

什么是分布式事务?
1、什么是分布式事务
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。以上是百度百科的解释,简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
2、分布式事务的产生的原因
2.1、数据库分库分表
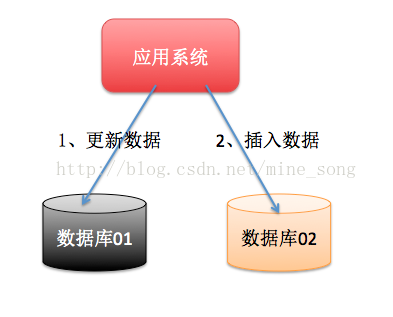
当数据库单表一年产生的数据超过1000W,那么就要考虑分库分表,具体分库分表的原理在此不做解释,以后有空详细说,简单的说就是原来的一个数据库变成了多个数据库。这时候,如果一个操作既访问01库,又访问02库,而且要保证数据的一致性,那么就要用到分布式事务。
2.2、应用SOA化
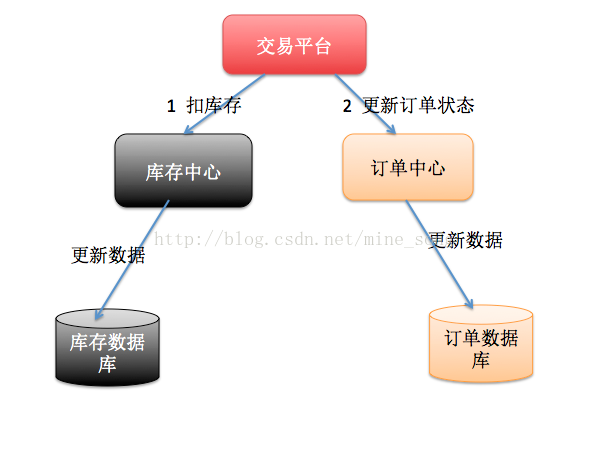
所谓的SOA化,就是业务的服务化。比如原来单机支撑了整个电商网站,现在对整个网站进行拆解,分离出了订单中心、用户中心、库存中心。对于订单中心,有专门的数据库存储订单信息,用户中心也有专门的数据库存储用户信息,库存中心也会有专门的数据库存储库存信息。这时候如果要同时对订单和库存进行操作,那么就会涉及到订单数据库和库存数据库,为了保证数据一致性,就需要用到分布式事务。
以上两种情况表象不同,但是本质相同,都是因为要操作的数据库变多了!
3、事务的ACID特性
3.1、原子性(A)
所谓的原子性就是说,在整个事务中的所有操作,要么全部完成,要么全部不做,没有中间状态。对于事务在执行中发生错误,所有的操作都会被回滚,整个事务就像从没被执行过一样。
3.2、一致性(C)
事务的执行必须保证系统的一致性,就拿转账为例,A有500元,B有300元,如果在一个事务里A成功转给B50元,那么不管并发多少,不管发生什么,只要事务执行成功了,那么最后A账户一定是450元,B账户一定是350元。
3.3、隔离性(I)
所谓的隔离性就是说,事务与事务之间不会互相影响,一个事务的中间状态不会被其他事务感知。
3.4、持久性(D)
所谓的持久性,就是说一单事务完成了,那么事务对数据所做的变更就完全保存在了数据库中,即使发生停电,系统宕机也是如此。
4、分布式事务的应用场景
4.1、支付
最经典的场景就是支付了,一笔支付,是对买家账户进行扣款,同时对卖家账户进行加钱,这些操作必须在一个事务里执行,要么全部成功,要么全部失败。而对于买家账户属于买家中心,对应的是买家数据库,而卖家账户属于卖家中心,对应的是卖家数据库,对不同数据库的操作必然需要引入分布式事务。
4.2、在线下单
买家在电商平台下单,往往会涉及到两个动作,一个是扣库存,第二个是更新订单状态,库存和订单一般属于不同的数据库,需要使用分布式事务保证数据一致性。
5、常见的分布式事务解决方案
5.1、基于XA协议的两阶段提交
XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。XA实现分布式事务的原理如下:
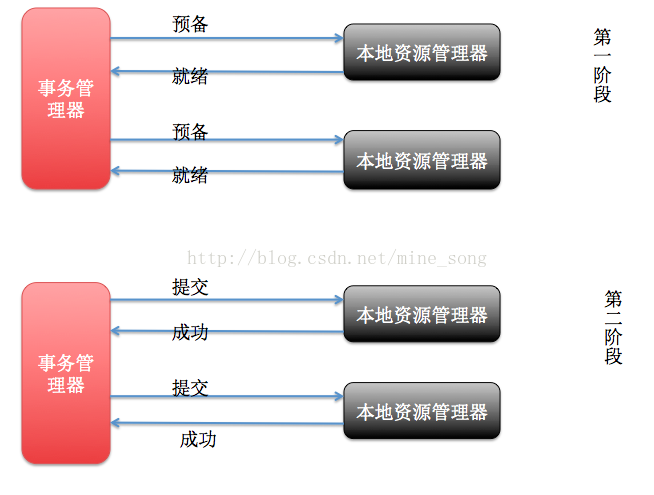
总的来说,XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
5.2、消息事务+最终一致性
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RocketMQ就支持这一特性,具体原理如下:
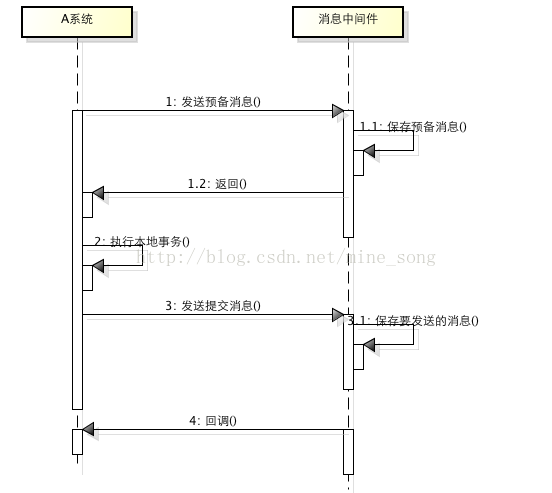
1、A系统向消息中间件发送一条预备消息
2、消息中间件保存预备消息并返回成功
3、A执行本地事务
4、A发送提交消息给消息中间件
通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
步骤一出错,则整个事务失败,不会执行A的本地操作
步骤二出错,则整个事务失败,不会执行A的本地操作
步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:

虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
5.3、TCC编程模式
所谓的TCC编程模式,也是两阶段提交的一个变种。TCC提供了一个编程框架,将整个业务逻辑分为三块:Try、Confirm和Cancel三个操作。以在线下单为例,Try阶段会去扣库存,Confirm阶段则是去更新订单状态,如果更新订单失败,则进入Cancel阶段,会去恢复库存。总之,TCC就是通过代码人为实现了两阶段提交,不同的业务场景所写的代码都不一样,复杂度也不一样,因此,这种模式并不能很好地被复用。
6、总结
分布式事务,本质上是对多个数据库的事务进行统一控制,按照控制力度可以分为:不控制、部分控制和完全控制。不控制就是不引入分布式事务,部分控制就是各种变种的两阶段提交,包括上面提到的消息事务+最终一致性、TCC模式,而完全控制就是完全实现两阶段提交。部分控制的好处是并发量和性能很好,缺点是数据一致性减弱了,完全控制则是牺牲了性能,保障了一致性,具体用哪种方式,最终还是取决于业务场景。作为技术人员,一定不能忘了技术是为业务服务的,不要为了技术而技术,针对不同业务进行技术选型也是一种很重要的能力
原文链接:https://blog.csdn.net/qq_39827935/article/details/80677355

