
BigTable——针对结构型数据的一种分布式存储系统
摘要
结构型数据,用超大尺寸设计的,以PB级的数据量穿梭在成千上万的商业服务器上面。BigTable正是针对于管理这种结构型数据而设计的。Google的许多大型项目都用到了这种BigTable,包括Web indexing(网络索引),Google earth(谷歌地球),Google finance(谷歌财经),着眼于从网页链接到卫星图像这样的数据尺寸和从后台数据的批量处理到实时数据服务,这些应用都在BigTable上有着不同的需求。尽管谷歌的这些产品在需求上有着极大的不同,但是BigTable还是能够成功地提供灵活,高效的解决方案来处理这些需求。这篇论文我们主要是来简单介绍BigTable上面的简单数据模型,这篇论文还给出了数据层和规格层上面的客户端动态控制,同时这里也描述了BigTable的设计和实施。
1.介绍
在过去的两年半的时间里,我们设计,实施和部署了一个分布式系统,主要的目的是为了有效地管理在Google中的调用BigTable的结构化数据,BigTable被设计使得PB级别的数据和成千上万的机器的数据变得可靠。BigTable已经达到了这几个目标:广泛的应用,易扩展因,高效性和高度可用性。Google有超过六十多个产品和项目都使用了BigTable,其中包括了谷歌分析(Google Analytics),谷歌财政(Google Finance),我酷社交网(Orkut),个人定制化搜索(Personalized Search),自由在线处理(Writely)和谷歌地图等(Google earth),这些产品都用到了BigTable来解决各自不同类型的工作量需求,这些产品从以吞吐量为导向的批量处理的工作到面向最终用户的延迟敏感类数据服务,被用在这些产品上的BigTable集群从配置的广度范围上已经从少数的服务器到成千上万台服务器了,其存储容量也上升到几百TB的数据量了。在许多方面,BigTable像一个数据库:这个数据库与普通的数据库分享了许多的实施策略.并行数据库和主要的内存数据库都已经达到了高度的可扩展性和高性能性。但是BigTable提供了一些与系统不同的接口。BigTable不支持一个完全的关系数据库模型.取而代之的是它提供了一个用简单数据模型的客户端,这个客户端支持对数据层和格式的动态控制,同时他也允许客户端去分析在底层存储上数据代表的区域性.数据被以行名称或者列名称所索引,以至于它所支持的数据是随意的形式。BigTable把数据看作是一种不被解释好的形式。尽管客户端常常连载多种结构化的形式和半结构化的数据到这些事物里面.客户端能够控制通过在他们的模式里面慎重的选择来控制他们数据的区域性。最终,BigTable模式变量让客户端动态的控制是否去从内存提取数据或者从磁盘读取数据.
第二节描述了更详细地数据模型,在第三节提供了客户端API的概述。第四节简短的描述了底层Google的基础设施依赖哪些BigTable.第五节描述了BigTable的实施的基础,第六节详细描述了一些BigTable需要提高的性能.第七节提供了去提高BigTable性能的一些措施.第八节我们描述了有关于如何将BigTable应用到Google上面的几个例子。第九节讨论了一些有关于我们是如何学习设计和支持BigTable的课程.最后在第十节我们描述了一下相关的工作。第十一节表明了我们结论.
2.数据模型
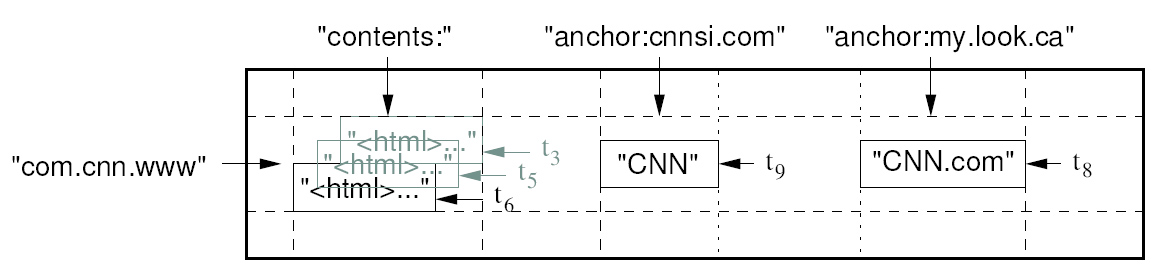
我们在检查了多种类似的BigTable多种的应用的系统之后,才开始决定使用这种数据模型。这里给出了一个具体的例子来阐述为什么我们使用数据模型设计,假设我们需要存储我们想要保存的一个网页大集合和相关信息的副本,而这些东西正是许多不同的项目里面所用到的,让我们称这种特殊的表为WebTable.在WebTable中,我们能够用URLs作为一个行键,网页的不同方面作为列名,同时在Contents列中存储具有被拿取时时间戳的网页内容,如图一所示.
一个BigTable是一个松散的,分布式的,多维排序图,这个图被行键,列键或者是时间戳所索,在图中的每个值都是一个没有被解释的字节数组。图一:是一个存储网页数据的样例表的片段。样例中的行名是一个你转的URL。内容列家族中包含了网页的具体内容,同时在anchor列家族中包含了任何引用这个页面的anchor文本。CNN的主页面被Sports Illustrated和My-Look 主页所引用,因此这行包含了cnnsi.com和my.look.ca命名的anchor列,每一个anchor单元都有唯一的版本,这个内容列则有三个版本,分别是时间戳T3,T5和T6。
Row:
这个行键在表中可以使任意的字符串(尽管10-100字节对于我们大部分用户来说是一种典型的尺寸,目前尺寸已经上升到了64KB),每一次在单个行上面的读取或者写入都是一个最小的原子操作(忽略掉在行上面不同列的读取和写入),这种设计决定使得在同一行上面存在并发更新的系统行为的分析变得更加容易。
BigTable根据行键的字典顺序来维护数据。对于一个表而言,行区间是动态划分的。每一个航区间被称之为tablet,它是分布式和负载均衡的基本单元。它所带来的好处是:读取一个较短的行区间是非常高效的,他只需要和少数几台机器进行通讯。客户端能够利用这种属性,通过选择具有局部性的行键来获得数据的访问。例如在WebTable中,通过逆转URL下面的主机名组件,在相同域名下的页面被分组在同一个连续的行中。例如我们为com.google.maps/index.html键下面的maps.google.com/index.html页面存储数据。将相同域名下面的页面存储在彼此相邻的位置使得一些主机和域名的分析变得非常的高效。
Column families:
列键被分组为成为列家族的集合,它是访问控制的基本单元,多有存储在列家族上面的数据一般都具有相同的类型(我们将相同列家族的数据压缩在一起),在该列家族下面的任何列键下数据能被存储之前,列家族必须被建立.在列家族被建立之后,在该家族下的任何列键都能被使用。我们的意愿是,表中列家族的划分数量尽可能的少(至多几百个),列家族在操作期间几乎不被改变。相反的,一个表却可以拥有无限数量的列。
一个列键通常用如下的语法来命名的:Family:Qualifiers。列家族的名称必须是能被打印的,大事Qualifiers可以使任意的字符串,相应的例子是对于WebSite的列家族是一种语言,这个列家族存储的是编写所存储的网页所用的语言。我们仅仅用一个列键来表示一种家族语言中的一种语言,它存储了每个网页的语言ID。另外一个表中有用的列家族是用单个anchor来表示的。列家族中的每个列键都代表了一个单个achor,正如图一所示.Qualifier是引用网站的名称,这个单元格内容是一个链接文本。
访问控制和磁盘或者内存的统计是在列家族层面进行操作的。在我们的WebTable例子中,这些控制允许我们管理几个不同的应用:一些应用负责增加新的基础数据,一些应用负责查看一些基础数据,一些应用负责创建衍生的列家族,还有一些应用仅仅允许我们读取已经存在的基础数据(有些时候由于某种私人原因甚至只让我们查看部分数据).
Each cell in a Bigtable can contain multiple versions of
the same data; these versions are indexed by timestamp.
Bigtable timestamps are 64-bit integers. They can be as-
signed by Bigtable, in which case they represent “real
time”in microseconds,orbeexplicitlyassignedbyclient
TimeStamps:
在BigTable中的每个数据单元都能包含相同数据的多个版本,这些版本是根据时间戳索引的。BigTable的时间戳是64位的整数。他们能够被BigTable所指定,这种指定可以使根据真实的微妙级别的时间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号