【ORACLE】关于21c版本中机器学习OML4PY功能嵌入式python代码执行的研究整理
前言
之前有写过一篇
【ORACLE】在ORACLE数据库中启用机器学习功能(OML)以支持PYTHON脚本的运行
在断断续续折腾了好久之后,总算可以用oracle官方提供的方案在oracle数据库中执行python代码了。但是仔细研究后,发现除了安装是个坑外,使用起来也是有相当多的限制,毕竟这个功能的目的是用来写机器学习的,不是纯粹的执行python代码。
所以我就写这篇文章记录下这个功能该怎么使用。
注意,本文不会大篇幅复制官方原文档的内容,请自行结合官方原文档食用。
概览
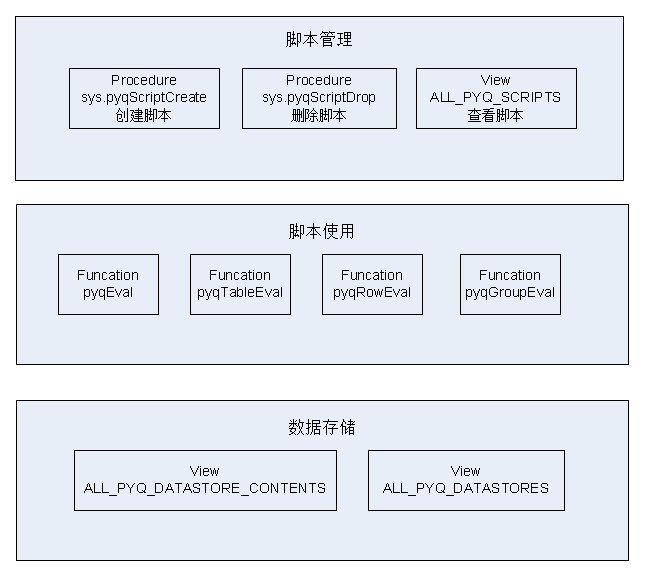
创建函数
sys.pyqScriptCreate (
V_NAME VARCHAR2 IN --脚本名称
V_SCRIPT CLOB IN --脚本内容
V_GLOBAL BOOLEAN IN DEFAULT --是否全局可用(即public)
V_OVERWRITE BOOLEAN IN DEFAULT) --是否覆盖
根据官方多个示例来看,V_SCRIPT这个参数在形式上有两种
1
func = lambda: "Hello World from a lambda!
2
def func_name():
import xxx
...
return value
并且在创建环节,如果python代码有误,是不会报错的,仅仅只是把这段文本保存进了数据库。
需要注意的有几点
- 由于这个参数是个字符串,需要注意单引号的转义
- 注意python代码的行首缩进规则,官网示例有一部分格式化的代码是存在问题的
- 它必须是个函数(对象?),所以import 不能放在最前面
ORA-20000: PyQuery error
The script must define exactly one object
另外还有几点放在后面使用函数来说
删除函数
sys.pyqScriptDrop (
V_NAME VARCHAR2 IN --脚本名称
V_GLOBAL BOOLEAN IN DEFAULT --是否全局
V_SILENT BOOLEAN IN DEFAULT) --是否"不显示"删除报错信息
这个没啥好说的,是物理删除 sys.pyq$script 这个表中的记录 ,一删就没了。多用户的时候注意下 V_GLOBAL。
查看函数
select * from ALL_PYQ_SCRIPTS;
可以看到名称、内容、所有者
使用函数
它提供了4种执行函数的方式,每种的区别在于传入参数
| pyqEval | pyqTableEval | pyqRowEval | pyqGroupEval |
|---|---|---|---|
| INP_QRY | INP_QRY | INP_QRY | |
| PAR_QRY | PAR_QRY | PAR_QRY | PAR_QRY |
| OUT_QRY | OUT_QRY | OUT_QRY | OUT_QRY |
| ROW_NUM | |||
| GRP_COL | |||
| EXP_NAM | EXP_NAM | EXP_NAM | EXP_NAM |
- EXP_NAM 为要调用的python函数名称
- OUT_QRY 为查询输出的格式
2.1 “XML”,最通用的,将python返回结果以xml格式的一个字符串返回到一个clob类型的字段中;如果是图片,则返回对应的base64编码
2.2 “PNG”,将python返回的png图片的二进制数据返回到一个blob类型的字段中
2.3 一个类似于’{“A”:“varchar2(100)”,“B”:“NUMBER”}'这样的json串,此方式必须保证python的返回值为以下几种之一:a pandas.DataFrame, a numpy.ndarray, a tuple, or a list of tuples,并且返回的字段数量及类型必须都匹配。使用此方式时,是以一个表的形式返回数据,方便在数据库中使用。这种其实对python函数有了大幅限制。
2.4 表或视图名称,必须是该用户有查询权限的 - PAR_QRY 为要传入到EXP_NAM中指定的函数的参数,json格式,比如’{“modelName”:“linregr”,“datastoreName”:“pymodel”,“oml_connect”:1}’,其中以"oml_"开头的为保留参数,起到一些特殊控制的作用 About Special Control Arguments
- INP_QRY 为要传入到EXP_NAM中指定的函数的表或视图名称,必须是该用户有查询权限的
- ROW_NUM 为对应INP_QRY中表或视图的行数,整数类型
- GRP_COL 为对应INP_QRY中表或视图的分组字段,用逗号分割的字符串
可以看到EXP_NAM和OUT_QRY是每种方式都必填的,其他几个都是要传到python函数的参数。
执行的方式都是下面这种形式
SELECT *
FROM table(pyqEval(
NULL,
'XML',
'pyqFun2'));
数据存储
这里说的数据存储不是指的数据库中的表,而是指的机器学习计算的结果,比如模型数据。
比如官方的这个例子
BEGIN
sys.pyqScriptCreate('myLinearRegressionModel',
'def fit_model(dat, modelName, datastoreName):
import oml
from sklearn import linear_model
regr = linear_model.LinearRegression()
regr.fit(dat.loc[:, ["Sepal_Length", "Sepal_Width", \
"Petal_Length"]], dat.loc[:,["Petal_Width"]])
oml.ds.save(objs={modelName:regr}, name=datastoreName, overwrite=True)
return str(regr)',
FALSE, TRUE);
END;
创建这个函数后,执行它,它会在“oml.ds.save”这里,把数据保存进去,然后在
select * from ALL_PYQ_DATASTORE_CONTENTS;
select * from ALL_PYQ_DATASTORES;
这两个视图中都只有一条记录,显示该数据的相关参数,比如名称、模型、类、大小等
延伸一点
机器学习和数据查询完全是两个不同的思路,但oracle这个功能,在执行机器学习的操作时,都是以select的方式来执行函数,你既可以查询python吐出来的数据,也可以把数据库中的一张表当成样本丢到python里去进行模型训练,只是形式上都是"select xxx from table()"
这个功能可能有资源自动回收机制,有调用python的会话在inactive一段时间后,再执行python函数,会报
ORA-28576: lost RPC connection to external procedure agent
ORA-06512: at “PYQSYS.PYQ$EVALIMPL_IN”, line 77
ORA-06512: at “PYQSYS.PYQ$EVALIMPL_IN”, line 74
ORA-06512: at “SYS.DBMS_SQL”, line 1766
ORA-06512: at “PYQSYS.PYQ$ETSTART”, line 159
ORA-06512: at “PYQSYS.PYQEVALIMPL”, line 51
然后直接再执行一次,即可正常返回结果,从这里可以看到,它其实是在与操作系统中的程序在进行交互,这点我们其实也可以通过执行个python函数验证,比如获取当前执行路径或者生成一个文件到操作系统目录中去
BEGIN
sys.pyqScriptCreate('pyqFun12',
q'{def aaa():
import os
f = open('orapytest.txt', 'w')
f.write('Hello, world!')
f.close()
return os.getcwd()}');
END;
/
SELECT * FROM table(pyqEval(NULL, 'XML', 'pyqFun12'));
name value
---- --------
<root><str>/u02/config/cdb1/homes/OraDB21Home1/hs/log</str></root>
然后我们进操作系统的这个“/u02/config/cdb1/homes/OraDB21Home1/hs/log”目录看看

果然在这里,另外我尝试生成文件到其他目录,有报权限不够,看看这个文件的属性

这说明使用oml4py,让ORACLE嵌入式执行python时,是以操作系统oracle用户的身份在操作系统中执行的,和dbms_mle的机制不一样,但这样其实更方便数据的交互。不过需要注意的是,这要更加防范恶意的sql注入,所以一定要把控好相关对象的执行权限。
而且由于它会自动回收,所以如果写自动化的程序时,一定要写此种异常的重试机制(ORACLE干嘛自己不把这个加进去~)。
既然知道了它与操作系统有关,当然就到了喜闻乐见的整活环节了。
整活
假设我直接把".py"文件放到操作系统中,然后在数据库写个函数,import这个文件,它能不能执行?
我把我上次写的解析sql中的表名那个项目的文件下载进操作系统
https://github.com/Dark-Athena/list_table_sql-py
保存在了 “/list_table_sql-py” 目录,然后安装依赖库
pip3 install antlr4-python3-runtime
在数据库中创建python函数并执行它
BEGIN
sys.pyqScriptCreate('pyqFun13',
'def aaa(sql):
import sys
sys.path.append(''/list_table_sql-py'')
from list_table_sql import list_table_sql as t
return t(''{"sql":"''+sql+''","mode":"T"}'')
');
END;
/
SELECT *
FROM table(pyqEval('{"sql":"select abc,cdf x from tab1 a,tab2,tab3@dblink where 1=1"}',
'XML',
'pyqFun13'));
NAME VALUE
---- -----
<root><dict><item><key>tablename</key><value><item>tab1</item><item>tab2</item><item>tab3@dblink</item></value></item></dict></root>
可以看到三个表名都解析出来了。
本篇完。
- 本文链接: https://www.darkathena.top/archives/about-oml4py-part2
- 版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 3.0 许可协议。转载请注明出处!
posted on 2021-11-14 20:43 DarkAthena 阅读(170) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号