云时代架构阅读笔记十一——分布式架构中数据一致性常见的几个问题
原文链接:https://mp.weixin.qq.com/s?__biz=MzAwNTQ4MTQ4NQ==&mid=2453562561&idx=1&sn=091231f92a0f555a2ea007d66e20aab9&chksm=8cd131a3bba6b8b54227969d774508fdb97f71a5494e4993e54ed99da1b14cb1d721c87dce3e&scene=27&ascene=0&devicetype=android-28&version=2700043c&nettype=cmnet&abtest_cookie=BQABAAoACwASABMAFQAGACOXHgBWmR4Ay5keANyZHgD5mR4AC5oeAAAA&lang=zh_CN&pass_ticket=KADs%2Bb6XXZVFsw67HoLMXVbukuRbgjhDozp7ORtOl0nVsGV%2FMmHkN1fAhHMC6rpm&wx_header=1
本文着重处理以下几个问题:跨系统间分布式事务如何解决?系统内多个服务的分布式事务如何解决?一个服务内多个数据源/数据库的分布式事务如何解决?等
首先上一幅图;
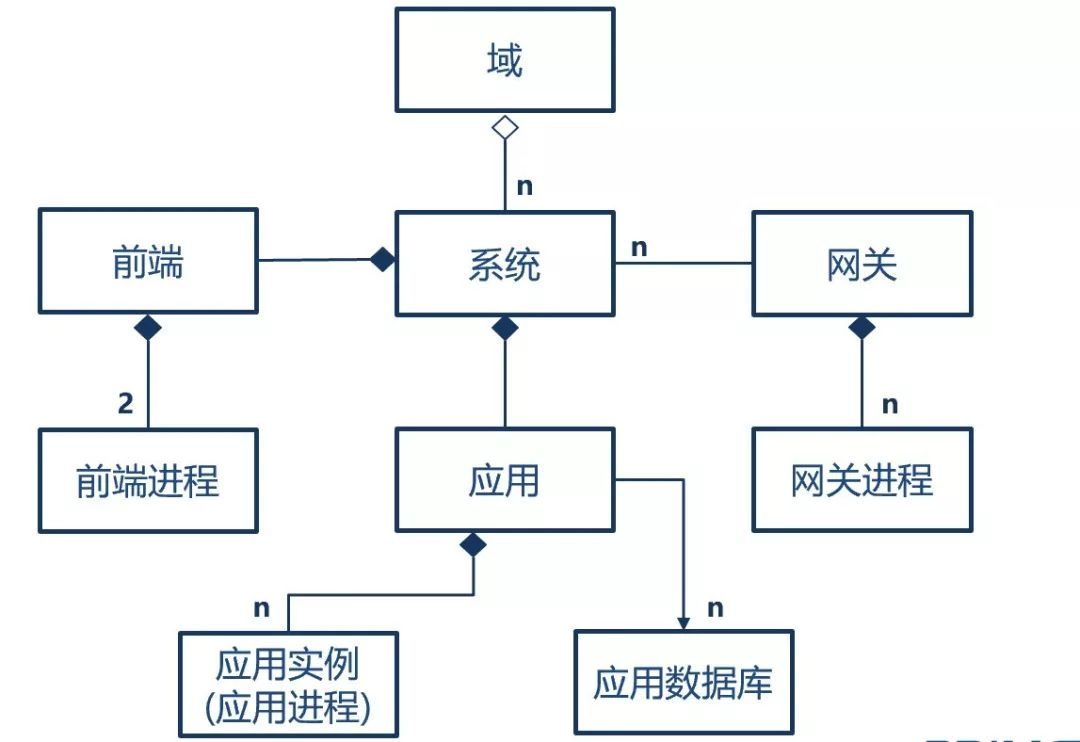
域是一个虚拟的分类,几个系统属于某一个域,例如网上银行和手机银行都属于电子渠道领域;
传统的单体应用,指的就是系统,在微服务架构下,单体应用采用前后端分离模式,前端一般使用 Nginx,Ngnix 进程间采用主备模式,系统的后端可以分为多个应用,每个应用有一组对等的应用进程(也称为应用实例)提供服务,每个应用对应一个数据库,实际上在分库的情况下,有可能一个应用对应多个数据库。复杂一点的是网关,网关由一组对等的网关实例组成,如果多个系统共享一个网关,网关和系统就是1对多的关系,也可以一个系统独享一个网关,就是一对一情况,下图是一个概念的示例,使用的是系统独享网关模式。
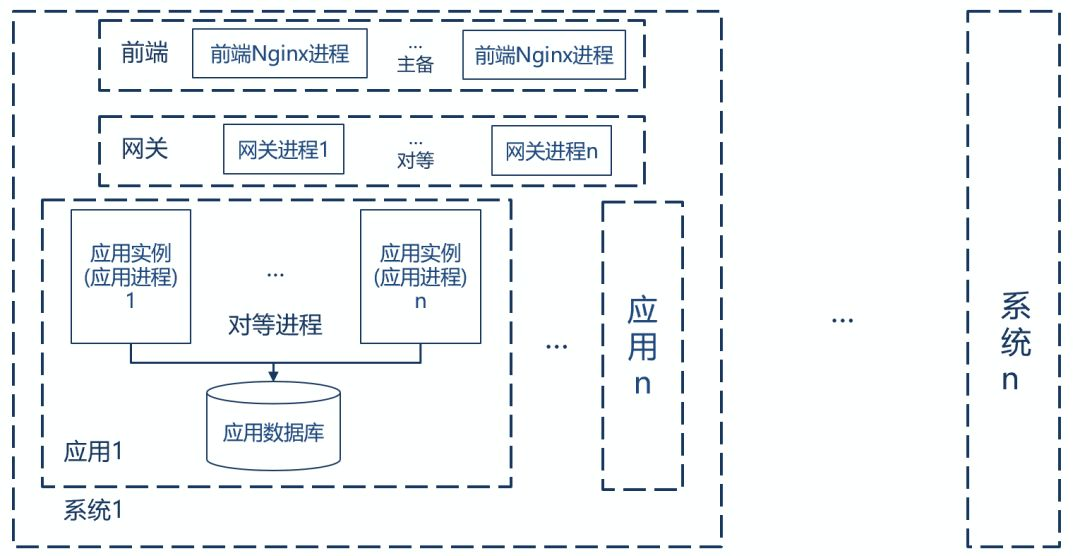
有以下四种情况:
1、系统间的数据一致性
需要服务实现 TCC或者业务补偿模式,由框架(业务协调器)自动调用,减少人工参与,或者实现幂等服务,反复投递。这两种方式都没法做到数据的 100% 一致,在失败的时候都需要有重试的机制,例如补偿失败要重试(这就是框架的好处),多次重试还是失败,记录失败历史,业务上人工处理。不要害怕人工处理,只要减少人工处理的机会就好了,在工行时就是提出人工干预比例降低若干个百分点作为目标。
2、系统内应用间的数据一致性
这个可以使用华为 SAGA 的模式,也就是建立一个共享的事务协调器模式(虽然我对这个共享方式不喜欢,不是分布式吗,为啥还搞出一堆集中式的东西,既然如此,为啥应用间调用不能走网关,要直连,说共享不好,到这里就是共享好了),好了,括号里是吐槽,简单的方式是用共享的事务协调器模式,记录服务调用的事件,在合适的时机调用TCC和补偿服务。
3、应用内部对应多数据库的数据一致性,是个反模式,不要做通用方案
一般来说,一个应用对应一个数据库,不允许一个应用对应多个数据库,多个数据库的情况应该分成多个应用,通过服务调用方式解决,这是一个基本原则,否则就是一个反模式设计。但是,就是有很多人较真,一定问有这个情况你怎么解决,我的回答是架构设计解决这个问题,在技术上不支持这种方式,让设计者必须在架构解决,而不是利用技术手段解决不合理的架构设计,否则后患无穷(这一点还是需要勇气和坚持的)。空口无凭,实例为证,一般我会举抢红包的例子。大家知道,抢红包的并发非常高,又有数据一致性的要求,无论哪个互联网公司,都是根据红包 ID,把数据路由到一个数据库中,用数据库事务保证数据一致性,在银行互联网账务系统(2类 3类户)的情况,也是把同一账务的数据路由到不同的数据库中(见下图)。还会提到一种情况,在分库分表的时候,如果恰好数据分到了不同库中,恰好要做一个批量的调整,恰好在一个事务中,如何解决。我认为这种情况的发生,恰恰说明设计有问题,分库的原则也是按业务拆分,不是用技术手段随机分解,既然按业务拆分,批量处理的时候就应该不是一个业务上的事务,在技术上不提供这样的实现,才可以在架构设计考虑问题。不排除在某个系统中可以做一些框架,解决上述问题,但是,这一定不是个通用的方案。
4、一个数据库对应多个应用的数据一致性
这种情况经常也是一个反模式,既然是共享一个数据库,把应用放在一起就好了。如果真的有需要(例如一个模块部署过于频繁,单独拆出来做一个应用),那也应该和多应用多数据库一样处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号