浅谈网络流
你相信哲学吗?
Do you believe in philosophy?

简而言之,网络流的是:

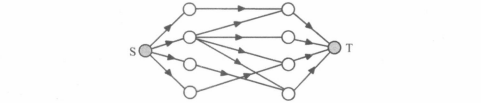
Ford–Fulkerson 增广
最大流的算法很多,低级的包括Edmonds–Karp 算法(简称EK)和Dinic 算法,高级的有涉及到预流推进,像MPM 算法和ISAP等。对于EK和Dinic,我们称这类算法为Ford–Fulkerson 增广。他们都有一个共同的原理,那就是贪心。

EK的做法,就是不断去寻找一条从S前往T的道路,并将其榨干。很显然,找到这么一条路,第一次就被榨干了,后面无论多少次再试都不行了。但这只是限于这条路上容量限制最小的边,其他的都有剩余容量。我们每次找到一条增广路,就把每条边的容量限制改变为其剩余容量。这样得到的网络,我们称其为残量网络。
然而,你可能会想到,如此盲目的去找,如此自信地贪心,正确性何在?就像匈牙利算法匹配二分图一样,匹配点是不会再变回非匹配点的,但人家匈牙利的匹配边是可以取反的,EK的“后路”是什么?第一次找的就一定是对的啦?
还记得“斜对称”这条性质吗?
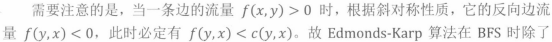

在我们将$c(x,y)$减小的同时,也应当将$c(y,x)$增大。这似乎是一种守恒定律,需要哲学理解
所以从某种意义上,这条边真正的容量限制是不会改变的,改变的只是正反方向的流量。形象化的理解,就像一个瓶子,里面装了一半的水。只有一半的水吗?不,是一半的水和一半的空气。对于空气而言,空瓶子就是装满水的瓶子;对于水而言,空瓶子就是装满空气的瓶子。因此空或满都是相对的。瓶子的总容量是不会改变的,改变的只是空气与水的比例。这个视频形象的展示了网络流的流动,非常建议观看。
至于为什么要维护正反方向的流量,那么我可以告诉您,这一操作是维护了某种终极秩序,但其作用远大于此。诸君或许认为这种哲学离实际太远了,维不维护无所谓,那么网络流今天就可以让大家大开眼界了。
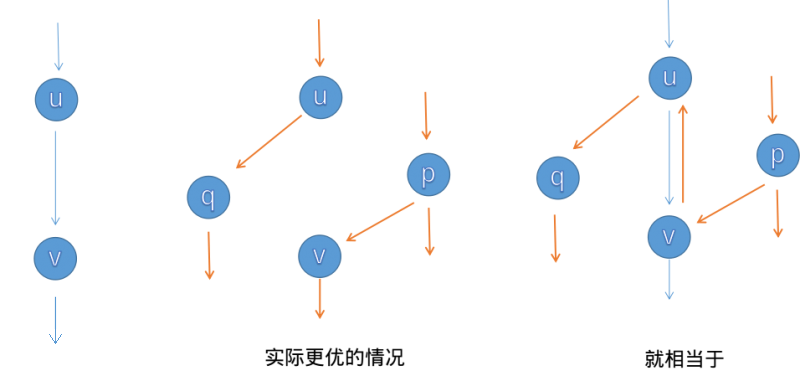
请看,我们的EK一开始误入歧途,找到了一条错误的路径(左图)。但是,因为我们在对增广路上的所有边进行容量变换操作的时候再其反向边上也有相应的操作,那么在之后从p遍历到v这里时,就会发现$(u,v)$的反向边$(v,u)$是一条妥妥的增广路,容量还大着呢!于是走了过去,又对这条边进行了一次容量的变换,就与之前的抵消啦!这一操作,我们称之为退流。他就对应着匈牙利算法中的取反,相当于是一种反悔的操作,也是EK以及所有Ford–Fulkerson 增广算法为自己留下的后路,是保证贪心正确性的重要法宝,反悔的必由之路,Edmonds–Karp与Dinic致胜的关键一招。
所以说,网络流是玄学,诸君是否已有初步感受?
Dinic 算法
对于EK,我们总结一下就是:不断bfs寻找增广路,直到再也找不到一条增广路。复杂度约为$O(nm^2)$,一般能够处理$10^3$~$10^4$规模的网络。
但他有一个缺点,就是一次BFS只找一条增广路,跑遍全图找一条未免有点太不划算。就像埃氏筛和线性筛一样,虽然没有足够的依据证明线性筛比埃氏筛使用更为广泛,或许线性筛也有很多缺陷,但我们还是跳过埃氏筛,直接来到线性筛。这次也是一样,我们重点关注Dinic算法。
Dinic的特点是多路增广,也就是说,一次BFS可以找出多条增广路。
如何去实现呢?我们不妨先设想,如果没有方向满图乱跑,会遇到的最大的问题是什么?既然是寻找从S到T的路径,那么最坏的情况就是像迷宫一样,不知道哪边是哪边,往前走了往回走,走过多少弯弯绕绕,简单的问题都变得复杂了。为此,我们使用了BFS来寻找一条从S到T的最短路径。至于为什么要从短的下手,其实也并不是一个硬性的规定。只是说像饭店先做简单的菜一样,我们习惯性地把问题从简单到复杂这样一层层解决。(当然,这只是我个人的看法)也有可能是像置换反应的先后顺序那种原理,活动性相差远的一定先反应,因为如果先和近的反应那么形成的产物又会反应,就是一个悖论了。BFS也是一样,想要有层次地找增广路,那最先找到的也必然是最短的了。
EK在执行这个过程的时候固然也会有用到BFS,但他就浪费了许多已经求出的资源。Dinic就节约上了,与EK同样的BFS,但那一条增广路找出后,也没有浪费掉同时找出的其他节点的信息。Dinic会在BFS的同时建立分层图。注意,这个分层图并不是分层图最短路的那种,他并不需要连边,只需要用一个depth数组记录遍历过的每一个点的深度即可,想必诸君在做LCA树上倍增或者树形DP的时候都是体会过的。但这个分层图,他不是一棵树,而是一个有向无环图。当然,这个不必多虑,性质差不多,都是可以用层来表示的。
在残量网络中,满足$d[y]=d[x]+1$的子图被称为分层图。
具体做法如下:

对于这个意义模糊的分层图,我认为有必要澄清一下两点:
- 每次BFS所建立的分层图是相对于此次BFS的,不一定包含所有的节点且每次不同,故不能将原图与独立于原图的分层图(也就是由原图的子图组成的)混为一谈。这种BFS相当于是EK的一个extension,因而我们不会去在每一次BFS时都遍历所有的节点。同时,这样也会增加复杂度,得不偿失。
- 分层图真正的含义应当是将图上的节点分为了不同的层次,而分层标准有时是$d[y]=d[x]+1$,也有很多时候不是。比如下面会讲的费用流,就是按照最短路径对其进行分层的。也就是说,$d[y]=d[x]+1$只是一个索引。请读者明辨,切莫拘泥于这种传统的分层标准。
那么话不多说,就让我们通过代码来详细理解吧~
int head[N],ver[M],edge[M],nex[M],tot=1;
void add(int x,int y,int z){
ver[++tot]=y,edge[tot]=z,nex[tot]=head[x],head[x]=tot;
ver[++tot]=x,edge[tot]=0,nex[tot]=head[y],head[y]=tot;
}由于我们需要快速地获取反向边的信息,此次我终于放弃了vector存图,学习了邻接表。邻接表的方便之处在于他可以保存插入的边的信息,如下标(是的,他是按边来存储图的。tot也是边的指针。因此,所有有关边的信息,ver、edge和nex,都可以封到一个struct里面哦)。head就是表头,而head的下标就是我们的出发点,通过表头来不断获取nex实现遍历。这里确实和vector挺不一样,一开始理解起来有点抽象蛤。
add函数如上,我们为了快捷的获取反向边,利用了XOR成对变换的性质。只需要下标从2开始(初始化tot=1)那么我们只需要通过“^”操作,就可以得到他旁边的下标了,2&3,4&5..... 因此,我们把反向边存储到旁边,就可以实现快速访问了。反向边初始容量为0。您可能会问,流图不是有向图吗,怎么还搞无向图的操作?其实,两边存就是对待单条边的操作。如果有重边,就在后面多存就行了。也就是说一条边当成是两条的存,因此边要开两倍空间。
int dep[N];
queue<int>q;
bool bfs(){
rep(i,1,n)dep[i]=0; //每次BFS时都需要初始化depth,因为分层图都是相对于该次BFS独立的
while(q.size())q.pop();
q.push(s);
dep[s]=1;
while(q.size()){
int x=q.front();q.pop();
for(int i=head[x];i;i=nex[i]){
if(edge[i]&&!dep[ver[i]]){ //如果该边已经没有容量了,我们就不再关心,所以需要判断edge[i]
q.push(ver[i]);
dep[ver[i]]=dep[x]+1;
if(ver[i]==t)return 1; //如上文所述,一旦找到了汇点T,就不再找了
}
}
}
return 0;
}这,便是我们熟悉的BFS。这里不多解释,都放在注释里了。
int dinic(int x,int flow){
if(x==t)return flow; //已经找到汇点,回溯
int rest=flow,k;
for(int i=head[x];i&&rest;i=nex[i]){ //实际上我们依然按照原图来遍历
if(edge[i]&&dep[ver[i]]==dep[x]+1){ //depth就是用于判断该点是否位于分层图上的,一个索引
k=dinic(ver[i],min(rest,edge[i])); //递归下去,flow要传最小的容量才能合法压榨
if(!k)dep[ver[i]]=0; //如果这条路已经确认被榨干了,那就砍掉吧,通过depth剪枝
edge[i]-=k;
edge[i^1]+=k; //流量操作,本边减反边加
rest-=k; //流经该点的剩余流量减少
}
}
return flow-rest; //原流量-剩下的=新榨的
}dinic函数,也被称为dfs函数,是在bfs所建立的分层图上进行的搜索,找到不同的增广路,并对其边进行流量操作,最后将流量汇入主流,也就是从源头S出发的这些流,并return回去表示此次在分层图上可以榨出的流量。您可以想象一个用甘蔗做成的有向无环图,我们从源头开始遍历,先压榨,然后把汁水往回汇。
int flow=0;
while(bfs()){ //bfs寻找,看残量网络中是否还有可以到达T的路径(增广路)
while(flow=dinic(s,INF))maxflow+=flow; //还有路,dfs快去榨他,一直榨到没有
}
cout<<maxflow<<endl;以上是main函数中的调用。AC记录
当前弧优化
蓝书上本没有这一块的内容,新版增设了,估计是考虑到dinic不优化会被卡的很惨。这大概也是一个非常重要的方法,越早说越好。

初读极涩。实际上,这种情况,我也会不了一点。也有大佬告诉我如何如何,但我没有听明白,所以不能乱写。让我们等待一个久违的机会吧。
最小割

最大流=最小割。
证明也十分简单。因为最大流已经保证了残量网络中不存在增广路,那么将其删去之后,图中没有增广路,S和T自然就散架了。
因此,可以求最大流,便可以求最小割。而专门给最小割起这个名字,是因为他在一些问题中有广泛的应用。
费用流

实际上,费用流与最大流几乎是相同的,最大的区别就是把BFS换成了SPFA。还记得我对分层图的说明吗?当我们BFS时,路径最短的自然会被优先,而最大流似乎没有对路径长短有要求,可行的方案也有多种。现在,每一条便都给定了一个额外的权值,既要满足流量最大,同时也要保证花费最大或最小。那么,BFS顺序的先后就可以派上用场了:使用SPFA,以权值为路径长度,保证花费最小的先被收入囊中,自然也可以依照这个顺序证得答案的正确性了。
至于实现,EK和dinic均可,都和最大流一样。但一定要注意的是优化,会被卡到三更半夜的。
int head[N],ver[M],edge[M],nex[M],tot=1,cost[M],now[N]; //now即为当前弧优化
void add(int x,int y,int z,int p){
ver[++tot]=y,edge[tot]=z,nex[tot]=head[x],head[x]=tot,cost[tot]=p;
ver[++tot]=x,edge[tot]=0,nex[tot]=head[y],head[y]=tot,cost[tot]=-p; //反向边记得插入-cost
}存图如上,此题需要使用当前弧优化。
queue<int>q;
int dist[N];
bool vis[N];
bool spfa(){
rep(i,1,n)dist[i]=INF,vis[i]=0,now[i]=head[i];
q.push(s); //now必须每次都要初始化,因为每次都不一样,会改变
dist[s]=0,vis[s]=1;
while(q.size()){
int x=q.front();
q.pop(),vis[x]=0; //spfa要谨慎处理vis,容易TLE
for(int i=head[x];i;i=nex[i]){
int y=ver[i];
if(edge[i]&&dist[y]>dist[x]+cost[i]){
dist[y]=dist[x]+cost[i];
now[y]=head[y]; //now的更新,但似乎这里不需要也可以?
if(!vis[y])q.push(y),vis[y]=1;
}
}
} //如果T可以到达,就返回1;否则0
return dist[t]!=INF;
}这一段代码非常容易做法假掉,一定要谨慎。如果now不初始化,则会酿成大祸。
int maxflow,mincost;
int dinic(int x,int flow){
if(x==t)return flow;
vis[x]=1; //记住这里的vis也要处理好,否则容易死循环
int rest=flow,k; //这里调用的不再是head,而是now
for(int i=now[x];i&&rest;i=nex[i]){
now[x]=i; //当前弧优化,同步维护第一条还有必要尝试的边
if(!vis[ver[i]]&&edge[i]&&dist[ver[i]]==dist[x]+cost[i]){
k=dinic(ver[i],min(rest,edge[i]));
if(!k)dist[ver[i]]=INF;
mincost+=k*cost[i]; //计算费用
edge[i]-=k;
edge[i^1]+=k;
rest-=k;
}
}
vis[x]=0;
return flow-rest;
}从侧面来讲,如果now没有每次都清零,那么最终会导致死循环。因为spfa是按head访问的,也就是最原始的图,但是dfs是按now访问的,now应当是基于bfs或者spfa之后这个有向无环图的,只对两次spfa之间的dinic适用。如果说不重置,那上一盘的残留信息就会慢慢把所有的边堵满,dfs就无法找到增广路,但实际上是有增广路的,(每个点的)第一遍后就永远不会走了。spfa一直毫无问题地运作,但是dfs有功能障碍,更准确的说,dfs错误的以为无法更新了,SPFA正确的认为还可以更新所以继续运行dfs然后卡死了,这就是根本原因。就像我今晚去B栈上看的一个视频,心肌细胞对氧气的需要是持续不断的,但是由于各种三高食物在冠状动脉中淤积而不清除,就会导致堵塞最后堵死,可能是同一个道理。
这种方法(SPFA+Edmonds–Karp或Dinic)仅仅适用于没有负环的情况。如果有负环,就还需要请到Primal-Dual 原始对偶算法这样的高级神仙。
未知之境-有源汇上下界最大流
网络流,是图论中最博大精深的一个分支。通过有源汇上下界最大流,我们可以深切地体会到玄学的魅力。

要解决这个问题,我们还需要解决无源汇上下界可行流、有源汇上下界可行流。我们需要连边,建立超级源点、汇点等一系列复杂的工序,故几于玄。留下悬念,待到日后故地重游之时,愿能重遨网络流之海洋,收知识之硕果。
今天总算领略到了大名鼎鼎的玄学,不虚此行。网络流的题解,个人建议到OI wiki上看,不要去其他地方,往往有许多bug和谣言。
END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号