【ORACLE】关于ORACLE数据库中UNISTR函数转换UNICODE编码字符串为中文的思考
这个在网上能够搜到很多,基本都是下面这样写的
select unistr(REPLACE((str),'\u','\')) from dual
将字符串中的"\u" 替换成 “\”,再使用unistr进行转换.我就觉得奇怪了,这么明显的漏洞为什么没人提。
目前常见的unicode编码形如 “\u6697”,但oracle中的却是 “\6697”,少了"\“后的"u”,但是也不应该把"\u" 都替换成 “\” ,如果出现了混搭字符串,既有unicode编码又有正常的字母和符号,而且有个单独的"\u",用这种方式就会丢失一部分文字信息。
那么有没有什么办法可以让这个转换更精确呢?这就要看看为什么有带u和不带u两种编码形式了。
百度不能搜符号,找相关资料很麻烦,不过还是找到一点点。
其实准确来说,unicode编码应该是“6697”这4个十六进制数字,至于前面的标识符,是各语言自行定义的转义或者识别方式,见下表
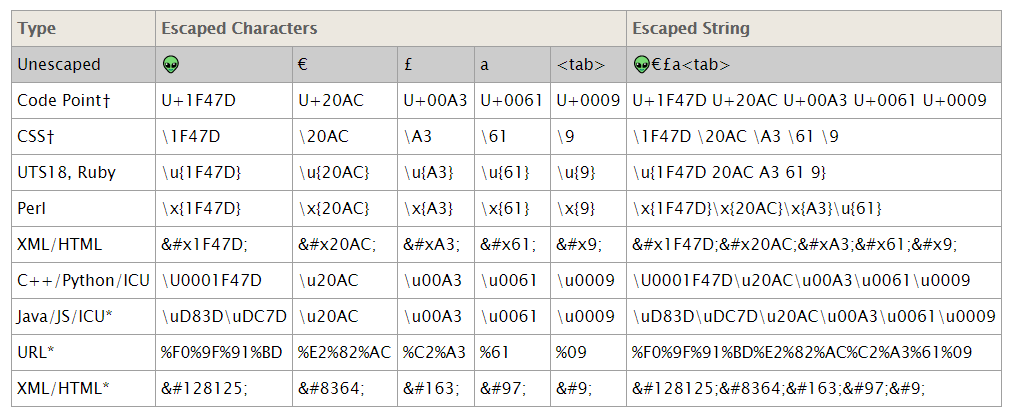
表格来自 https://unicode.org/reports/tr18/
其中JAVA、JS、C++、python这几种常用的都有用“\u”+十六进制数字的形式,所以是最常见的。而oracle中使用的,很像是CSS,但ORACLE是必须要4个十六进制数字,而CSS可以省略前面的0。好家伙,连unicode官方文档里都没有oracle的表达方式!
这下我们就要回头看看oracle中的unistr到底是在做什么了
Purpose
UNISTR takes as its argument a text literal or an expression that resolves to character data and returns it in the national character set. The national character set of the database can be either AL16UTF16 or UTF8. UNISTR provides support for Unicode string literals by letting you specify the Unicode encoding value of characters in the string. This is useful, for example, for inserting data into NCHAR columns.
The Unicode encoding value has the form ‘\xxxx’ where ‘xxxx’ is the hexadecimal value of a character in UCS-2 encoding format. Supplementary characters are encoded as two code units, the first from the high-surrogates range (U+D800 to U+DBFF), and the second from the low-surrogates range (U+DC00 to U+DFFF). To include the backslash in the string itself, precede it with another backslash (\).
For portability and data preservation, Oracle recommends that in the UNISTR string argument you specify only ASCII characters and the Unicode encoding values.
以上这段来自oracle官方文档 https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/UNISTR.html
文章中明确指出了UNISTR这个函数就是为了转换unicode编码字符串的,好像两个官方真就各玩各的了,没有一点关联。
但已经到这里了,怎么能放弃呢。既然没有官方支持,那么我们就来自己写一个。
依然以最常见的 “\u”+4个十六进制数字这种格式为例,比如“\u6697”,一个这玩意占6个字节的长度,我们可以写一个循环,取传入字符串的11+5、22+5、3~3+5 …一直循环到最后,每次循环中,使用正则表达式来判断这6个字节长度的字符串是否为unicode编码:如果是,就用 “unistr(REPLACE((str),’\u’,’’))" 这种方式对数据进行转换;如果不是,就保持原值。
这个方式还有点冗余,比如识别到一个unicode编码后,下一次循环应该可以调过这6个字符,因为已经被用掉了。然后就是正则表达式了,这个也很简单
regexp_like( '\u6697', '\\u[0-9a-fA-F]{4}')
最后成品
https://github.com/Dark-Athena/unicode-js-oracle
create or replace function unistr_js(str varchar2) return varchar2 is
--功能:转换js的unicode编码为对应的可显示字符, 例如 \u6697\u9ed1\u96c5\u5178\u5a1c
--作者:DarkAthena
--Email:darkathena@qq.com
/*
Copyright DarkAthena
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
outstr varchar2(32000);
n number;
begin
n := 0;
for i in 1 .. length(str) loop
if n > 0 then
n := n + 1;
if n = 7 then
n := 0;
else
continue;
end if;
end if;
if regexp_like(substr(str, i, 6), '\\u[0-9a-fA-F]{4}') then
outstr := outstr || unistr(replace(substr(str, i, 6), '\u', '\'));
n := 1;
else
outstr := outstr || substr(str, i, 1);
end if;
end loop;
return(outstr);
end unistr_js;
/
这可比现在网上流传的unistr+replace的转换要精确得多了。
其实还能更进一步,那就是兼容多种编码的unicode,方法和这个类似,改改正则和跳过的长度即可,以后看心情要不要改吧。
posted on 2021-09-30 17:55 DarkAthena 阅读(696) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号