR REPLACE PACKAGE poly_pkg AS
FUNCTION my_ptf(tab IN TABLE,
col IN COLUMNS)
RETURN TABLE PIPELINED
ROW POLYMORPHIC USING poly_pkg;
FUNCTION describe (tab IN OUT DBMS_TF.table_t,
col IN dbms_tf.columns_t)
RETURN DBMS_TF.describe_t;
END poly_pkg;
/
CREATE OR REPLACE PACKAGE BODY poly_pkg AS
FUNCTION describe (tab IN OUT DBMS_TF.table_t,
col IN dbms_tf.columns_t)
RETURN DBMS_TF.describe_t
AS
BEGIN
-- Loop through all the table columns.
FOR i IN 1 .. tab.column.count() LOOP
-- Loop through all the columns listed in the second parameter.
FOR j IN 1 .. col.count() LOOP
-- Set pass_through to true for any columns not in the exclude list.
tab.column(i).pass_through := (tab.column(i).description.name != col(j));
-- Exit inner loop if you find a column that shouldn't be included.
EXIT WHEN NOT tab.column(i).pass_through;
END LOOP;
END LOOP;
RETURN NULL;
END;
END poly_pkg;
/
SELECT * FROM poly_pkg.my_ptf(emp, COLUMNS(hiredate, sal, mgr, comm));
此代码来自 Tim Hall的文章 https://oracle-base.com/articles/18c/polymorphic-table-functions-18c
这个查询表示,从emp表中输出列名不是hiredate/sal/mgr/comm这四个的所有字段。另外,这个sql后面是可以加where条件的,和普通的用法完全一样。
而且我们可以看到,由于不需要对每行的数据进行处理,这个包中没有使用FETCH_ROWS过程。
3.自动增加字段
有时候,我们想要基于原表的某些字段或者所有字段,生成几个新的字段,比如针对所有日期时间字段新增一个0时区日期时间字段,针对所有文本字段生成对应unicode值的字段,或者是根据所有字段生成一个json串,这些在做跨系统交互时,能带来极大的帮助,以下以新增一个包含所有字段的json字段为例
CREATE OR REPLACE PACKAGE poly_pkg AS
FUNCTION my_ptf(tab IN TABLE)
RETURN TABLE PIPELINED
ROW POLYMORPHIC USING poly_pkg;
FUNCTION describe (tab IN OUT DBMS_TF.table_t)
RETURN DBMS_TF.describe_t;
PROCEDURE fetch_rows;
END poly_pkg;
/
CREATE OR REPLACE PACKAGE BODY poly_pkg AS
FUNCTION describe (tab IN OUT DBMS_TF.table_t)
RETURN DBMS_TF.describe_t
AS
BEGIN
-- Make sure the for_read flag for each real column
-- is set, or get_row_set has no values.
FOR i IN 1 .. tab.column.count LOOP
CONTINUE WHEN NOT DBMS_TF.supported_type(tab.column(i).description.TYPE);
tab.column(i).for_read := TRUE;
END LOOP;
-- Add the new JSON_DOC column.
RETURN DBMS_TF.describe_t(
new_columns => DBMS_TF.columns_new_t(1 => DBMS_TF.column_metadata_t(name =>'JSON_DOC'))
);
END;
PROCEDURE fetch_rows AS
l_row_set DBMS_TF.row_set_t;
l_new_col DBMS_TF.tab_varchar2_t;
l_row_count PLS_INTEGER;
BEGIN
DBMS_TF.get_row_set(l_row_set, row_count => l_row_count);
--DBMS_TF.trace(l_row_set);
-- Populate the new column with a JSON doc of the associated row.
FOR row_num IN 1 .. l_row_count LOOP
l_new_col(row_num) := DBMS_TF.row_to_char(l_row_set, row_num);
END LOOP;
-- Associate the new values with the new column.
DBMS_TF.put_col(1, l_new_col);
END;
END poly_pkg;
/
SELECT * FROM poly_pkg.my_ptf(dept);
此代码来自 Tim Hall的文章 https://oracle-base.com/articles/18c/polymorphic-table-functions-18c
| DEPTNO | DNAME | LOC | JSON_DOC |
|---|---|---|---|
| 10 | ACCOUNTING | NEW YORK | {“DEPTNO”:10, “DNAME”:“ACCOUNTING”, “LOC”:“NEW YORK”} |
| 20 | RESEARCH | DALLAS | {“DEPTNO”:20, “DNAME”:“RESEARCH”, “LOC”:“DALLAS”} |
| 30 | SALES | CHICAGO | {“DEPTNO”:30, “DNAME”:“SALES”, “LOC”:“CHICAGO”} |
| 40 | OPERATIONS | BOSTON | {“DEPTNO”:40, “DNAME”:“OPERATIONS”, “LOC”:“BOSTON”} |
总结
有了以上几个案例,应该基本可以说明这个功能怎么使用了,而且我之前有个程序的缺陷(【AIO】使用ORACLE数据库存储过程把任意SQL生成HTML网页表格),无法自动对所有空值进行处理,也能通过此方法解决。
可惜的是,在百度上搜索 oracle +ptf 和 ORACLE+Polymorphic Table Functions ,几乎找不到一篇中国人写的文档,而且就算是在英文网站上,相关说明文档也不到一手之数。
甚至搜索“DBMS_TF”这个包名,都只有一份oracle的英文官方文档和ORACLE官方的在线sql演示页
希望我这篇文章能给各位带来一些新的启发。
fin
参考文章:
https://livesql.oracle.com/apex/livesql/file/content_GC53R14C0CVHJHUT3CUY7SN0F.html
https://oracle-base.com/articles/18c/polymorphic-table-functions-18c
posted on 2021-09-30 17:32 DarkAthena 阅读(544) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号