
dotNetSpider 手记
准备工作:
从github上download工程。
安装VS2017。
安装 .net core 2.0。
编译通过。
基础架构:
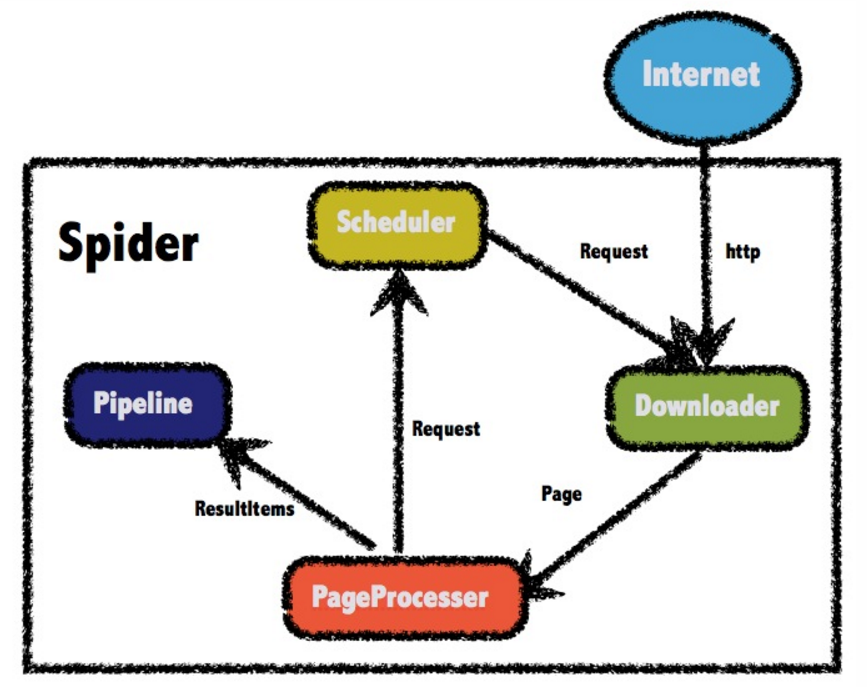
调度器 Scheduler 从根site开始,向 Downloader 分配请求任务。
Downloader 根据分配到的请求任务,向目标site 下载 page,并交由 PageProcessor 进行页面处理。
PageProcessor 将处理的结果推入 Pipeline,将解析出的新的链接,推入 Scheduler。
循环直至 Scheduler 没有新的请求可以处理。
Spider.Create:
设定根访问节点、唯一身份标识、请求调度器 Scheduler,页面处理器 PageProcessor。
以给出的 Sample 样例中,遍历 cnblog 站点为例进行解析:
Scheduler 是 QueueDuplicateRemovedScheduler。就是一个存放 Request 的队列。
PageProcessor 是默认的 DefaultPageProcessor。
这里涉及到 XPath 的知识,需要快速了解。
XPath:XPath 使用路径表达式在 XML 文档中进行导航,选取 XML 文档中的节点或者节点集。
主要知识点见:http://www.runoob.com/xpath/xpath-syntax.html
页面处理流程 BasePageProcessor.Process:
public void Process(Page page) { bool isTarget = true; if (_targetUrlPatterns.Count > 0 && !_targetUrlPatterns.Contains(null)) { foreach (var regex in _targetUrlPatterns) { isTarget = regex.IsMatch(page.Url); if (isTarget) { break; } } } if (!isTarget) { return; } Handle(page); page.ResultItems.IsSkip = page.ResultItems.Results.Count == 0; if (!page.SkipExtractTargetUrls) { ExtractUrls(page); } }
在 Sample 中,调用的是 DefaultPageProcessor 提供的 hanlde:
page.AddResultItem("title", page.Selectable.XPath("//title").GetValue()); page.AddResultItem("html", page.Content);
默认的页面处理,是找出 “title” 元素,以及整个 html 内容。
接着在下载好的页面内容中,查找更多的 url。
由此可见,实现自定义爬虫的关键,则是定义对页面的处理得到结果,以及对结果的处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号