斗鱼爬虫,爬取颜值频道的主播图片和名字
在斗鱼的界面中,如果滚动条没有拉下去,那么下面的图片都只是一条鱼的图片,所以要使浏览器自动拉动滚动条,可以用到python的selenium库,
1、配置浏览器
要使用selenium,还需要安装 chromedriver.exe,这里是使用Chrome浏览器,首先在https://npm.taobao.org/mirrors/chromedriver下这个网址中下载适合自己浏览器版本的chromedriver.exe,然后安装在Chrome浏览器的根目录下
2使用selenium库,获取斗鱼直播的整个页面
自动打开Chrome浏览器,然后进入斗鱼直播网页并使页面最大化,再实现自动拉动滚轮的方法来获取整个直播页面
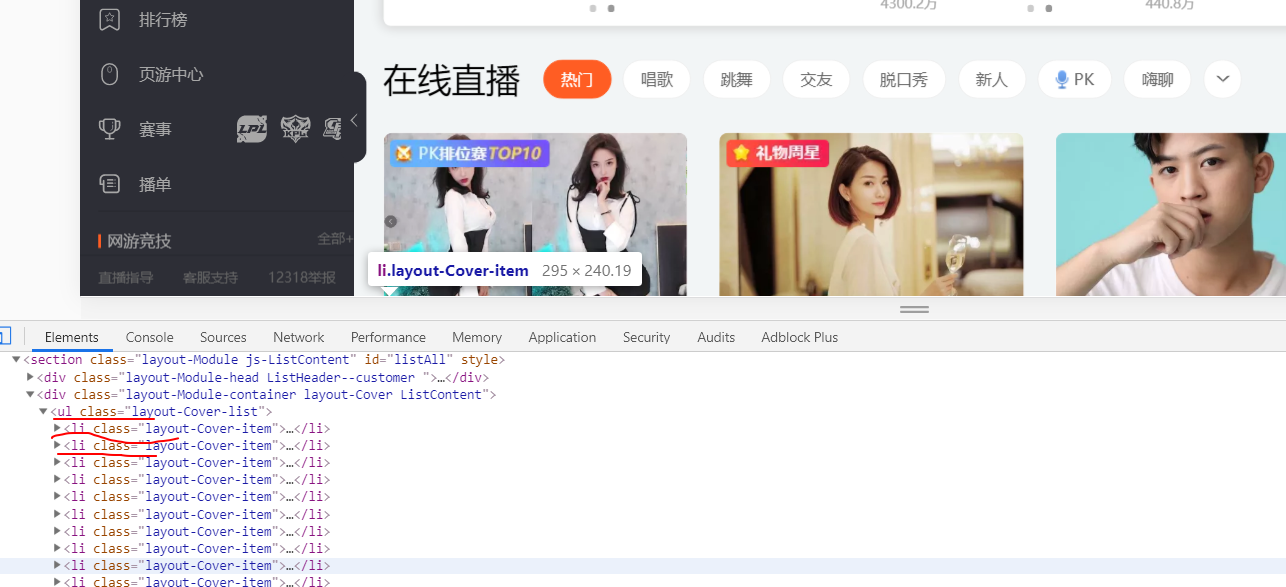
在浏览器按F12进入检查模式,可以看到所有的主播页面都在class="layout-Cover-list"的ul标签下的li标签中,
所以可以这样来获取数据

3、获取图片链接和主播名字
找到图片所在的位置,在每个class ="DyImg-content is-normal " 的src标签中
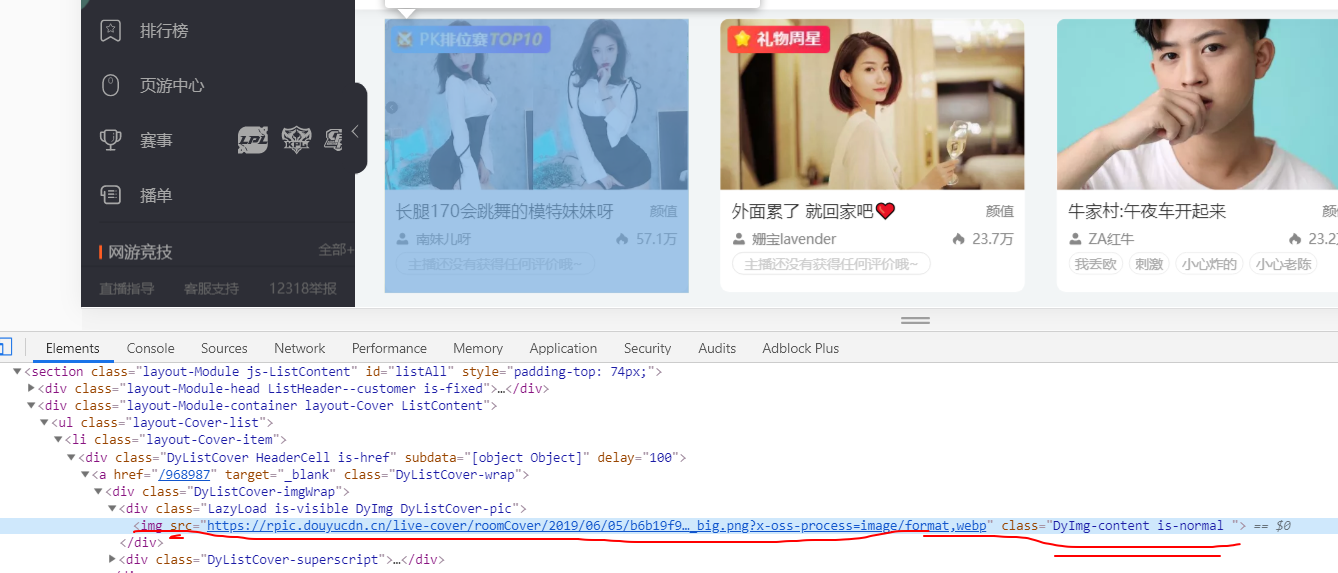
名字在每个class="DyListCover-user" d的h2中
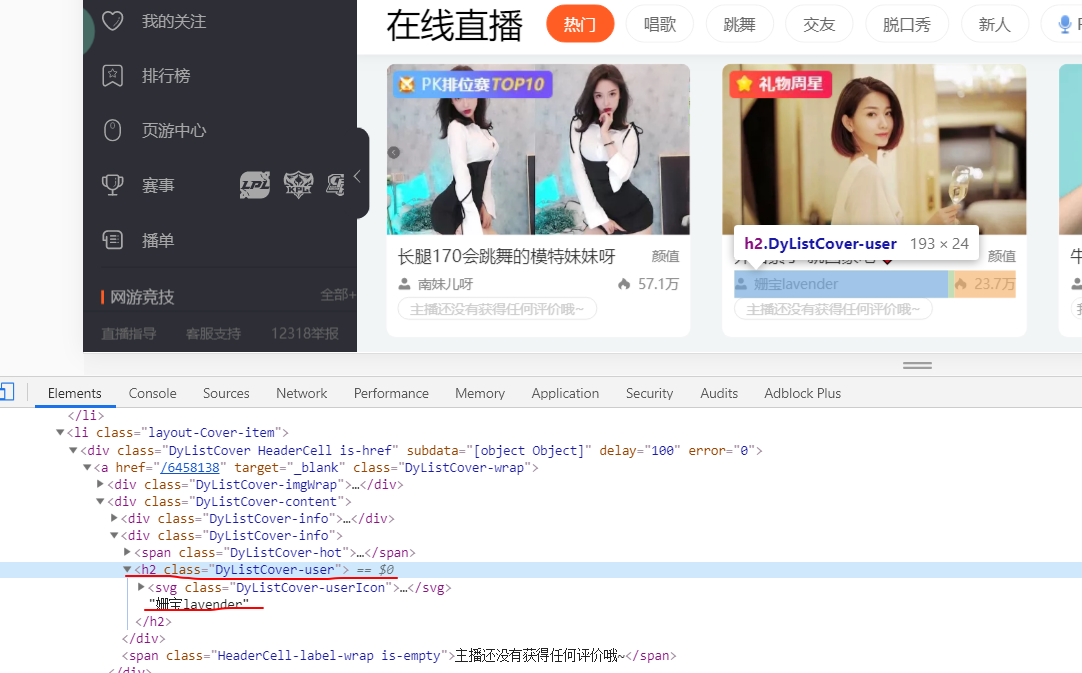
4、将得到的图片和名字保存到本地
因为得到的图片链接可能有些不必要的字符,所以用正则表达式,只匹配到有用的地方,再保存下来,
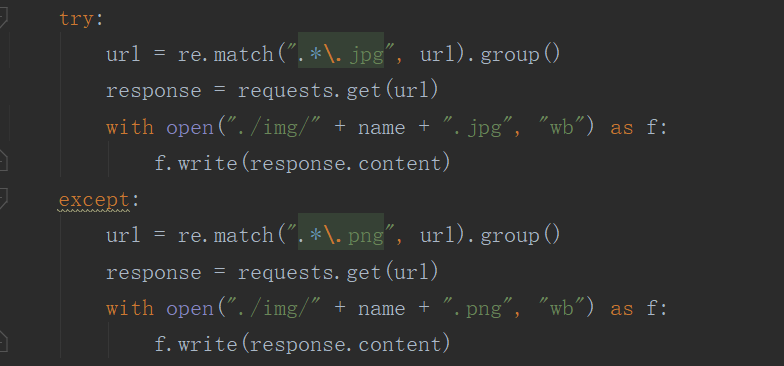
5、完整代码
import re
import requests
from selenium import webdriver
import time
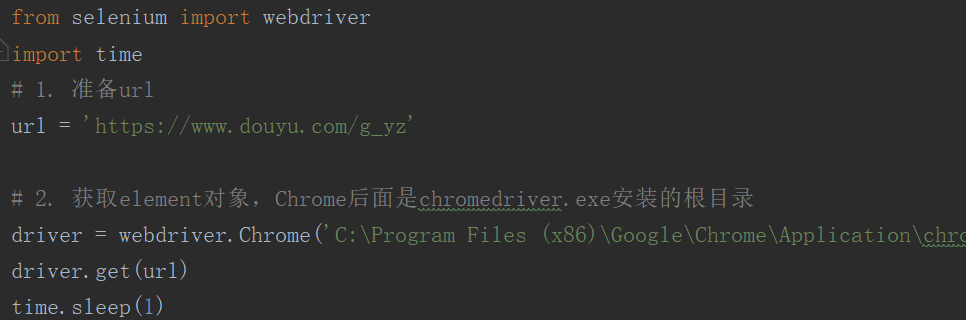
# 1. 准备url
url = 'https://www.douyu.com/g_yz'
# 2. 获取element对象,Chrome后面是chromedriver.exe安装的根目录
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get(url)
time.sleep(1)
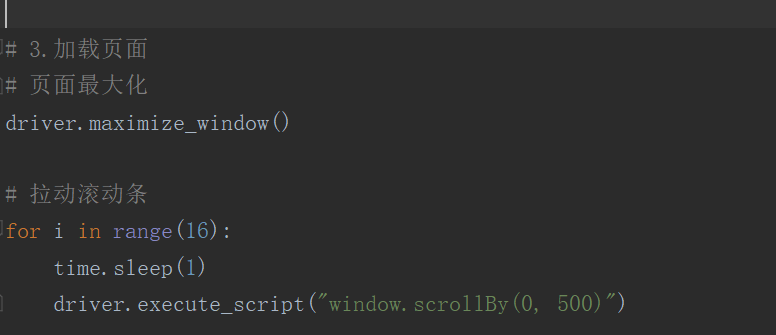
# 3.加载页面
# 页面最大化
driver.maximize_window()
# 拉动滚动条
for i in range(16):
time.sleep(1)
driver.execute_script("window.scrollBy(0, 500)")
# 4. 获取数据
lis = driver.find_elements_by_xpath('//ul[@class="layout-Cover-list"]/li')
# 5.发送请求保存图片
for li in lis:
url = li.find_element_by_xpath('.//img[@class="DyImg-content is-normal "]').get_attribute("src")
name = li.find_element_by_xpath('.//h2[@class="DyListCover-user"]').text
try:
url = re.match(".*\.jpg", url).group()
response = requests.get(url)
with open("./img/" + name + ".jpg", "wb") as f:
f.write(response.content)
except:
url = re.match(".*\.png", url).group()
response = requests.get(url)
with open("./img/" + name + ".png", "wb") as f:
f.write(response.content)
print(name)
print(url)
# 6.退出/下一页
driver.close()
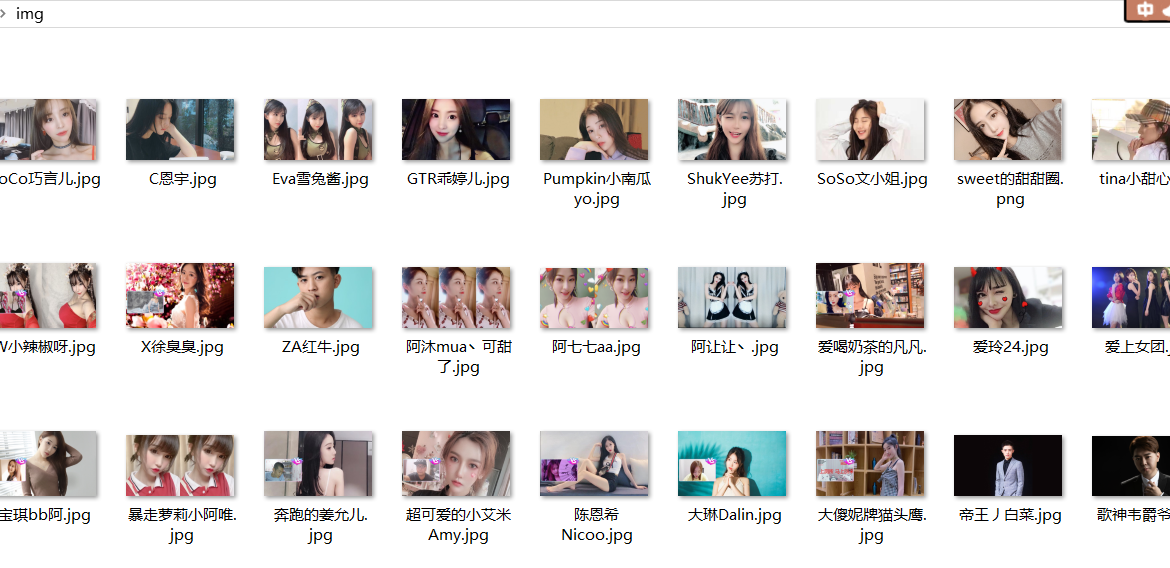
结果图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号