马拉车算法,其实并不难!!!
要说马拉车算法,必须说说这道题,查找最长回文子串,马拉车算法是其中一种解法,狠人话不多,直接往下看:
题目描述
给你一个字符串 s,找到 s 中最长的回文子串。
例子
示例 1:
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。
示例 2:
输入:s = "cbbd"
输出:"bb"
示例 3:
输入:s = "a"
输出:"a"
示例 4:
输入:s = "ac"
输出:"a"
马拉车算法
这是一个奇妙的算法,是1957年一个叫Manacher的人发明的,所以叫Manacher‘s Algorithm,主要是用来查找一个字符串的最长回文子串,这个算法最大的贡献是将时间复杂度提升到线性,前面我们说的动态规划的时间复杂度为 O(n2)。
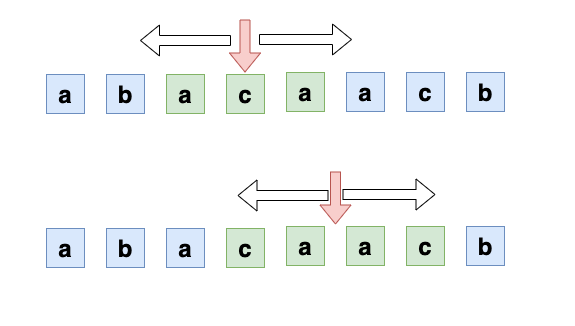
前面说的中心拓展法,中心可能是字符也可能是字符的间隙,这样如果有 n 个字符,就有 n+n+1 个中心:
为了解决上面说的中心可能是间隙的问题,我们往每个字符间隙插入”#“,为了让拓展结束边界更加清晰,左边的边界插入”^“,右边的边界插入 "$":

S 表示插入"#","^","$"等符号之后的字符串,我们用一个数组P表示S中每一个字符能够往两边拓展的长度:
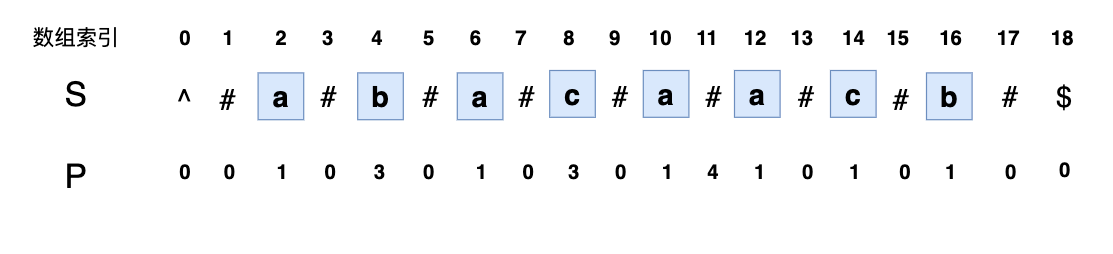
比如 P[8] = 3,表示可以往两边分别拓展3个字符,也就是回文串的长度为 3,去掉 # 之后的字符串为aca:

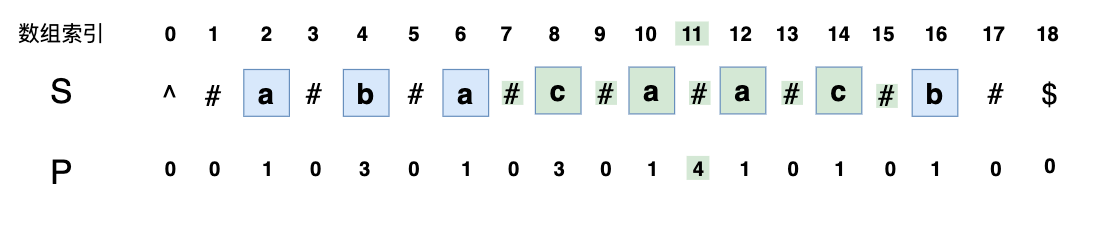
P[11]= 4,表示可以往两边分别拓展4个字符,也就是回文串的长度为 4,去掉 # 之后的字符串为caac:
假设我们已经得知数组P,那么我们怎么得到回文串?
用 P 的下标 index ,减去 P[i](也就是回文串的长度),可以得到回文串开头字符在拓展后的字符串 S 中的下标,除以2,就可以得到在原字符串中的下标了。
那么现在的问题是:如何求解数组P[i]
其实,马拉车算法的关键是:它充分利用了回文串的对称性,用已有的结果来帮助计算后续的结果。
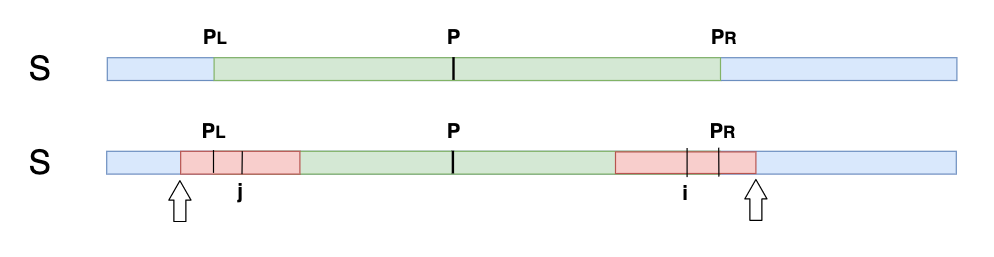
假设已经计算出字符索引位置 P 的最大回文串,左边界是PL,右边界是PR:

那么当我们求因为一个位置 i 的时候,i 小于等于 PR,其实我们可以找到 i 关于 P 的对称点 j:

那么假设 j 为中心的最长回文串长度为 len,并且在 PL 到 P 的范围内,则 i 为中心的最长回文串也是如此:
以 i 为中心的最长回文子串长度等于以 j 为中心的最长回文子串的长度

但是这里有两个问题:
- 前一个回文字符串P,是哪一个?
- 有哪些特殊情况?特殊情况怎么处理?
(1) 前一个回文字符串 P,是指的前面计算出来的右边界最靠右的回文串,因为这样它最可能覆盖我们现在要计算的 i 为中心的索引,可以尽量重用之前的结果的对称性。
也正因为如此,我们在计算的时候,需要不断保存更新 P 的中心和右边界,用于每一次计算。
(2) 特殊情况其实就是当前 i 的最长回文字符串计算不能再利用 P 点的对称,例如:
- 以
i的回文串的右边界超出了P的右边界 PR:
这种情况的解决方案是:超过的部分,需要按照中心拓展法来一一拓展。
i不在 以P为中心的回文串里面,只能按照中心拓展法来处理。

具体的代码实现如下:
// 构造字符串
public String preProcess(String s) {
int n = s.length();
if (n == 0) {
return "^$";
}
String ret = "^";
for (int i = 0; i < n; i++)
ret = ret + "#" + s.charAt(i);
ret = ret + "#$";
return ret;
}
// 马拉车算法
public String longestPalindrome(String str) {
String S = preProcess(str);
int n = S.length();
// 保存回文串的长度
int[] P = new int[n];
// 保存边界最右的回文中心以及右边界
int center = 0, right = 0;
// 从第 1 个字符开始
for (int i = 1; i < n - 1; i++) {
// 找出i关于前面中心的对称
int mirror = 2 * center - i;
if (right > i) {
// i 在右边界的范围内,看看i的对称点的回文串长度,以及i到右边界的长度,取两个较小的那个
// 不能溢出之前的边界,否则就得中心拓展
P[i] = Math.min(right - i, P[mirror]);
} else {
// 超过范围了,中心拓展
P[i] = 0;
}
// 中心拓展
while (S.charAt(i + 1 + P[i]) == S.charAt(i - 1 - P[i])) {
P[i]++;
}
// 看看新的索引是不是比之前保存的最右边界的回文串还要靠右
if (i + P[i] > right) {
// 更新中心
center = i;
// 更新右边界
right = i + P[i];
}
}
// 通过回文长度数组找出最长的回文串
int maxLen = 0;
int centerIndex = 0;
for (int i = 1; i < n - 1; i++) {
if (P[i] > maxLen) {
maxLen = P[i];
centerIndex = i;
}
}
int start = (centerIndex - maxLen) / 2;
return str.substring(start, start + maxLen);
}
至于算法的复杂度,空间复杂度借助了大小为n的数组,为O(n),而时间复杂度,看似是用了两层循环,实则不是 O(n2),而是 O(n),因为绝大多数索引位置会直接利用前面的结果以及对称性获得结果,常数次就可以得到结果,而那些需要中心拓展的,是因为超出前面结果覆盖的范围,才需要拓展,拓展所得的结果,有利于下一个索引位置的计算,因此拓展实际上较少。
【作者简介】:
秦怀,公众号【秦怀杂货店】作者,技术之路不在一时,山高水长,纵使缓慢,驰而不息。个人写作方向:Java源码解析,JDBC,Mybatis,Spring,redis,分布式,剑指Offer,LeetCode等,认真写好每一篇文章,不喜欢标题党,不喜欢花里胡哨,大多写系列文章,不能保证我写的都完全正确,但是我保证所写的均经过实践或者查找资料。遗漏或者错误之处,还望指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号