

《卷积神经网络详述》
《卷积神经网络——雨石博客》
学习参考:http://blog.csdn.net/stdcoutzyx/article/details/41596663
配置使用过theano和cuda-convnet, cuda-convnet2
1.当做分类器使用
2.网络中间某一层的输出当做是数据的另一种表达,从而可以将其认为是经过网络学习到的特征。基于该特征,可以进行进一步的相似度比较等。
3.有效的关键是 大规模的数据 缺少数据参数无法训练充分
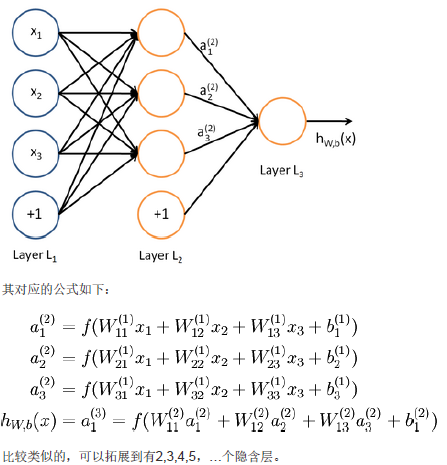
一、神经网络
训练方法同Logistic类似,不过由于其多层性,还需要利用链式求导法则对隐含层的节点进行求导,即梯度下降+链式求导法则,称为反向传播。
二、卷积神经网络
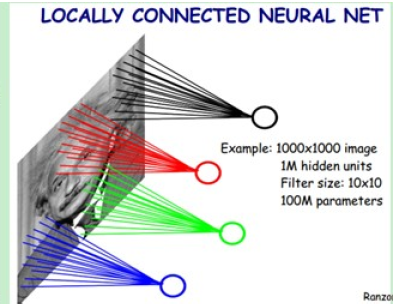
在图像处理中,如果隐含层数目与输入层一样(假设图片像素为1000×1000,常表示为一个1000000的向量,即隐含层数目也是1000000的向量),在神经网络中参数数目将为1000000×1000000=10^12. (即图像的一个像素作为上图的一个x,参数矩阵为1000000×1000000)参数数目太大,会使得训练不充分。
为了降低参数数目:
1.局部感知野(cognitive field)
从生物学的视觉系统启发得到,视觉感知是从局部到全局,每个神经元只需要对局部进行感知,在最高层将局部的信息综合起来得到全局的信息(即这些神经元只响应某些特定区域的刺激)。
假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的万分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
2.参数共享
在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
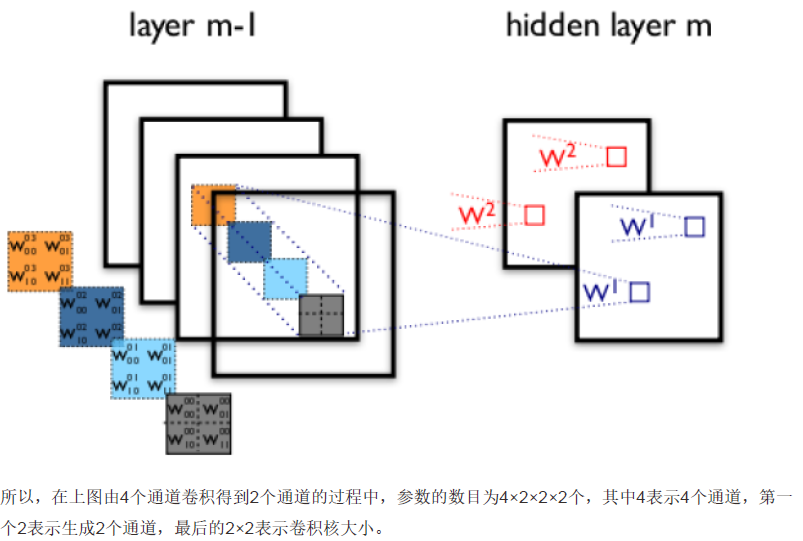
3.多卷积核
卷积核意味着提取特征,当多卷积核时,即提取多个特征。 (那卷积神经网络每一层的成熟怎么确定的,)
4.池化(down-pooling)
聚合统计 ——————除此之外还有什么统计方法,以及优点
1)低维度
2)改善优化结果(防止过拟合)
5.多层卷积
在实际应用中,往往使用多层卷积,然后再使用全连接层进行训练,多层卷积的目的是一层卷积学到的特征往往是局部的,层数越高,学到的特征就越全局化。
6 作者参考资源
[1] http://deeplearning.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B 栀子花对
Stanford深度学习研究团队的深度学习教程的翻译
[2] http://blog.csdn.net/zouxy09/article/details/14222605 csdn博主zouxy09深度学习教程系列
[3] http://deeplearning.net/tutorial/ theano实现deep learning
[4] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural
networks[C]//Advances in neural information processing systems. 2012: 10971105.
[5] Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000
classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE,
2014: 18911898.
