

The road of Python
二进制与八进制转换
二进制与八进制对应关系:
八进制 二进制
0 000
1 001
2 010
3 011
4 100
5 101
6 110
7 111
例:1010100101
八进制:从右向左 3位一隔开 不够三位用0补位 变成:
001 010 100 101
0o 1 2 4 5
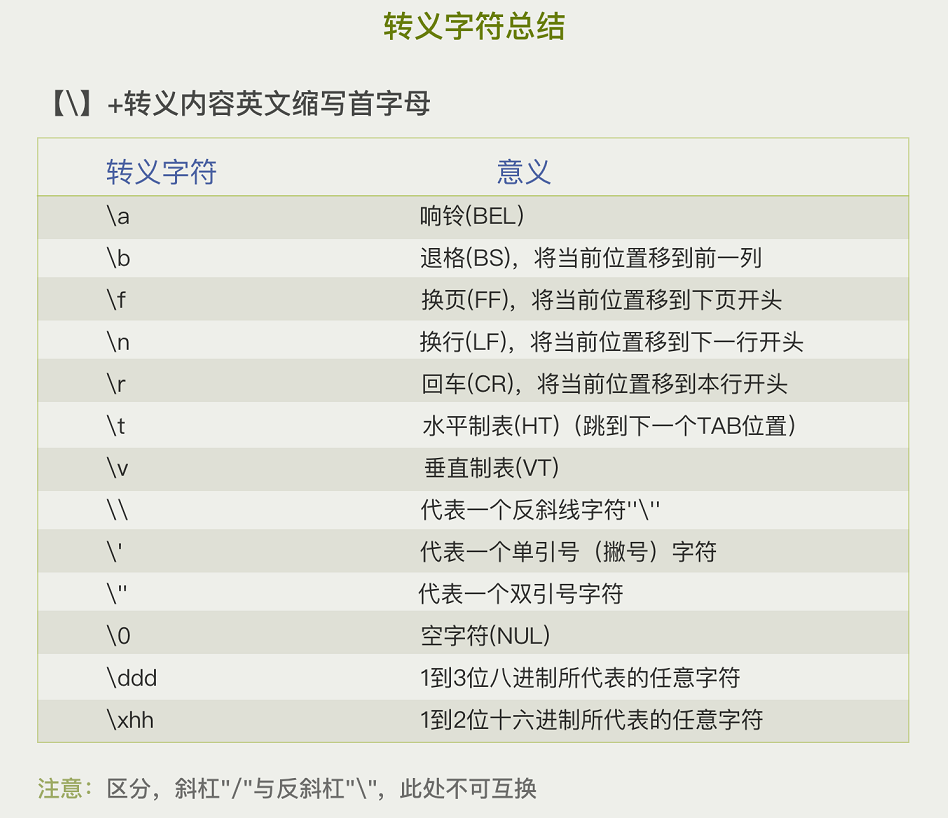
转义含义总结
换行\n代表【+newline】;退格\b代表【+backspace】;回车\r代表【+return】
示例


1 import random 2 import time 3 4 ###提示语部分 5 print('你好,我是机器人小埋,我们来玩个猜年龄的小游戏吧~(◆◡◆)') 6 time.sleep(2) 7 8 print(''' 9 ============================= 10 干物妹!うまるちゃんの年齢 11 ============================= 12 ''') 13 time.sleep(1) 14 15 16 print('小埋的真实年龄在1到10之间哦~') 17 time.sleep(1) 18 19 20 print('不过,你只有5次机会哦~') 21 time.sleep(1) 22 23 24 print('下面,请输入小埋的年龄吧:') 25 26 27 #从0至10产生一个随机整数,并赋值给变量age 28 age = random.randint(1,10) 29 30 31 #设置次数 32 for guess in range(1,6): 33 34 #输入玩家猜测的年龄 35 choice=int(input()) 36 37 #判读玩家输入的年龄是否等于正确的年龄 38 if choice<age: 39 print('小埋的提示:你猜小了(;´д`)ゞ。。。。') 40 41 elif choice>age: 42 print('小埋的提示:乃猜大了惹(>﹏<)~~') 43 44 else: 45 print('猜了'+str(guess)+'次,你就猜对惹~hiu(^_^A;)~~~') 46 break 47 48 #判断猜测次数 49 if choice == age: 50 print('搜噶~那么小埋下线了~拜拜~( ̄︶ ̄)↗') 51 52 else: 53 print('哎呀~你还是木有猜对啊~但是你只有5次机会诶~怎么办啊~') 54 print('那好吧~心软的小埋只好告诉你,我才'+str(age)+'岁哦~(*/ω\*)')
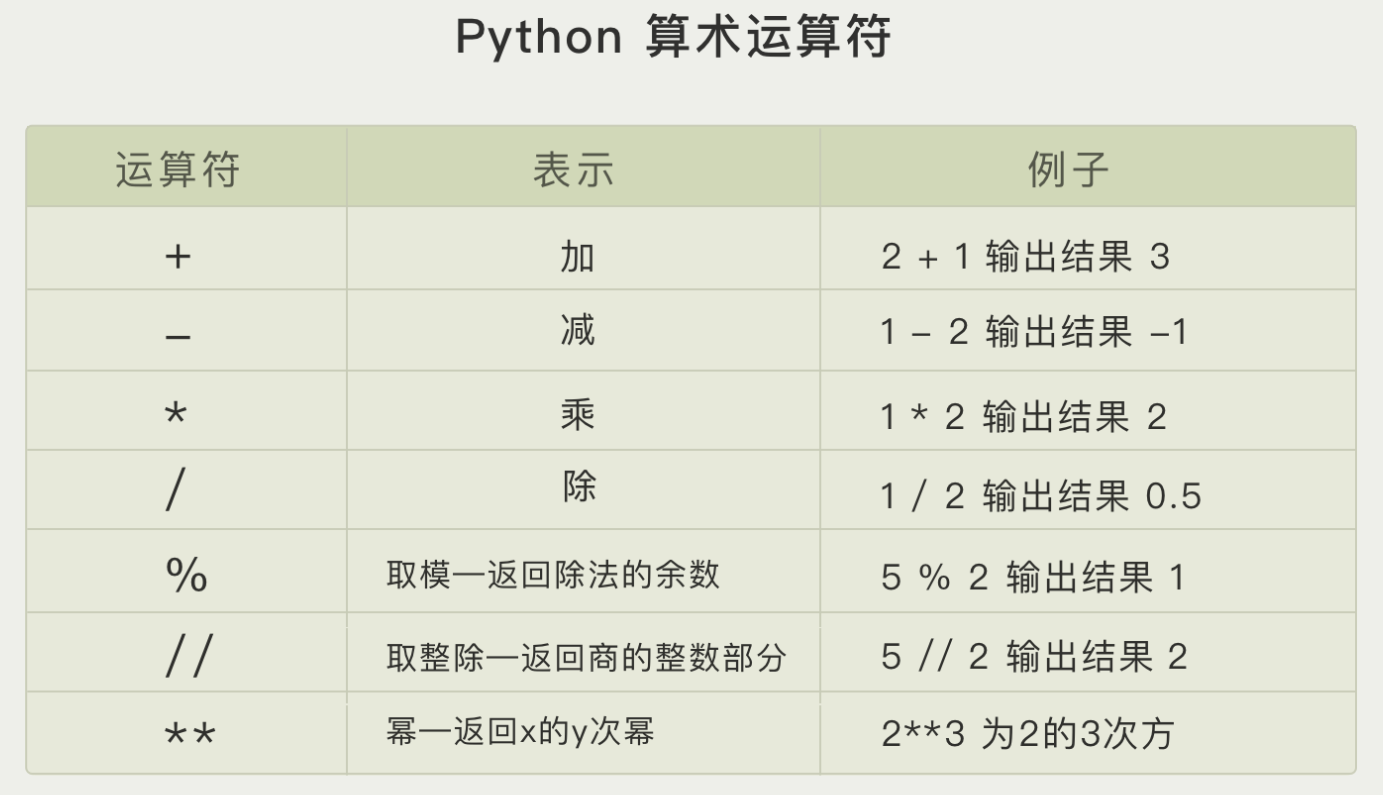
算术运算符 :+(加);-(减);*(乘);/ (除);//(取整除);%(取余) **(二次方)
示例
1 >>> 2+3 2 5 3 >>> 3-2 4 1 5 >>> 2*3 6 6 7 >>> 5/2 8 2.5 9 >>> 5//2 10 2 11 >>> 5%2 12 1 13 >>> 2**3 14 8
格式符 % #格式符%后面有一个字母s,这是一个类型码,用来控制数据显示的类型。%s就表示先占一个字符串类型的位置

常用s% d% f%
示例
1 #下面这两种写法是相同的 2 3 print('血量:'+str(player_life)+' 攻击:'+str(player_attack)) 4 print('血量:%s 攻击:%s' % (player_life,player_attack))
%f的意思是格式化字符串为浮点型,%.1f的意思是格式化字符串为浮点型,并保留1位小数
示例
1 # 无需修改代码,直接运行即可 2 3 # 工时计算 4 def estimated_time(size,number): 5 time = size * 80 / number 6 print('项目大小为%.1f个标准项目,使用%d个人力完成,则需要工时数量为:%.1f个' %(size,number,time)) 7 8 # 人力计算 9 def estimated_number(size,time): 10 number = size * 80 / time 11 print('项目大小为%.1f个标准项目,如果需要在%.1f个工时完成,则需要人力数量为:%d人' %(size,time,number)) 12 13 # 调用工时计算函数 14 estimated_time(1.5,2) 15 # 调用人力计算函数 16 estimated_number(0.5,20)
format()格式化函数 #格式化字符串format()函数用来占位的是大括号{},不用区分类型码(%+类型码)。具体的语法是:'str.format()',而不是课堂上提到的'str % ()'。
1 # format()格式化函数:str.format() 2 print('\n{}{}'.format('数字:',0)) # 优势1:不用担心用错类型码。 3 print('{},{}'.format(0,1)) # 不设置指定位置时,默认按顺序对应。 4 print('{1},{0}'.format(0,1)) # 优势2:当设置指定位置时,按指定的对应。 5 print('{0},{1},{0}'.format(0,1)) # 优势3:可多次调用format后的数据。 6 7 name2 = 'Python基础语法' 8 print('我正在学{}'.format(name2)) # format()函数也接受通过参数传入数据。
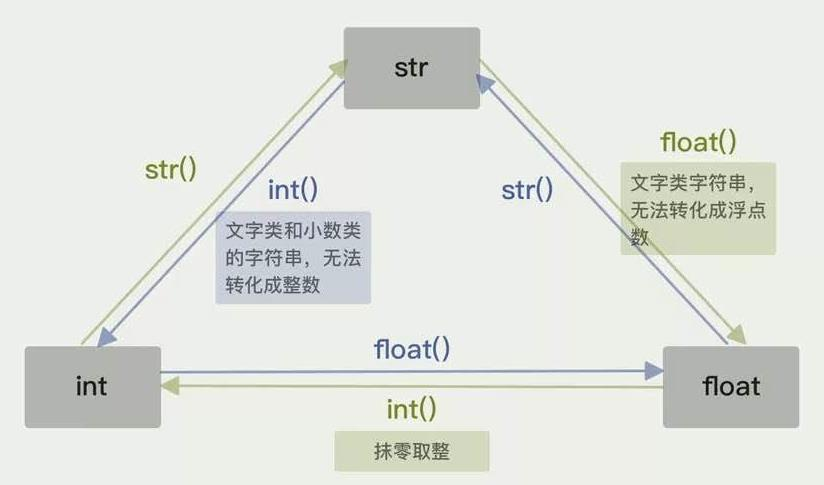
数据类型的查询——type()函数
示例
1 who = '我的' 2 action = '是' 3 destination = '镜像世界' 4 number = 153 5 code = '通行密码' 6 7 #type(需要查询的数据) 8 print(type(who)) 9 print(type(action)) 10 print(type(destination)) 11 print(type(number)) 12 print(type(code))
转换数据类型的方法
if条件判断逻辑
break语句 #是用来结束循环的,一般写作if...break
1 # break语句搭配for循环 2 for...in...: 3 ... 4 if ...: 5 break 6 7 # break语句搭配while循环 8 while...(条件): 9 ... 10 if ...: 11 break
1 # continue语句搭配for循环 2 for...in...: 3 ... 4 if ...: 5 continue 6 ... 7 8 # continue语句搭配while循环 9 while...(条件): 10 ... 11 if ...: 12 continue 13 ...

pass语句 #pass用来占据一个位置表示“什么都不做”,否则代码执行起来会报错
# 请体验一下报错,然后把pass语句加上 a = int(input('请输入一个整数:')) if a >= 100: pass else: print('你输入了一个小于100的数字') >>>不加pass,代码执行错误
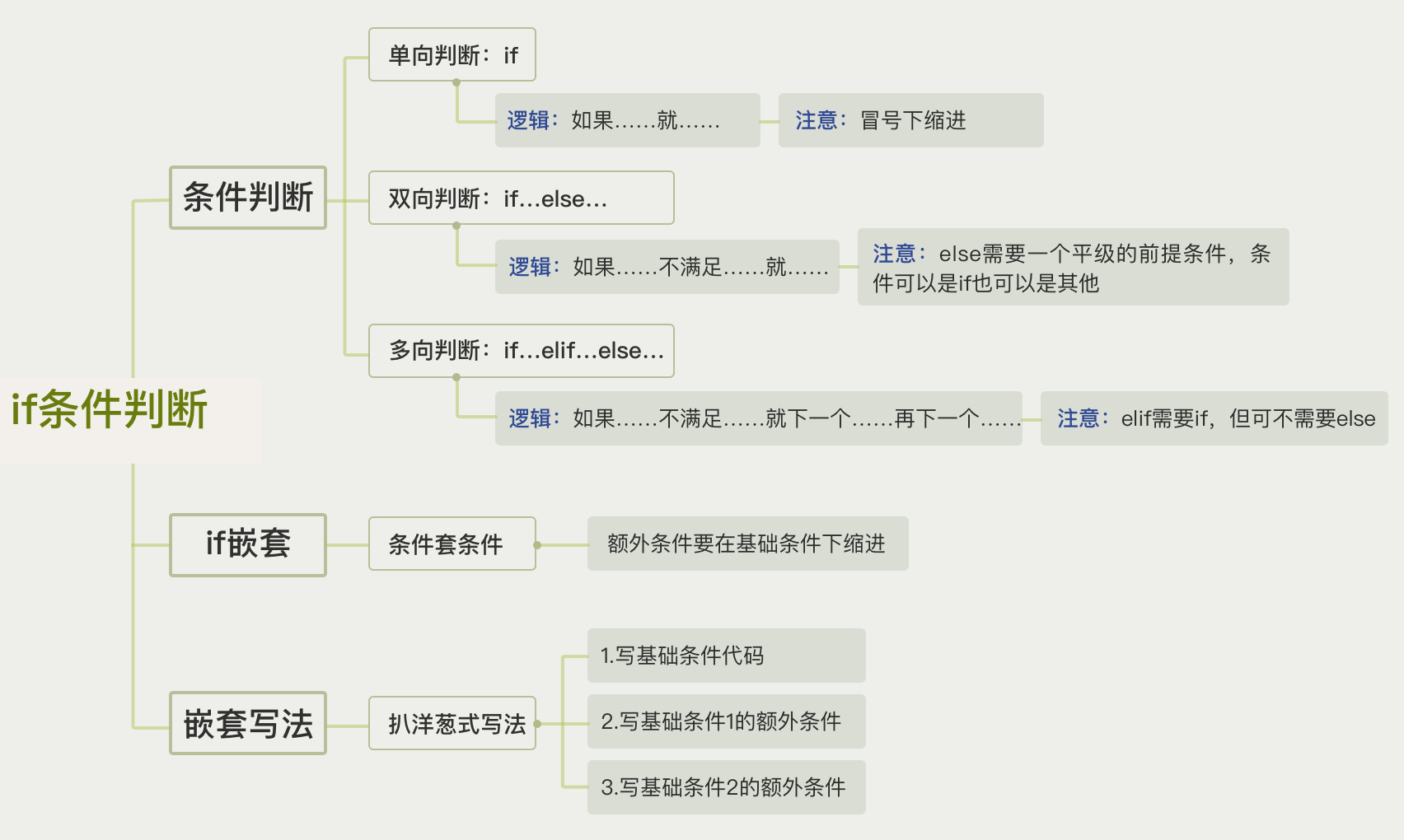
四种语句对比释义

比较运算符:>、 <、 >=、 <=、 ==、!= 得到True/False
顾名思义,比较运算符是用来做比较的,比较的结果会有两种,分别是成立和不成立,成立的时候,结果是 True,不成立的时候结果是False。 True和False 用来表示比较后的结果
1 >>> a = 5 2 >>> b = 3 3 >>> a > b # 检查左操作数的值是否大于右操作数的值,如果是,则条件成立。 4 True 5 >>> a < b # 检查左操作数的值是否小于右操作数的值,如果是,则条件成立。 6 False 7 >>> a <= b # 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立。 8 False 9 >>> a >= b # 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立。 10 True 11 >>> a == b # 检查,两个操作数的值是否相等,如果是则条件变为真。 12 False 13 >>> a != b # 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 14 True
赋值运算符
=、+=、-=、*=、/=、%=、//=、**=
num = 2 num += 1 # 等价于 num = num + 1 num -= 1 # 等价于 num = num - 1 num *= 1 # 等价于 num = num * 1 num /= 1 # 等价于 num = num / 1 num //= 1 # 等价于 num = num // 1 num %= 1 # 等价于 num = num % 1 num **= 2 # 等价于 num = num ** 2
逻辑运算符: not 、and、 or
逻辑运算符是用来做逻辑计算的。像我们上面用到的比较运算符,每一次比较其实就是一次条件判断,都会相应的得到一个为True或False的值。而逻辑运算符的的操作数就是一个用来做条件判断的表达式或者变量。
>>> a > b and a < b # 如果两个操作数都是True,那么结果为True,否则结果为False。 False >>> a > b or a < b # 如果有两个操作数至少有一个为True, 那么条件变为True,否则为False。 True >>> not a > b # 反转操作的状态,操作数为True,则结果为False,反之则为True False
结果为True的时候,我们一般称 结果为 真, 逻辑运算符会有一个真值表。
优先级
| 运算符 | 描述 |
| ** | 指数(最高优先级) |
|
~ + - |
按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >><< | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | 位运算符 |
| <= <> >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| nor or adn | 逻辑运算符 |
对应操作字符串类型
1 1 #重复输出字符串 2 print('hello'*20) 3 4 2 #[] ,[:] 通过索引获取字符串中字符,这里和列表的切片操作是相同的,具体内容见列表 5 print('helloworld'[2:]) 6 7 3 #关键字 in,查询字符串是否包含在内 8 print(123 in [23,45,123]) #在内返回true 9 print('e2l' in 'hello') #不在内返回false 10 11 4 #% 格式字符串 12 print('alex is a good teacher') 13 print('%s is a good teacher'%'alex') #变成一个可替代的变量,方便后期 14 15 5 #字符串拼接 16 a='123' 17 b='abc' 18 d='44' 19 # 老方法 20 c=a+b 21 print(c) 22 23 # 新方法 24 c= ''.join([a,b,d]) #留空字符串 25 print(c)
布尔值数据
python中设定的数据真假判断
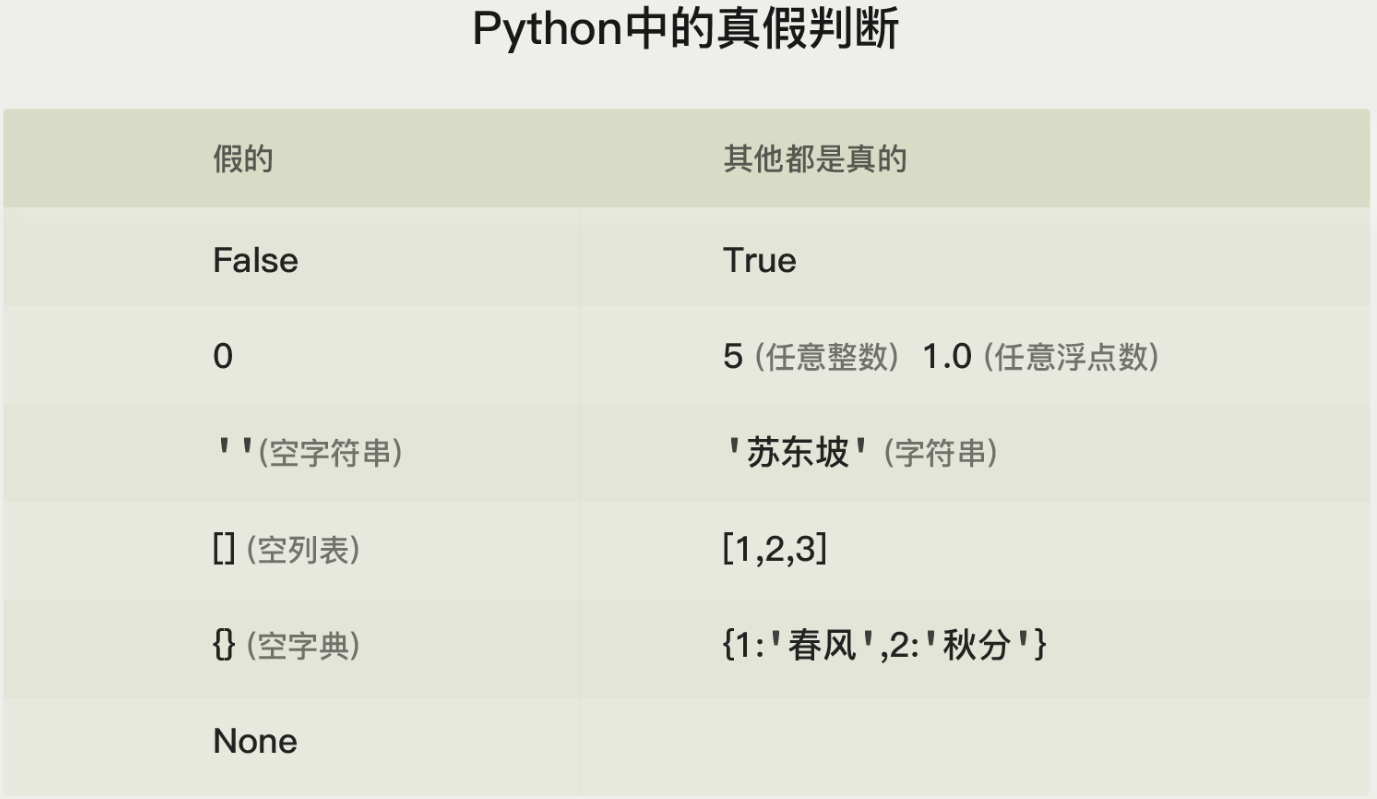
bool()函数来查看一个数据会被判断为真还是假
1 print('以下数据判断结果都是【假】:') 2 print(bool(False)) 3 print(bool(0)) 4 print(bool('')) 5 print(bool(None)) 6 7 print('以下数据判断结果都是【真】:') 8 print(bool(True)) 9 print(bool(1)) 10 print(bool('abc'))
数据类型
列表,元组
索引(下标) ,都是从0开始
切片
(口诀:左右空,取到头;左要取,右不取。)
1 a=['ming','hong','huang','ding','su'] 2 print(a[1:])#取到最后(从标位1开始取到最后) 3 >>> ['hong', 'huang', 'ding', 'su'] 4 5 print(a[1:-1])#取到倒数第二值(从下标1位取到倒数第二值) 6 >>> ['hong', 'huang', 'ding'] 7 8 print(a[1:-1:1])#从左到右一个一个去取(从左下标1开始到倒数第二值,步长1) 9 >>> ['hong', 'huang', 'ding'] 10 11 print(a[1::2])#从左到右隔一个去取 12 >>> ['hong', 'ding'] 13 14 print(a[3::-1])#从下标3开始,隔一个倒着去取 15 >>> ['ding', 'huang', 'hong', 'ming'] 16 17 print(a[-2::-1])#从倒数第二个开始,隔一个倒着去取 18 >>> ['ding', 'huang', 'hong', 'ming']
查
.count() #查某个元素的出现次数
1 t=['to','be','or','not','to','be',].count('to') 2 print(t) 3 >>> 2
.index() #用于找出列表中某个元素第一次出现的索引位置
1 a = ['ming','hong','huang','ding','su'] 2 print(a.index('hong')) 3 >>> 1
示例
1 import random 2 3 # 出拳 4 punches = ['石头','剪刀','布'] 5 computer_choice = random.choice(punches) 6 user_choice = '' 7 user_choice = input('请出拳:(石头、剪刀、布)') # 请用户输入选择 8 while user_choice not in punches: # 当用户输入错误,提示错误,重新输入 9 print('输入有误,请重新出拳') 10 user_choice = input() 11 12 # 亮拳 13 print('————战斗过程————') 14 print('电脑出了:%s' % computer_choice) 15 print('你出了:%s' % user_choice) 16 17 # 胜负 18 print('—————结果—————') 19 if user_choice == computer_choice: # 使用if进行条件判断 20 print('平局!') 21 # 电脑的选择有3种,索引位置分别是:0石头、1剪刀、2布。 22 # 假设在电脑索引位置上减1,对应:-1布,0石头,1剪刀,皆胜。 23 elif user_choice == punches[punches.index(computer_choice)-1]: 24 print('你赢了!') 25 else: 26 print('你输了!')
"内容" in 列表 #查询内容是不是在列表里面
1 a = ['ming','hong','huang','ding','su'] 2 print ('zhu' in a) 3 >>> False
len() #查一个列表或者字典的长度(元素个数)
1 students = ['小明','小红','小刚'] 2 scores = {'小明':95,'小红':90,'小刚':90} 3 print(len(students)) 4 print(len(scores)) 5 >>>3 6 >>>3
增加
.append() 追加
1 a = ['ming','hong','huang','ding','su'] 2 a.append('xuepeng') #默认查到最后一个位置 3 print(a) 4 >>> ['ming', 'hong', 'huang', 'ding', 'su', 'xuepeng'] 5 a.insert(1,'xuepeng') #将数据插入到任意一个位置,1是下标 6 print(a) 7 >>> ['ming', 'xuepeng', 'hong', 'huang', 'ding', 'su', 'xuepeng']
.insert(index, "内容") #在某个位置(index)插入内容
1 a = ['ming','hong','huang','ding','su'] 2 a.insert(1,'zhu') 3 print(a) 4 >>>['ming', 'zhu', 'hong', 'huang', 'ding', 'su']
列表.extend(列表) #某列表加入某列表
1 a = [1,2,3] 2 b = [4,5,6] 3 a.extend(b) 4 print (a) 5 >>> a = [1,2,3,4,5,6] 6 print (b) 7 >>> b = [4,5,6]
修改
a[index] = "新的值" # 赋予"新的值"
1 a = ['ming','hong','huang','ding','su'] 2 a[0] = "zhu" 3 print(a) 4 >>>['zhu', 'hong', 'huang', 'ding', 'su']
a[start:end] = [a,b,c] #重新对列表赋值
1 a = ['ming','hong','huang','ding','su'] 2 a[1:3] = ["a","b"] #包含1的位置到2位置(前包后不包原则) 3 print(a) 4 >>>['ming', 'a', 'b', 'ding', 'su']
删除
del a
a=['ming','hong','huang','ding','su'] del a print(a) #是报错的,因为a列表已经被删除了 >>>NameError: name 'a' is not defined
del a[index] #删除在列表中已知位置的的元素
1 a = ['ming','hong','huang','ding','su'] 2 del a[0] #直接删除a列表内0下标的元素 3 print(a) 4 >>>['hong', 'huang', 'ding', 'su']
remove("内容")
1 a = ['ming','hong','huang','ding','su'] 2 a.remove('ming') #直接删除知道的元素名 3 print(a) 4 >>>['hong', 'huang', 'ding', 'su']
pop(index) #删除指定位置的元素并返回这个被删除了的元素
a = ['ming','hong','huang','ding','su'] b = a.pop(1) #删除指定位置的元素并返回这个被删除了的元素 c = a.pop() #不填下标的话,直接删除最后一个元素 print(a) >>>['ming', 'huang', 'ding', 'su'] print(b) >>>hong print(c) >>>['ming','hong','huang','ding']
a.clear() #清空列表所有元素
1 a = ['ming','hong','huang','ding','su'] 2 a.clear() #清空a列表内所有元素 3 print(a) 4 >>>[]
5 b = a.clear() 6 print(b) 7 >>>None
排序
sort () #列表从小到大重新排序
1 x = [4,6,2,1,7,9] 2 x.sort() 3 print(x) 4 >>> [1, 2, 4, 6, 7, 9]
reverse() #使列表倒序排列
1 a=['ming','hong','huang','ding','su'] 2 a.reverse() 3 print(a) 4 >>> ['su', 'ding', 'huang', 'hong', 'ming']
身份判断(疑问)
>>> type(a) is list
True
>>>
列表拓展知识
a = ['xiaohong','jinxin','xiaohu','xiaoming','sanpang','xiaoming'] #计算列表两个同名字的位置 first_xm_index = a.index("xiaoming") #get the first xiaoming print("first_xm_index",first_xm_index) little_list = a[first_xm_index+1:] #切片取小列表 second_xm_index = little_list.index("xiaoming") #取第二个小明在小列表里的位置 print("second_xm_index",second_xm_index) second_xm_index_in_big_list = first_xm_index + second_xm_index + 1 #通过第一个小明和第二个小明位置来计算 第二个小明在大列表里的位置 print("second_xm_index_in_big_list",second_xm_index_in_big_list) print("second xm:",a[second_xm_index_in_big_list]) <<<first_xm_index 3 <<<second_xm_index 1 <<<second_xm_index_in_big_list 5 <<<second xm: xiaoming
元组
tuple() #类似列表,但元组元素可取,不可改变
1 a = (1,2,3,4) 2 print(a[1]) 3 >>> (2) #跟列表一样可以取值 4 5 print(a[1:2]) 6 >>> (2,) #元组的索引都有逗号 7 8 print(a[1:3]) 9 >>> (2,3) 10 11 a[1] = 5 #元组不可改变元素 12 print(a) 13 >>> 报错
元组中的不定长参数 #即传递给参数的数量是可选的、不确定的。它的格式比较特殊,是一个星号*加上参数名,它的返回值也比较特殊
1 def menu(*barbeque): 2 return barbeque 3 4 order = menu('烤鸡翅','烤茄子','烤玉米') 5 #括号里的这几个值都会传递给参数barbeque 6 7 print(order) 8 print(type(order))
>>>('烤鸡翅', '烤茄子', '烤玉米')
>>> <class 'tuple'>
六、Dictionary(字典)
字典两大特点:无序,键唯一
不可变类型:整型,字符串,元组
可变类型:列表,字典
1 dic={'name':'alex','age':35,'hobby':'girl','is_handsome':True} 2 print(dic) 3 print(dic['name'])#name 整型,不可修改,不报错
1 dic={'[1,2,3]':'alex','age':35,'hobby':'girl','is_handsome':True} 2 print(dic) 3 print(dic['1'])#[1,2,3]不是整型,时列表,可修改,报错
1 dic={'1':'alex','age':35,'hobby':{'girl_name':'铁锤','age':45},'is_handsome':True} #{'girl_name':'铁锤','age':45}是键值可以用字典 2 print(dic['hobby']) #不报错 1 dic={{'1':'111'}:'alex','age':35,'hobby':{'girl_name':'铁锤','age':45},'is_handsome':True} #{'1':'111'}这个是键,不可以用字典表示 2 print(dic['hobby']) #报错
1、增
1 dic1 = {'name':'alex'} 2 dic1['age']=18 #由于键'age'是没有的,所以会变成增加 3 print(dic1)
1 dic1 = {'name':'alex'} 2 dic1['age'] = 18 3 print(dic1) 4 5 #键存在,不改动的情况下,返回字典中相应的键对应的值 6 ret1 = dic1.setdefault('age','34') 7 print(dic1) 8 9 #键不存在,在字典中增加新的键值对,并返回一个参数'ret2' 10 ret2 = dic1.setdefault('hobby','girl') 11 print(dic1)
2、查
1 dic3 = {'age':18, 'name':'alex', 'hobby':'girl' }#空格无所谓 2 print(dic3['name']) 3 print(type(dic3.keys())) 4 #print出的结果是<class 'dict_keys'>,不是一个dict_key类型 5 6 #想用其中的键的话 7 print(list(dic3.keys())) 8 9 #想用其中的键值的话 10 print(list(dic3.values())) 11 12 #想用其中的键值对的话 13 print(list(dic3.items()))
3、改
1 dic3 = {'age':18, 'name':'alex', 'hobby':'girl' } 2 print(dic3) 3 4 dic3['age'] = 55#跟列表修改大致,列表利用位置,字典利用键 5 print(dic3)
1 dic4 = {'age':18, 'name':'alex', 'hobby':'girl'} 2 3 #如果update的内容,是新的键值对,那会新增 4 dic5 = {'1':'111', '2':'222'} 5 dic4.update(dic5)#提供了dic5给他更新 6 print(dic4) 7 print(dic5) 8 9 #如果updata的内容,是已有的键,不同的值,那会修改 10 dic6 = {'1':'111', '2':'3333333'} 11 dic4.update(dic6)#提供了dic6给他更新 12 print(dic4)
4、删
clear、del、pop直接删除某个键下的值
dic5 = { 'name':'alex', 'age':18, 'class':'1'}
dic5.clear() #清空字典
print(dic5)
dic5 = { 'name':'alex', 'age':18, 'class':'1'}
del dic5['name'] #删除字典中指定键值对
print(dic5)
dic5 = { 'name':'alex', 'age':18, 'class':'1'}
ret = dic5.pop('age') #pop返回该键值对的值
print(dic5)
print(ret)
5、其他操作以及涉及到的方法
5.1 dict.fromkeys
dic6=dict.fromkeys(['host1','host2','host3'],'test') print(dic6) #{'host1': 'test', 'host2': 'test', 'host3': 'test'} dic6['host2']='abc' print(dic6) dic6=dict.fromkeys(['host1','host2','host3'],['test1','tets2']) print(dic6) #{'host1': ['test1', 'tets2'], 'host2': ['test1', 'tets2'], 'host3': ['test1', 'tets2']} dic6['host2'][1]='test3'#只改一个,但是后面所有都变 print(dic6) #{'host3': ['test1', 'test3'], 'host2': ['test1', 'test3'], 'host1': ['test1', 'test3']}
5.2 d.copy() 对字典 d 进行浅复制,返回一个和d有相同键值对的新字典
5.3 字典嵌套
5.4 sorted(dict):返回一个有序的包含字典所有key的列表
dic={5:'555',2:'666',4:'444'}
print(sorted(dic))
#输出[2,4,5],排序并提供key
#print(sorted(dic.values()))
#输出['222','555','666']
#print(sorted(dic.items()))
#输出[(2,'666'),(4,'444'),(5,'555')]
5.5 字典的遍历
dic5={'name': 'alex', 'age': 18}
for i in dic5:
print(i,dic5[i])
#一开始print(i),只是把健输出,加入dic5[i]就,可以一同输出
for i,v in dic5.items():
print(i,v)
#另一种表达,推荐第一种
遍历
for...in...循环

示例:
#for遍历列表
1 for i in [1,2,3,4,5]: 2 print(i) 3 4 >>>1 5 >>>2 6 >>>3 7 >>>4 8 >>>5
#for遍历字典(取键)
1 dict = {'日本':'东京','英国':'伦敦','法国':'巴黎'} 2 3 for i in dict: 4 print(i) 5 >>>日本 6 >>>英国 7 >>>法国
#for遍历字典(取值)
1 d = {'小明':'醋','小红':'油','小白':'盐','小张':'米'} 2 3 for i in d: 4 print(d[i]) 5 6 >>>醋 7 >>>油 8 >>>盐 9 >>>米
range(a,b) 函数 #生成一个【取头不取尾】的整数序列
1 for i in range(13,17):
2 print(i)
3
4 >>>13
5 >>>14
6 >>>15
7 >>>16
#把一段代码固定重复n次
1 for i in range(3):
2 print('我很棒')
3
4 >>>我很棒
5 >>>我很棒
6 >>>我很棒
#步长写法

while循环

示例
(当(while)没有男人愿意为小龙女去死的时候,小龙女要一直一直一直生活在古墓里,这就是一种循环。只有当条件(没有男人愿意为小龙女去死)为假的时候,就可以打破循环,小龙女就能出古墓下山了。)
1 man = '' # 注:''代表空字符串 2 while man != '有': #注:!=代表不等于 3 man = input('有没有愿意为小龙女死的男人?没有的话就不能出古墓。') 4 print('小龙女可以出古墓门下山啦~')
if和while有个显著的区别。那就是if语句只会执行一次,而while是循环语句,只要条件判断为真,就一直循环执行。

理解循环

八、函数
print()函数 #完整的参数
print(*objects, sep = ' ', end = '\n', file = sys.stdout, flush = False)
1 print('金枪鱼', '三文鱼', '鲷鱼') 2 print('金枪鱼', '三文鱼', '鲷鱼', sep = '+') 3 # sep控制多个值之间的分隔符,默认是空格 4 print('金枪鱼', '三文鱼', '鲷鱼', sep = '+', end = '=?') 5 # end控制打印结果的结尾,默认是换行) 6 7 >>>金枪鱼 三文鱼 鲷鱼 8 >>>金枪鱼+三文鱼+鲷鱼 9 >>>金枪鱼+三文鱼+鲷鱼=?
返回多个值
依旧回到我们的食堂,后来你决定推出不定额的优惠券,到店顾客均可参与抽奖:5元以下随机赠送一碟小菜,5-10元随机赠送一碟餐前小菜和一个溏心蛋。
一、要返回多个值,只需将返回的值写在return语句后面,用英文逗号隔开即可
示例
1 import random 2 appetizer = ['话梅花生','拍黄瓜','凉拌三丝'] 3 def coupon(money): 4 if money < 5: 5 a = random.choice(appetizer) 6 return a 7 elif 5 <= money < 10: 8 b = random.choice (appetizer) 9 return b, '溏心蛋' 10 11 print(coupon(6)) 12 print(type(coupon(6)))
>>>('话梅花生', '溏心蛋') >>><class 'tuple'>
二、另外一种方式:我们也可以同时定义多个变量,来接收元组中的多个元素
示例
1 import random 2 3 appetizer = ['话梅花生', '拍黄瓜', '凉拌三丝'] 4 5 def coupon(money): 6 if money < 5: 7 a = random.choice(appetizer) 8 return a, '' 9 elif 5 <= money < 10: 10 b = random.choice(appetizer) 11 return b, '溏心蛋' 12 13 dish, egg = coupon(7) 14 # 元组的两个元素分别赋值给变量dish和egg 15 print(dish) 16 print(egg)
>>>拍黄瓜
>>>溏心蛋
 我们可以把这里的参数等同于输入,函数体等同于执行过程,return语句等同于输出
我们可以把这里的参数等同于输入,函数体等同于执行过程,return语句等同于输出
定义函数语法注意事项:
函数名:1. 名字最好能体现函数的功能,一般用小写字母和单下划线、数字等组合
# 2. 不可与内置函数重名(内置函数不需要定义即可直接使用)
def math(x):
# 参数:根据函数功能,括号里可以有多个参数,也可以不带参数,命名规则与函数名相同
# 规范:括号是英文括号,后面的冒号不能丢
y = 3*x + 5
# 函数体:函数的执行过程,体现函数功能的语句,要缩进,一般是四个空格
return y
# return语句:后面可以接多种数据类型,如果函数不需要返回值的话,可以省略
全局变量
# 声明全局变量key,以便修改该变量
示例: global key之后,key变量可以被修改
1 def again(): 2 # 声明全局变量key,以便修改该变量 3 global key 4 a = input('是否继续计算?继续请输入y,输入其他键将结束程序。') 5 if a != 'y': 6 # 如果用户不输入'y',则把key赋值为0 7 key = 0
嵌套函数
我们可以把每个独立的功能封装到每个单独的函数中,然后用一个主函数打包这些单独的函数,最后再调用主函数

九、类
类的创建
类的含义

PS:参数self的特殊之处:在定义时不能丢,在调用时要忽略
类的调用

调用的语法是 实例名.属性 和 实例名.方法
示例:
1 class Computer: 2 screen = True 3 4 def start(self): 5 print('电脑正在开机中……') 6 7 my_computer = Computer() 8 print(my_computer.screen) 9 my_computer.start()
倒数第二行:my_computer.screen先是获取到类属性screen对应的值True,再用print()打印出来。
最后一行:my_computer.start()调用方法start(),这个方法的功能是直接打印出'电脑正在开机中……'。

特殊参数self的作用:self会接收实例化过程中传入的数据,当实例对象创建后,实例便会代替 self,在代码中运行。
换言之,self 是所有实例的替身,“替身”是什么意思呢?我们来看一个例子。

示例
1 class Chinese: 2 3 name = '吴枫' # 类属性name 4 5 def say(person): 6 print(person.name + '是中国人') 7 8 person = Chinese() # 创建Chinese的实例person 9 person.say() # 调用实例方法
所以我们说self代表的是类的实例本身,方便数据的流转。对此,我们需要记住两点:
第一点:只要在类中用def创建方法时,就必须把第一个参数位置留给 self,并在调用方法时忽略它(不用给self传参)。
第二点:当在类的方法内部想调用类属性或其他方法时,就要采用self.属性名或self.方法名的格式。
类的初始化函数

案例: 创建一个机器人,让其具备以下功能: 一是会让你给ta 起名,也会问你的名字,然后跟你打招呼(如“你好,吴枫。我是瓦力。遇见你,真好。”); 二是会让你说一个愿望,然后帮你重复三次(因为 ta 觉得重要)。 1 class robot: 2 def __init__(self): 3 self.robot_name = input("感谢您,创造了我,帮我起个名字吧!:") 4 self.human_name = input("主人!要怎么称呼您名呢?:") 5 print("您好%s,我叫%s,很开心,遇见你,真好。"%(self.human_name,self.robot_name)) 6 7 def say_wish(self): 8 wish = input("告诉我,您的愿望是什么:") 9 print(self.human_name + "的愿望是:") 10 for i in range(3): 11 print(wish) 12 13 robot1 = robot() 14 robot1.say_wish()
类的继承
1 class Chinese: 2 eye = 'black' 3 4 def eat(self): 5 print('吃饭,选择用筷子。') 6 7 class Cantonese(Chinese): 8 # 通过继承,Chinese类有的,Cantonese类也有 9 pass 10 11 # 验证子类可以继承父类的属性和方法,进而传递给子类创建的实例 12 yewen = Cantonese() 13 # 子类创建的实例,从子类那间接得到了父类的所有属性和方法 14 print(yewen.eye) 15 # 子类创建的实例,可调用父类的属性 16 yewen.eat() 17 # 子类创建的实例,可调用父类的方法
各级实例和各级类间的关系

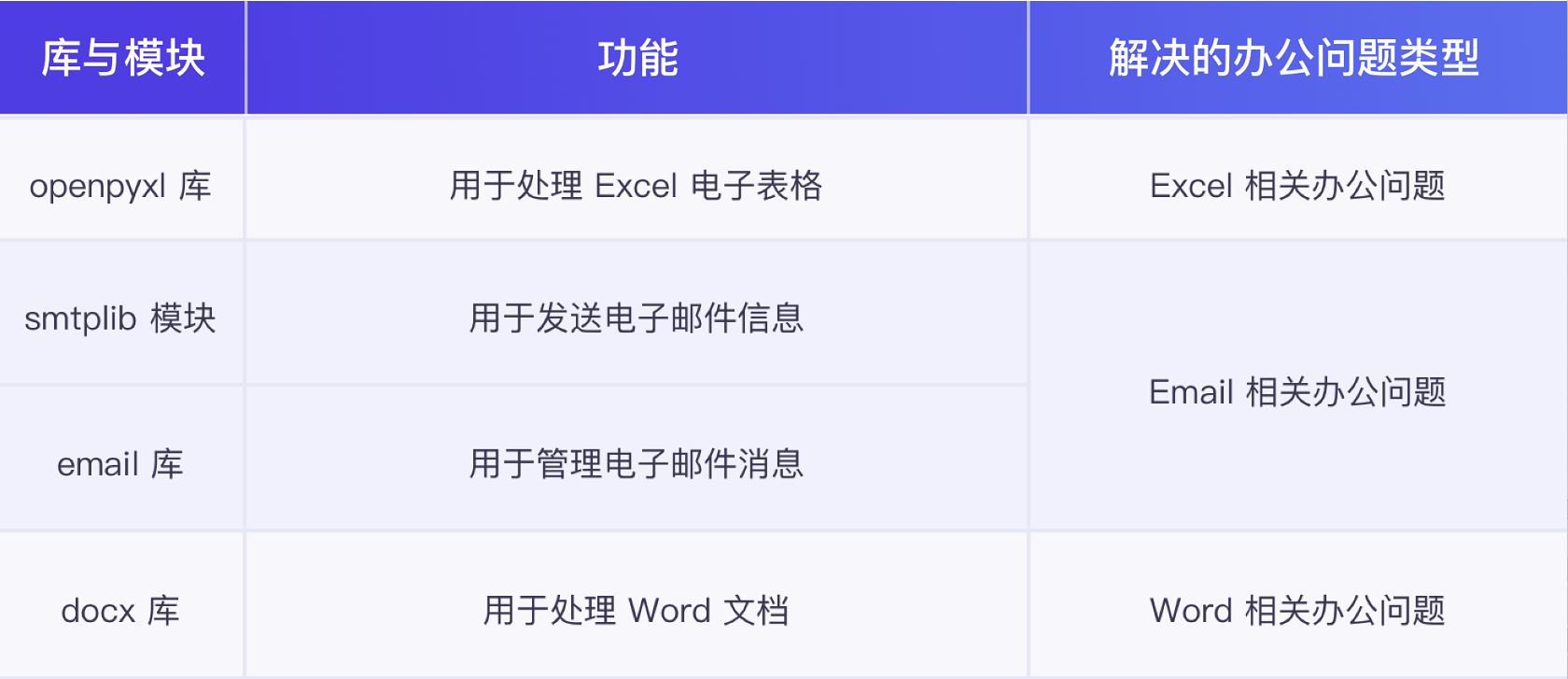
相关库与模块
time模块
sleep(secs)函数 #使用time模块下面的sleep()函数,括号里填的是间隔的秒数(seconds,简称secs)
1 import time #调用time模块 2 time.sleep(secs) 3 #使用time模块下面的sleep()函数,括号里填的是间隔的秒数(seconds,简称secs) 4 #time.sleep(1.5)就表示停留1.5秒再运行后续代码
math模块
sleep(secs)函数 #使用time模块下面的sleep()函数,括号里填的是间隔的秒数(seconds,简称secs)
1、向下取整: int()
1 a= 14.38 2 int(a) 3 4 >>>14
2、向上取整:ceil()
1 import math 2 math.ceil(3.33) 3 >>>4 4 5 math.ceil(3.88) 6 >>>4
3、四舍五入:round()
1 round(4.4) 2 >>>4 3 4 round(4.6) 5 >>>5
4、分别取
将整数部分和小数部分分别取出,可以使用math模块中的 modf()方法
1 math.modf(4.25) 2 >>>(0.25,4.0) 3 4 math.modf(4.33) 5 >>>(0.33000000000000007,4.0) 6 7 #最后一个应该是0.33,但是浮点数在计算机中是无法精确的表示小数的,python采用IEEE 754规范来存储浮点数。
random模块
random.randint(a,b)函数(随机整数)
random.randint(a,b) #括号里放的是两个整数,划定随机生成整数的范围
1 import random 2 #调用random模块,与 3 a = random.randint(1,100) 4 # 随机生成1-100范围内(含1和100)的一个整数,并赋值给变量a 5 print(a) 6 7 >>>随机在1-100生成数字
示例(抛硬币)
1 import random 2 3 all = ['正面','反面'] 4 guess = '' 5 6 while guess not in all: 7 print('------猜硬币游戏------') 8 print('猜一猜硬币是正面还是反面?') 9 guess = input('请输入“正面”或“反面”:') 10 11 # 随机抛硬币,0代表正面,1代表反面 12 toss = all[random.randint(0,1)] 13 14 if toss == guess: 15 print('猜对了!你真棒') 16 else: 17 print('没猜对,再给你一次机会。') 18 guess = input('再输一次(“正面”或“反面”):') 19 if toss == guess: 20 print('你终于猜对了!') 21 else: 22 print('大失败!')
示例
1 #这些通告都是 Word 文件,阿威要在这些文件结尾处加上公司的电子章与公司名称,并且需要调整文字的字号,加粗和对齐方式。 2 3 import os 4 from docx import Document 5 from docx.enum.text import WD_ALIGN_PARAGRAPH 6 from docx.shared import Pt 7 8 # 设置目标文件夹路径 9 path = './通告模板/' 10 path_target = './涨薪通告/' 11 12 # 获取目标文件夹下的所有文件名 13 file_list = os.listdir(path) 14 15 for file in file_list: 16 # 拼接文件路径 17 file_path = path + file 18 19 # 打开 Word 文件 20 doc = Document(file_path) 21 22 # 添加 Paragraph 对象 para_1 23 para_1 = doc.add_paragraph('盖章: ') 24 # 添加 Run 对象 run_stamp 25 run_stamp = para_1.add_run() 26 run_stamp.add_picture('./Shining.png') 27 28 # 添加 Paragraph 对象 para_2 29 para_2 = doc.add_paragraph() 30 # 设置对齐方式 31 para_2.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.RIGHT 32 # 添加 Run 对象 run_comp 33 run_comp = para_2.add_run('闪光科技金融公司(Shining Fintech Company)') 34 # 设置字体 35 run_comp.font.size = Pt(14) # 字体大小 36 run_comp.font.bold = True # 字体加粗 37 38 # 设置目标文件夹路径 39 new_file = path_target + file 40 # 保存文件 41 doc.save(new_file) 42 print(f'{file} 已处理完毕。')
re 模块是regular expression的缩写,中文名叫正则表达式,主要用来匹配字符串,从字符串中获取我们想要的特定信息。
re 模块中的re.findall()可以设置一定规则,获取一段字符串中所有与我们设置的规则相匹配的信息。

requests.get()是用来向一个网址发起网络请求的。括号里面写的就是【东方财富网全球财经快讯】的网址https://kuaixun.eastmoney.com/。
示例
1 # 导入模块 2 import re 3 4 # 将古诗赋值poem变量 5 poem = ''' 6 《出塞》 7 [唐] 8 王昌龄 9 秦时明月汉时关,万里长征人未还。 10 但使龙城飞将在,不教胡马度阴山。 11 12 《春晓》 13 [唐] 14 孟浩然 15 春眠不觉晓,处处闻啼鸟。 16 夜来风雨声,花落知多少。 17 18 《杂诗》 19 [唐] 20 王维 21 君自故乡来,应知故乡事。 22 来日绮窗前,寒梅著花未? 23 24 《寻隐者不遇》 25 [唐] 26 贾岛 27 松下问童子,言师采药去。 28 只在此山中,云深不知处。 29 30 《早发白帝城》 31 [唐] 32 李白 33 朝辞白帝彩云间,千里江陵一日还。 34 两岸猿声啼不住,轻舟已过万重山。 35 ''' 36 # 提取唐诗标题 37 title = re.findall('《.*?》',poem) 38 # 打印唐诗标题 39 print(title)
数据统计指标相关语法:
pandas 库是一个专门用来解决数据分析问题的库
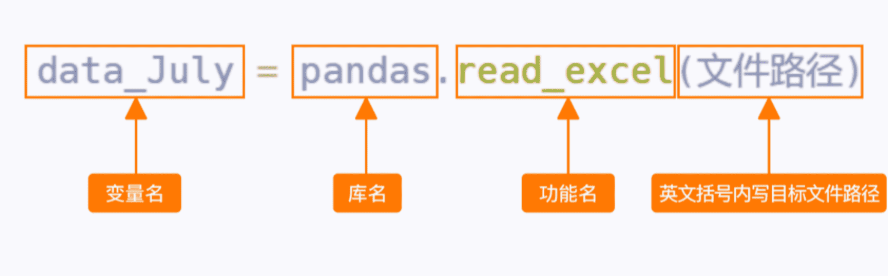
pandas.read_excel()
功能:用来读取指定文件路径的Excel文件数据
语法:pandas.read_excel(文件路径)
示例:data_July=pandas.read_excel('work/7月份销售数据.xlsx')
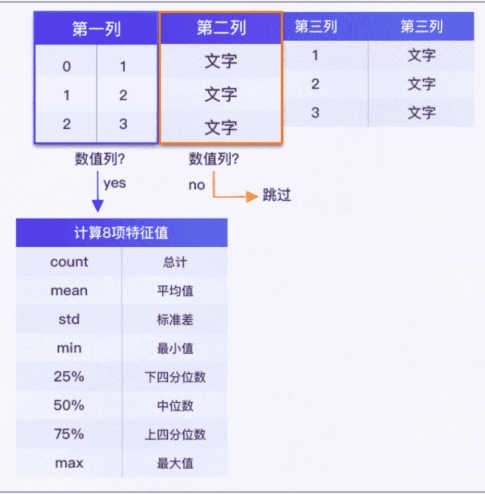
describe()
功能:将数据中属于数值列的8项统计指标计算出来
示例:data_July.describe()
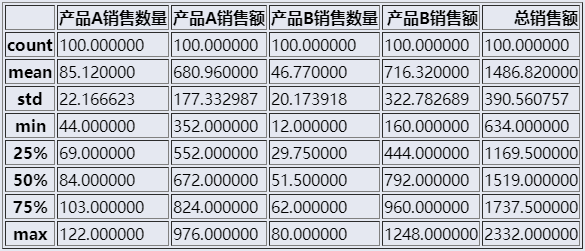
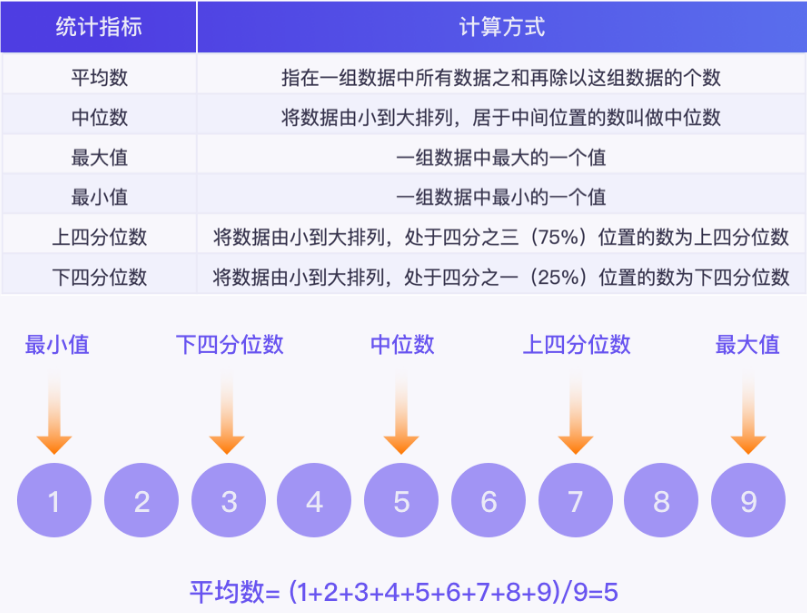
释义
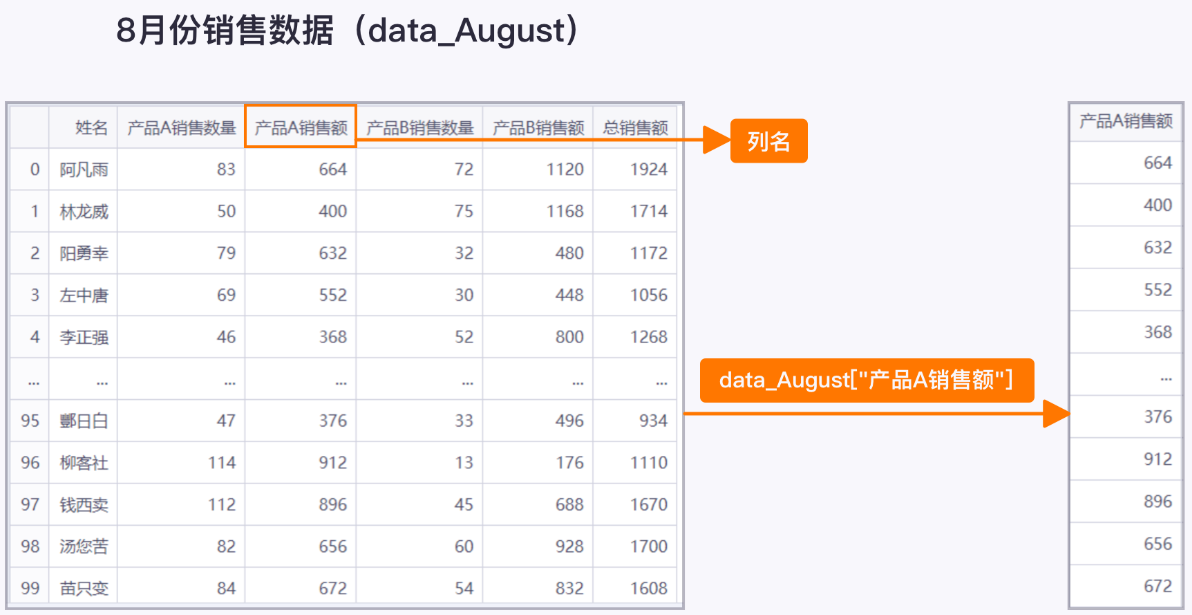
data_August["列名"]
功能:取出data_August 数据中的某列数据
示例:data_August["产品A销售额"]
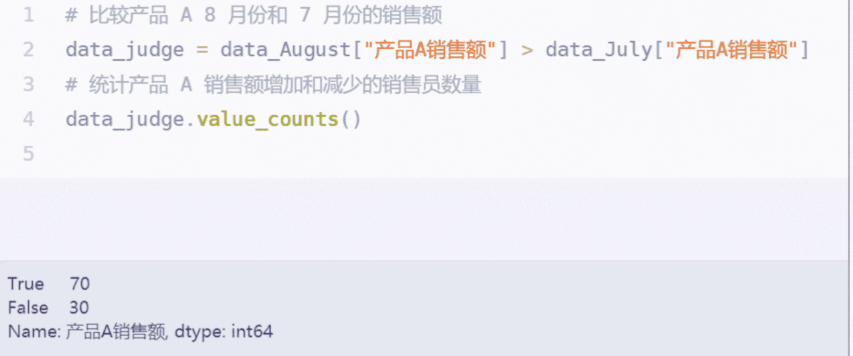
value_counts()
功能:可以自动统计True和False的数量(统计上方不同列表列名的对比)
示例:data_judge.value_counts()
NumPy库 import numpy as np
如:nums = [0,4,5,8,8]
#均值
np.mean(nums)
#中位数
np.median(nums)
示例 #取平均值,取小于平均值的数据
1 import numpy as np # 导入 numpy库,下面出现的 np 即 numpy库 2 3 scores1 = [91, 95, 97, 99, 92, 93, 96, 98] 4 scores2 = [] 5 6 average = np.mean(scores1) # 一行解决。 7 print('平均成绩是:{}'.format(average)) 8 9 for score in scores1: 10 if score < average: 11 scores2.append(score) # 少于平均分的成绩放到新建的空列表中 12 print(' 低于平均成绩的有:{}'.format(scores2)) # 上个关卡选做题的知识。 13 14 # 下面展示一种NumPy数组的操作 15 scores3 = np.array(scores1) 16 print(' 低于平均成绩的有:{}'.format(scores3[scores3<average])) 17 18 >>>平均成绩是:95.125 19 >>>低于平均成绩的有:[91, 95, 92, 93] 20 >>>低于平均成绩的有:[91 95 92 93]
数据分析步骤


RFM模型
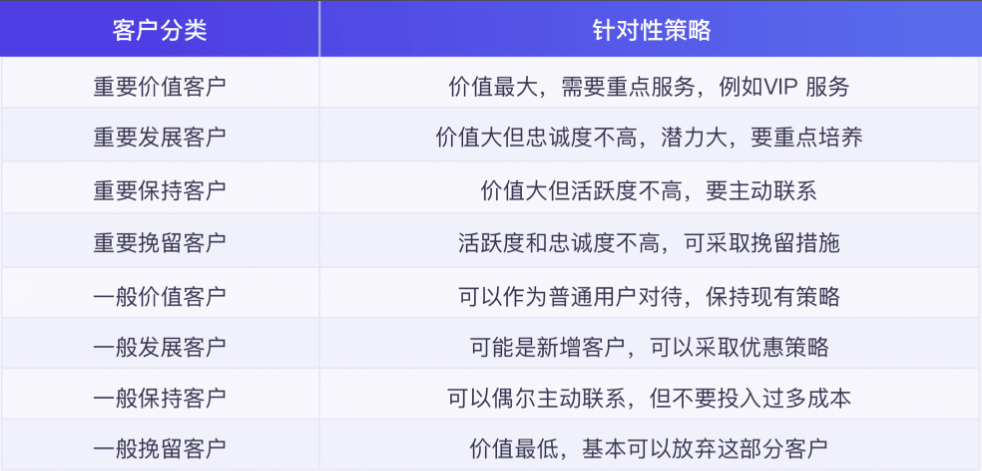
R、F、M 是这三项指标的缩写,它们三个字母的含义分别是:
R —— 英文 Recency 的缩写,代表用户最近一次消费到现在的时间间隔。
F —— 英文 Frequency 的缩写,代表用户在一段时间内的交易次数。
M —— 英文 Monetary 的缩写,代表用户在一段时间内的交易金额。

而 RFM 模型就是根据这三个指标去衡量客户的价值,按照不同的价值水平去分类客户。例如价值大的客户,值得去投入更多成本。
最后再来明确一下目标:基于 RFM 模型对客户进行分类,针对性地采取营销策略。
示例
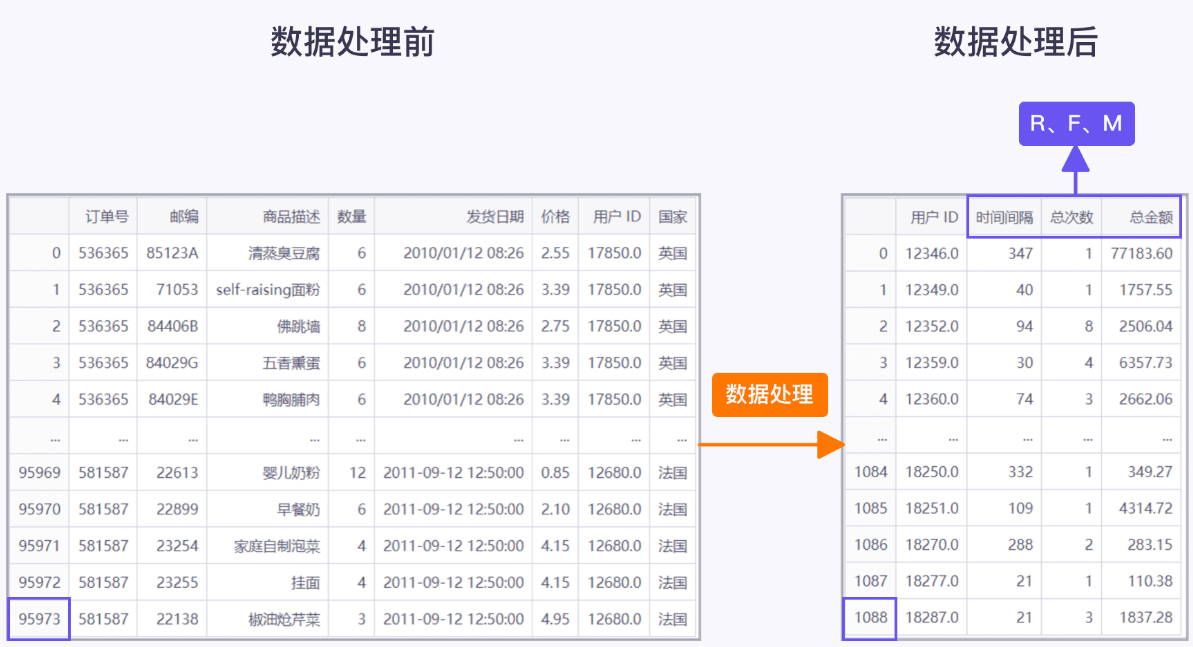
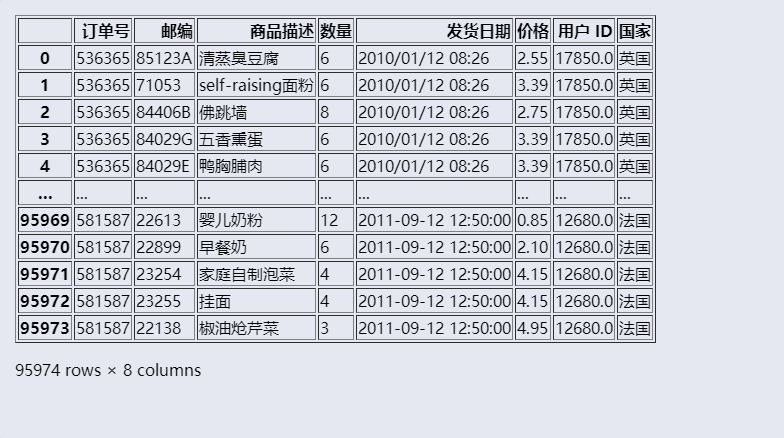
整理前
1 import pandas as pd 2 import warnings 3 4 # 关闭警告显示 5 warnings.filterwarnings('ignore') 6 7 # 读取并查看【商品销售数据.xlsx】工作簿的数据 8 data = pd.read_excel('work/商品销售数据.xlsx') 9 data
整理后
1 # 数据清洗 2 # 清洗【用户 ID】列的缺失值 3 data = data.dropna(subset=['用户 ID']) 4 # 查找重复数据 5 data[data.duplicated()] 6 # 删除重复值 7 data = data.drop_duplicates() 8 # 筛选【数量】列大于 0 的数据 9 data = data[(data['数量'] > 0)] 10 11 # 数据整理 12 # 计算“总金额” 13 data['总金额'] = data['数量'] * data['价格'] 14 # 按【订单号】和【用户 ID】分组后,获取【发货日期】列的最大值和【总金额】列的总和 15 grouped_data = data.groupby(['订单号', '用户 ID'], as_index=False).agg({'发货日期': 'max', '总金额': 'sum'}) 16 # 计算时间间隔(天数) 17 today = '2012-01-01 00:00:00' 18 grouped_data['时间间隔'] = (pd.to_datetime(today) - pd.to_datetime(grouped_data['发货日期'])).dt.days 19 # 按【用户 ID】分组后,获取【时间间隔】列的最小值、【订单号】列的数量,以及【总金额】列的总和 20 rfm_data = grouped_data.groupby('用户 ID', as_index=False).agg({'时间间隔': 'min', '订单号': 'count', '总金额': 'sum'}) 21 # 修改列名为:用户 ID、时间间隔、总次数和总金额 22 rfm_data.columns = ['用户 ID', '时间间隔', '总次数', '总金额'] 23 rfm_data
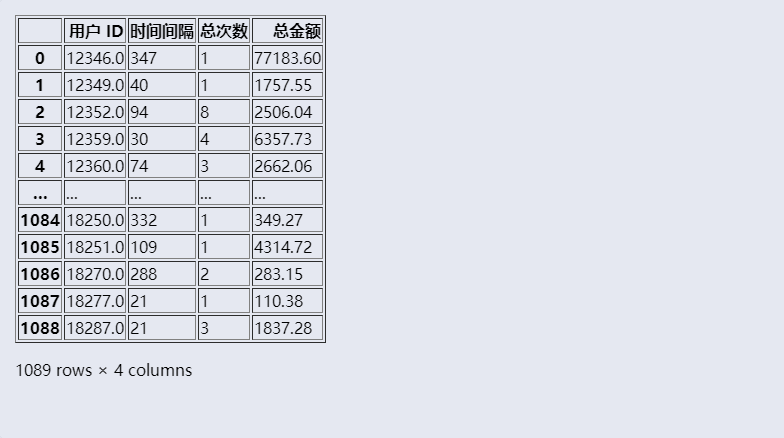
数据分析
1 # 定义函数按照区间划分 R 值 2 def caculate_r(s): 3 if s <= 100: 4 return 5 5 elif s <= 200: 6 return 4 7 elif s <= 300: 8 return 3 9 elif s <= 400: 10 return 2 11 else: 12 return 1 13 14 # 对 R 值进行评分 15 rfm_data['R评分'] = rfm_data['时间间隔'].agg(caculate_r) 16 17 # 定义函数按照区间划分 F 值 18 def caculate_f(s): 19 if s <= 5: 20 return 1 21 elif s <= 10: 22 return 2 23 elif s <= 15: 24 return 3 25 elif s <= 20: 26 return 4 27 else: 28 return 5 29 30 # 对 F 值进行评分 31 rfm_data['F评分'] = rfm_data['总次数'].agg(caculate_f) 32 33 # 定义函数按照区间划分 M 值 34 def caculate_m(s): 35 if s <= 2000: 36 return 1 37 elif s <= 4000: 38 return 2 39 elif s <= 6000: 40 return 3 41 elif s <= 8000: 42 return 4 43 else: 44 return 5 45 46 # 对 M 值进行评分 47 rfm_data['M评分'] = rfm_data['总金额'].agg(caculate_m) 48 49 # 计算 R评分、F评分、M评分的平均数 50 r_avg = rfm_data['R评分'].mean() 51 f_avg = rfm_data['F评分'].mean() 52 m_avg = rfm_data['M评分'].mean() 53 # 将R评分、F评分、M评分 的数据分别与对应的平均数做比较 54 rfm_data['R评分'] = (rfm_data['R评分'] > r_avg) * 1 55 rfm_data['F评分'] = (rfm_data['F评分'] > f_avg) * 1 56 rfm_data['M评分'] = (rfm_data['M评分'] > m_avg) * 1 57 rfm_data['R评分'] = rfm_data['R评分'].replace({1: '高', 0: '低'}) 58 rfm_data['F评分'] = rfm_data['F评分'].replace({1: '高', 0: '低'}) 59 rfm_data['M评分'] = rfm_data['M评分'].replace({1: '高', 0: '低'}) 60 61 # 拼接R评分、F评分、M评分 62 rfm_score = rfm_data['R评分'].astype(str) + rfm_data['F评分'].astype(str) + rfm_data['M评分'].astype(str) 63 rfm_score 64 65 # 定义字典标记 RFM 评分档对应的客户分类f名称 66 transform_label = { 67 '高高高':'重要价值用户', 68 '高低高':'重要发展用户', 69 '低高高':'重要保持用户', 70 '低低高':'重要挽留用户', 71 '高高低':'一般价值用户', 72 '高低低':'一般发展用户', 73 '低高低':'一般保持用户', 74 '低低低':'一般挽留用户' 75 } 76 # 将 RFM 评分替换成具体的客户类型 77 rfm_data['客户类型'] = rfm_score.replace(transform_label) 78 rfm_data
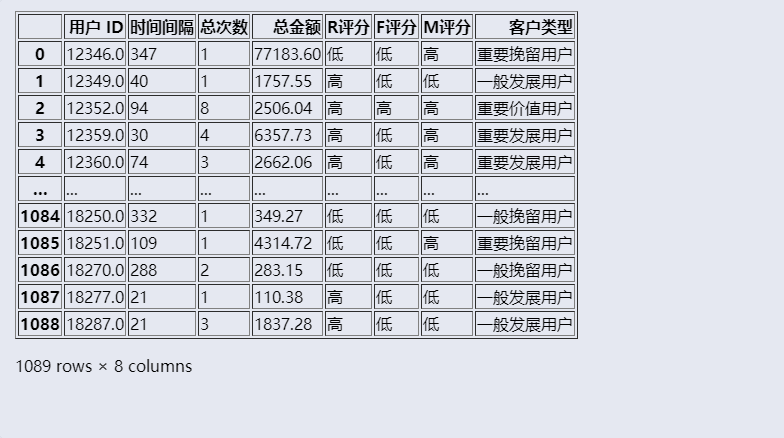
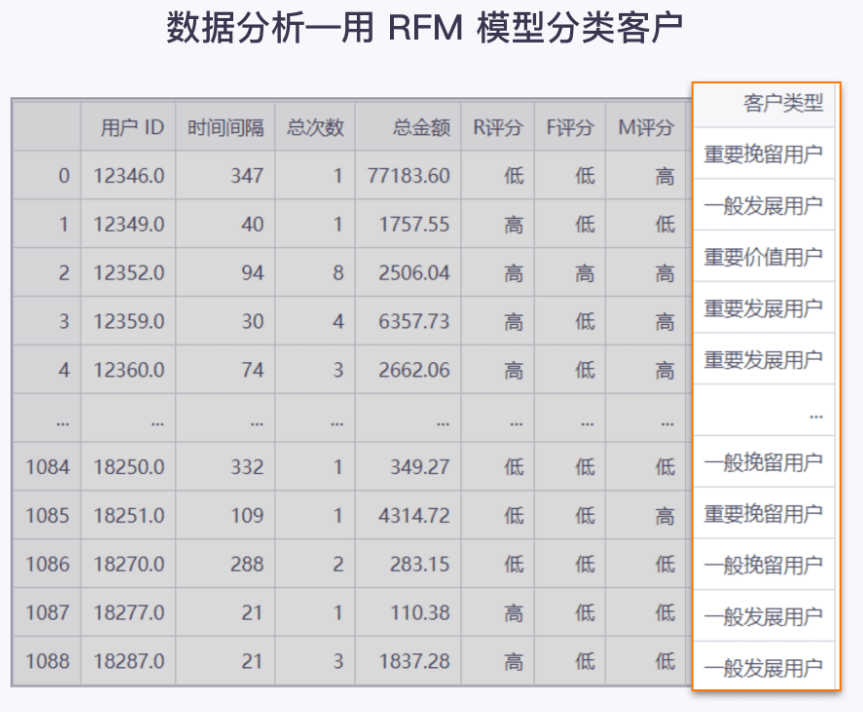
释义
数据展示
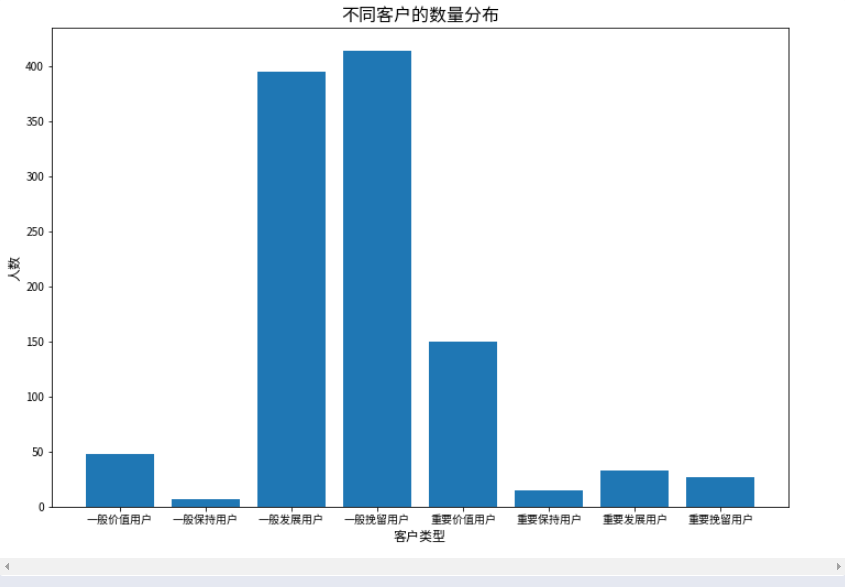
将各类客户的数量绘制成柱状图
1 import matplotlib.pyplot as plt 2 3 # 按【客户类型】分组,统计客户的数量 4 customer_data = rfm_data.groupby('客户类型')['用户 ID'].count() 5 customer_data 6 7 # 设置中文字体 8 plt.rcParams['font.family'] = ['Source Han Sans CN'] 9 10 # 绘制柱状图 11 plt.figure(figsize=(12, 8)) 12 plt.bar(customer_data.index, customer_data) 13 plt.xlabel('客户类型', fontsize=12) 14 plt.ylabel('人数', fontsize=12) 15 plt.title('不同客户的数量分布', fontsize=16) 16 plt.show()
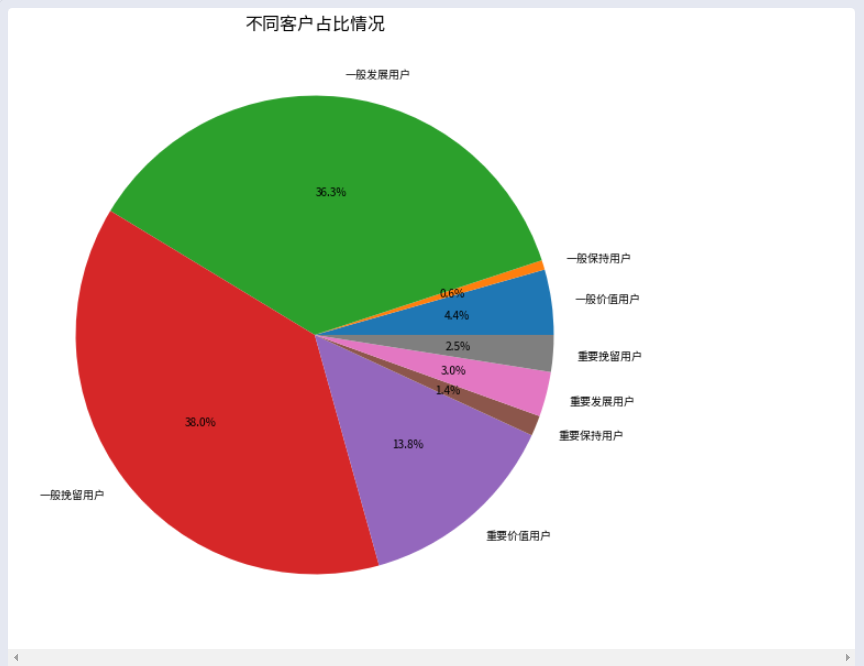
将各类客户的数量绘制成饼图。
1 # 绘制饼图 2 plt.figure(figsize=(14, 10)) 3 plt.pie(customer_data, labels=customer_data.index, autopct='%0.1f%%') 4 plt.title('不同客户占比情况', fontsize=16) 5 plt.show()
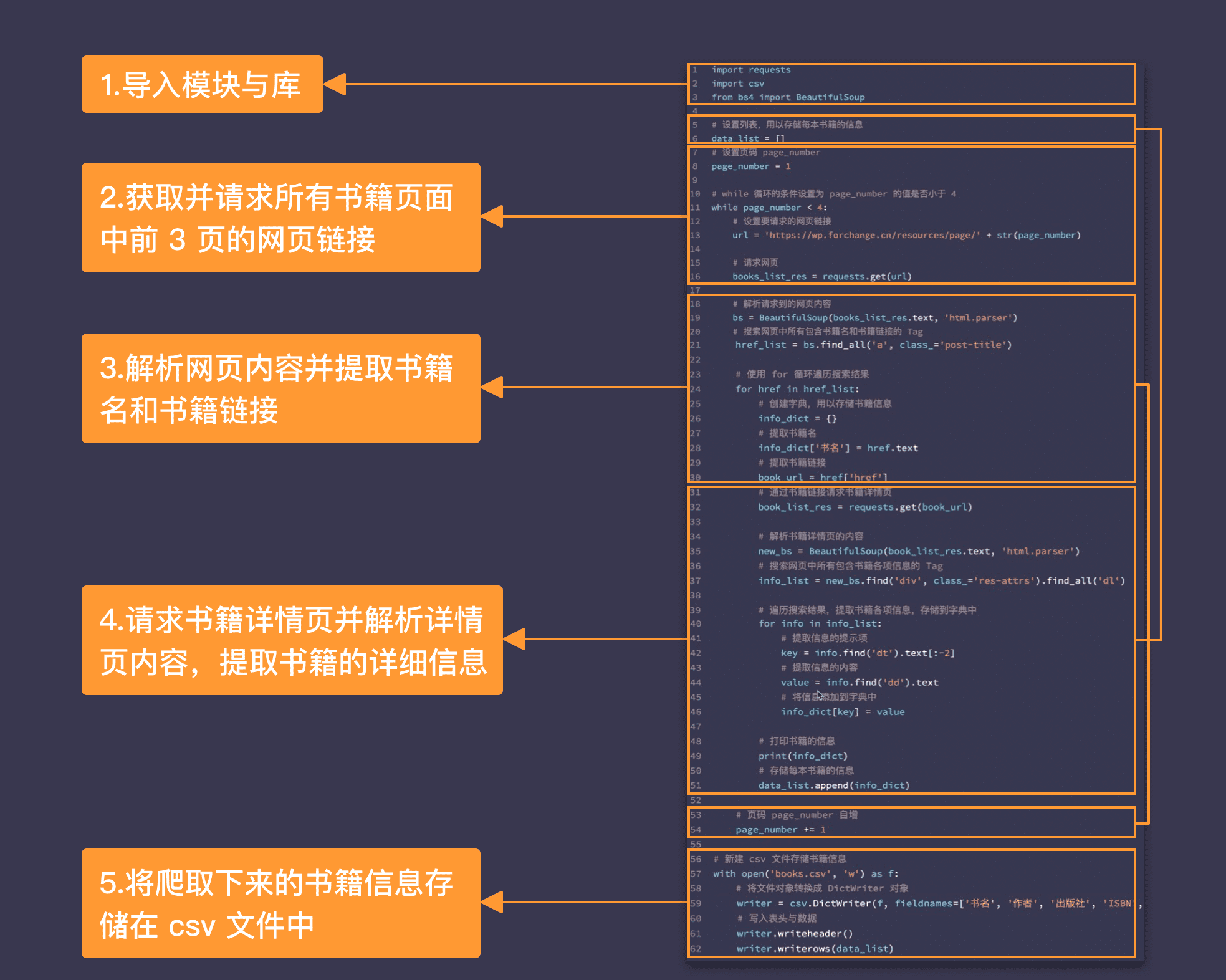
爬虫的步骤
【发起网络请求】 -> 【获取网页内容】 -> 【提取网页信息】 -> 【打印提取的信息】

案例
1 #爬取凤凰网财经新闻标题案例 2 # 导入模块与库 3 import re 4 import requests 5 6 # 发起网络请求 7 res = requests.get("https://finance.ifeng.com/gold/") 8 # 获取网页内容 9 news = res.text 10 # 提取网页信息 11 title = re.findall('docName=(.*?)&',news) 12 # 打印新闻标题 13 print(title)
案例
#书籍信息批量爬取案例 import csv import requests from bs4 import BeautifulSoup # 设置列表,用以存储每本书籍的信息 data_list = [] # 设置页码 page_number page_number = 1 # while 循环的条件设置为 page_number 的值是否小于 4 while page_number < 4: # 设置要请求的网页链接 url = 'https://wp.forchange.cn/resources/page/' + str(page_number) # 请求网页 books_list_res = requests.get(url) # 解析请求到的网页内容 bs = BeautifulSoup(books_list_res.text, 'html.parser') # 搜索网页中所有包含书籍名和书籍链接的 Tag href_list = bs.find_all('a', class_='post-title') # 使用 for 循环遍历搜索结果 for href in href_list: # 创建字典,用以存储书籍信息 info_dict = {} # 提取书籍名 info_dict['书名'] = href.text # 提取书籍链接 book_url = href['href'] # 通过书籍链接请求书籍详情页 book_list_res = requests.get(book_url) # 解析书籍详情页的内容 new_bs = BeautifulSoup(book_list_res.text, 'html.parser') # 搜索网页中所有包含书籍各项信息的 Tag info_list = new_bs.find('div', class_='res-attrs').find_all('dl') # 遍历搜索结果,提取书籍各项信息,存储到字典中 for info in info_list: # 提取信息的提示项 key = info.find('dt').text[:-2] # 提取信息的内容 value = info.find('dd').text # 将信息添加到字典中 info_dict[key] = value # 打印书籍的信息 print(info_dict) # 存储每本书籍的信息 data_list.append(info_dict) # 页码 page_number 自增 page_number += 1 # 新建 csv 文件存储书籍信息 with open('books.csv', 'w') as f: # 将文件对象转换成 DictWriter 对象 writer = csv.DictWriter(f, fieldnames=['书名', '作者', '出版社', 'ISBN', '页数', '出版年', '定价']) # 写入表头与数据 writer.writeheader() writer.writerows(data_list)
快捷方式
多行注释
多行注释有两种快捷操作:1、在需要注释的多行代码块前后加一组三引号''' 2、选中代码后使用快捷键操作:Windows快捷键是ctrl+/,Mac为cmd+/,适用于本地编辑器)
其他补充知识点
try…except…语句 (为了不让一些无关痛痒的小错影响程序的后续执行,Python给我们提供了一种异常处理的机制,可以在异常出现时即时捕获,然后内部消化掉,让程序继续运行。)

示例:(除法计算器)
1 print('\n欢迎使用除法计算器!\n') 2 3 while True: 4 try: 5 x = input('请你输入被除数:') 6 y = input('请你输入除数:') 7 z = float(x)/float(y) 8 print(x,'/',y,'=',z) 9 break # 默认每次只计算一次,所以在这里写了 break。 10 except ZeroDivisionError: # 当除数为0时,跳出提示,重新输入。 11 print('0是不能做除数的!') 12 except ValueError: # 当除数或被除数中有一个无法转换成浮点数时,跳出提示,重新输入。 13 print('除数和被除数都应该是整值或浮点数!') 14 15 # 方式2:将两个(或多个)异常放在一起,只要触发其中一个,就执行所包含的代码。 16 # except(ZeroDivisionError,ValueError): 17 # print('你的输入有误,请重新输入!') 18 19 # 方式3:常规错误的基类,假设不想提供很精细的提示,可以用这个语句响应常规错误。 20 # except Exception: 21 # print('你的输入有误,请重新输入!')
成功之路
-----------------------------------------------------------------------------------------------------------------以上内容均摘自网上数据,仅供个人学习使用,非商用,如有侵权,请联系删除处理。
我们可以把每个独立的功能封装到每个单独的函数中,然后用一个主函数打包这些单独的函数,最后再调用主函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号