

RabbitMQ系列之高可用集群
为了实现高可用,我采用LVS+双节点RabbitMq , 架构图如下:
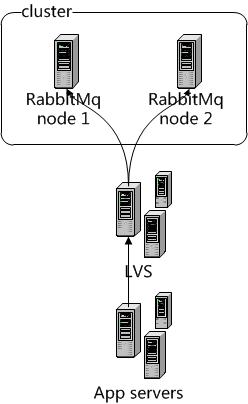
在RabbitMQ之前放了LVS, LVS 采用 rr 轮询算法 , 目的是将请求平均分配到两个真实节点,并配置5672端口监控,异常时转移到另外的节点。
在 ,做完之后测试发现,用上LVS之后,测试会报错,服务器端的队列名称都是一致的,但是队列内容却并不是一致,看来需要做同步。
Rabbit提供镜像功能,需要基于rabbitmq策略来实现,政策是用来控制和修改群集范围的某个vhost队列行为和Exchange行为 :
set_policy [-p vhostpath] {name} {pattern} {definition} [priority]
eg.
1 rabbitmqctl set_policy ha-allqueue "^" '{"ha-mode":"all"}'
pattern 是匹配队列名称的正则表达式 , 进行区分哪些队列使用哪些策略
definition 其实就是一些arguments, 支持如下参数:
ha-mode:One ofall,exactlyornodes(the latter currently not supported by web UI).ha-params:Absent ifha-modeisall, a number ifha-modeisexactly, or an array of strings ifha-modeisnodes.ha-sync-mode:One ofmanualorautomatic. //如果不指定该参数默认为manual,这个在高可用集群测试的时候详细分析federation-upstream-set:A string; only if the federation plugin is enabled.
ha-mode 的参数:
| ha-mode | ha-params | Result |
|---|---|---|
| all | (absent) | Queue is mirrored across all nodes in the cluster. When a new node is added to the cluster, the queue will be mirrored to that node. |
| exactly | count | Queue is mirrored to count nodes in the cluster. If there are less than count nodes in the cluster, the queue is mirrored to all nodes. If there are more than countnodes in the cluster, and a node containing a mirror goes down, then a new mirror will not be created on another node. (This is to prevent queues migrating across a cluster as it is brought down.) |
| nodes | node names | Queue is mirrored to the nodes listed in node names. If any of those node names are not a part of the cluster, this does not constitute an error. If none of the nodes in the list are online at the time when the queue is declared then the queue will be created on the node that the declaring client is connected to. |
在管理policy的时候WebUI是非常不错:
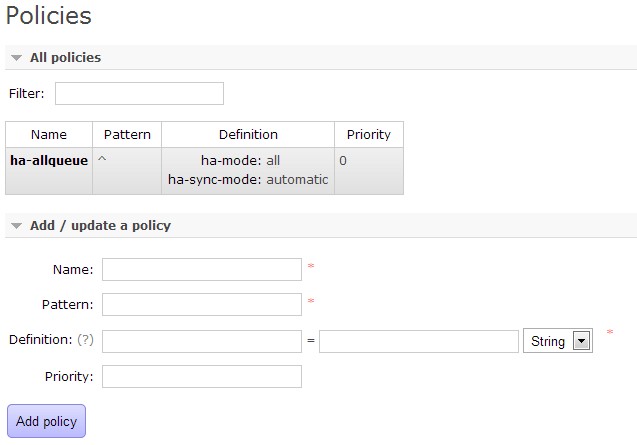
Definition加入两项:
ha-mode:all
ha-sync-mode:automatic
到这里配置已经完成,接下来进行测试。
两个节点之间就会开始同步消息了。
这时借助前面的LVS / HA 就可以使用高可用了 。
--------------------------------------------------------------------------
Daniel Chow's Blog - 不管你在哪里,都要有一颗创业的心!
http://www.cnblogs.com/DanielChow/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号