CodeForces 构造题专项解题报告(一)
CodeForces 构造题专项解题报告(一)
来源:CodeForces *constructive algorithms
推荐阅读:
- 11. [1672F] - Array Shuffling & Checker for Array Shuffling
- 41. [1526D] - Kill Anton
1. [1772F] - Copy of a Copy of a Copy
- Rating:2000
- Status:Solve
- Evaluate:Easy
注意到如下的观察:
观察:
对于每个可修改位置
,如果 被修改后,与 相邻的四个格子将不能被修改 因此每个
最多被修改一次
所以对于每个图片
由于上面的观察我们能够推知每个位置的修改是没有后效性的,也就是修改位置的顺序没有影响,因此每次修改的位置就是相邻两张图片中不同的那些位置,直接枚举即可
时间复杂度
2. [1763C] - Another Array Problem
- Rating:2000
- Status:Hint + Data
- Evaluate:Medium
注意到如下的观察:
观察:
对于任意一个
的 ,存在一种方法将子序列 全部赋值成 首先连续操作
: 然后操作
,此时整个子序列都会变成
运用上面的方法,对于
时间复杂度
3. [1736D] - Equal Binary Subsequences
- Rating:2200
- Status:No Solve
- Evaluate:Hard
显然:0 和 1 出现的次数如果是奇数那么一定无解
对于剩下的情况,注意到如下的观察:
观察:
我们定义第
位和第 位的字符构成一个“字符组”( ),那么通过一次轮转操作,我们一定能使得原串中只含有字符组 00和11,下述操作方法:以字符串
000110111001为例:我们可以将其每两位进行划分得到个字符组: 00 | 01 | 10 | 11 | 10 | 01显然对于字符组
00和11没有操作的必要,而对于字符组10和字符组01,我们对于每个字符组取出其中一个字符,并且满足我们取出的字符串是0和1交替的,由于需要取出字符的字符组中同时包含0和1,所以一定存在这样的取出方案对于上面举的例子,我们对第
个字符组取出第 位 0,对第个字符组取出第 位 1,对第个字符组取出第 位 0,对第个字符组取出第 12位1,最终得到取出的子序列0101对取出的子序列右移一位,由于
0和1出现的次数都是偶数,所以字符组01和字符组10的数量总和应该也为偶数,因此得到的子序列长度也是偶数,右移一位后恰好得到原序列取反,如例子中右移得到子序列1010把取出的子序列放回去,那么被取出
0的字符组有一个1没被操作,又获得了一个1,那么我们就得到了字符组11,同理,被取出1的字符组会变成字符组00,如例子中得到了序列00 | 11 | 00 | 11 | 11 | 00
根据观察中的构造方法,我们可以对于每个字符串通过右移使字符串仅由字符组 00 和 11 构成的,那么对于每个字符组,给
时间复杂度
4. [1734E] - Rectangular Congruence
- Rating:2100
- Status:Solve
- Evaluate:Easy
注:数值计算均在
首先考虑对
那么对于
那么由题目的限制我们知道
考虑一种构造:对于所有
此时:对于任意
由于
此时第
时间复杂度
5. [1730D] - Prefixes and Suffixes
- Rating:2200
- Status:Hint
- Evaluate:Hard
先对
根据上面的转化,有一个显然的观察:一对同位置的
根据上面的观察得到:只要确定
因此对于最终的状态
对于
:
- 如果
,那么 - 如果
,那么
注意到有如下观察:
观察:
对于任意的一个状态表示
,都存在一种合法的操作序列使我们能够得到一个合法的终态 恰好能够用 表示 对于每一次操作,我们会使
的前 位翻转, 的前 位逐位取反后翻转 事实上,我们只需要证明存在一种操作使得我们能从任意一个状态
开始,经过若干次操作使得 和 ,剩下的步骤由数学归纳法即可得到 不妨假设在
中 对应 ,那么通过操作 和 就可以把 移动到 上,此时 会变成 ,如果我们需要保证 不变,那么在操作 之前先操作一次 就可以使得 移动到 并且保持值不变
因此,我们得到了原题的操作等价于任意重排
由于我们翻转了原序列,那么我们等价于让
考虑一组相对下标
因此我们维护每个无序字符对
不过对于 map 来统计
时间复杂度
6. [1726D] - Edge Split
- Rating:2000
- Status:Solve
- Evaluate:Easy
定义
注意到有如下观察:
观察:
理论上
的最小值应该是 ,当且仅当 和 都是森林 考虑一个逐个加边的过程,最开始答案应该是
,当我们加入一条边 ,加入后 会减少 当且仅当在与其同色的图中 连接了两个不同的连通块,这是根据 的定义得来的 但我们又知道在一个森林中的每条边都是连接两个不同连通块的,因此每条边都对答案有
的贡献,故当且仅当 和 中都是森林(即无环)时 取得最小值
注意到
在得到这个观察之后,我们有一个非常显然的想法:由于原图联通,所以让
那么选择怎样的
注意到这样的
不妨设我们向
对于这个问题,我们有如下的观察:
观察:
在一条路径
中,假设 为深度较大的点,那么 到其父亲的边一定在路径 中 证明很简单,假设
是一个任意的点,考虑什么时候 到其父亲的边不在路径 中,显然,如果 ,那么 到其父亲的边一定在路径中,而如果 ,那么显然深度较大的点会变成 ,即此时我们必然不可能选择 到其父亲的边,而是选择了 到其父亲的边
所以我们只需要随便取一棵
时间复杂度
7. [1704E] - Count Seconds
- Rating:2200
- Status:Hint+Data
- Evaluate:Medium
首先考虑一个最简单的想法,统计每个点会收到多少流量,最后答案为汇点接受的流量
但是这个想法无法处理部分
不过也不是所有存在
注意到如下的观察:
观察:
在至少
秒后就不存在非“平凡”的零权点 证明如下,考虑非“平凡”的零权点的生成,每个非“平凡”的零权点可以理解为祖先有流量正在运输,还没有抵达当前节点的点
那么注意到一个祖先的流量到当前点的延迟时间为这两个点的距离
由于 DAG 上最长链长度是
的,因此在 轮之后每个 的祖先都开始向当前节点运输流量 而且由于每个祖先运输流量的时间是连续的,因此当
时其祖先一定没有流量还在运输
根据上面的观察,我们可以先预处理出原图的拓扑序,然后模拟
时间复杂度
8. [1684E] - MEX vs DIFF
- Rating:2100
- Status:Solve
- Evaluate:Medium
注意到有如下的观察:
观察:
最优方案一定是每次修改
为当前序列的 显然如果修改的
,那么其对答案的贡献至多是 ,显然,做这样的一次操作肯定是不优的 假如修改
且 ,那么一定会把 修改成另一个 的值,那么每种情况对答案的贡献为:
,贡献为 ,贡献为 ,贡献为 ,贡献为 其中
为序列 中从 开始最多的连续自然数的数量,显然 那么我们发现把每次
赋成 一定不弱于把 赋成某个其他的 的值
那么根据上面的分析,我们应该每次修改一个
那么为了求出
再求出了
显然可以用一个小根堆维护这个过程,注意如果小根堆已经删空了,说明此时所有数 0
时间复杂度
9. [1682D] - Circular Spanning Tree
- Rating:2000
- Status:Solve
- Evaluate:Easy
先判定无解的情况:若所有点的度数都为偶数或者又奇数个点的度数也为奇数时,该问题无解
那么对于剩下的情况,度数为奇数的点都恰好有偶数个
我们可以先构造一条
我们考虑把这些点按顺序把相邻的点配对,然后构造一种方法使得一对需要改变度数的
考虑令
对于
10. [CF1674E] - Breaking the Wall
- Rating:2000
- Status:Hint+Data
- Evaluate:Easy
考虑两个变成非正整数的位置
此时我们一次操作可以对于
无论是在
一次操作只可能对
因此对于这三种情况分别处理后取最小代价即可
时间复杂度
11. [1672F] - Array Shuffling & Checker for Array Shuffling
- Rating:2000 & 2800
- Status:No Solve
- Evaluate:Hard
先考虑如何计算一个
定义
注意到如下的观察:
观察一:
的权值等于 证明如下:
注意到交换
等价于交换 和 的终点,我们的目标就是使得 中产生 个环 而一次操作可以根据
在 对应的分解中分成是否在同一个环中的两种情况
由上图可得,只要
在同一个环中,无论如何 中的环数会 ,而如果 不在同一个环中,那么 中的环数一定会 因此对于任意的大小为
的环分解,至少需要操作 次,而不断操作两个相邻的 给了我们一种操作 次的方法 综上所述,将
还原至少需要 次操作
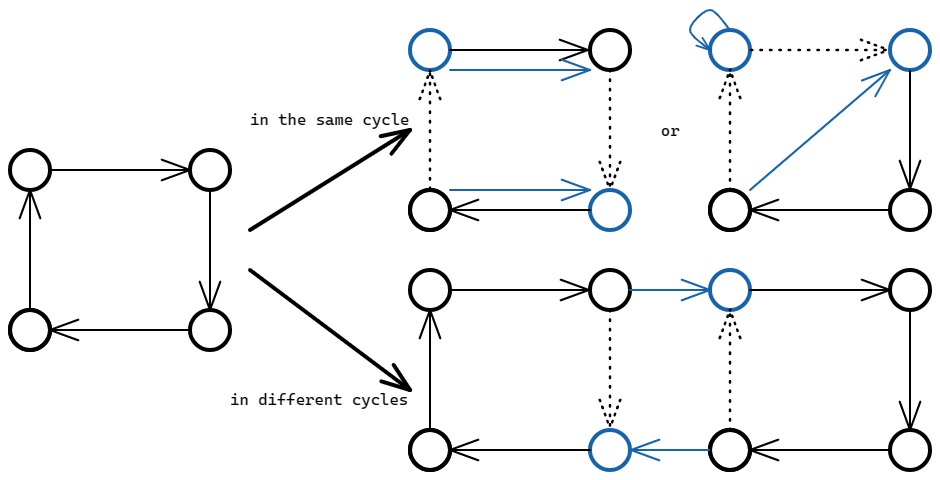
那么原问题就转化为了最小化
记
注意到如下的观察:
观察二:
对于所有
和正整数 , 事实上
等于 中 的入度和出度,那么原命题可以等价于证明: 对于每个
的最大环拆分,不存在一个环经过某个 两次 而根据最大环拆分的定义,经过
两次的环会在最大环拆分中拆成两个环,因此原命题得证
我们假设
猜测答案
考虑什么时候
观察三:
其中 定义为图中的环的数量, 即在 中删除 和所有与 相邻的边得到的新图 中不存在环 证明如下:
- 证
: 考虑逆否命题
那么考虑
中的一个环 :在子图 中,最大的度(等价于众数的出现个数)依然是 ,根据观察二,得到 所以
2. 证考虑逆否命题
由于抽屉原理,在
个环中必然至少有一个不经过 ,那么这个环的存在会使得
因此我们能够解决 F2:对
时间复杂度
接下来继续解决 F1:
构造出一个
那么接下来就是确定每个环的方向使得
有这样的一个想法,在值域
- 对于任意
- 对于所有
那么对于每个环,我们将每个点按
此时如果删去
此处取偏序关系
时间复杂度
12. [1672E] - notepad.exe
- Rating:2200
- Status:No Solve
- Evaluate:Hard
对于一个
首先可以二分出
注意到如下的观察:
观察:
对于所有
, 注意到
即显示器大小,考虑最优的情况, 行字符每行后面都没有多余的空白,即每行字符串的长度都恰好为 ,此时显示其大小
我们又知道对于每一个
因此对于每个
因此我们可以在
时间复杂度
13. [1670E] - Hemose on the Tree
- Rating:2200
- Status:No Solve
- Evaluate:Hard
诈骗题,注意到如下观察:
观察:
对于任意的一棵树,
考虑反证法,假如每个距离都
,那么我们考虑 个 的权值和 条边 根据抽屉原理,至少有一条边的权值
,那么由于我们的假设,不妨设这条边为 ,其中 表示 的父亲,且 那么由于
,那么 ,由于 ,因此 的第 位一定是 ,而 因此 的第 位一定是 ,异或后得到 的第 位上是 ,则 ,与假设矛盾,故原命题得证
根据观察,答案至少为
注意到对于所有
因此考虑除了根以外,每一对
根据上面的分析,我们知道对于任意指定的树根,都存在
时间复杂度
14. [1666J] - Job Lookup
- Rating:2100
- Status:Solve
- Evaluate:Easy
记
一个显然的想法是把
假设我们记
构造方案时记录每个
时间复杂度
15. [1666I] - Interactive Treasure Hunt
- Rating:2200
- Status:Solve
- Evaluate:Medium
注意到对于第一次询问 SCAN r c,由于我们不知道
注意到在
执行这四个查询操作能够得到的对
我们可以得到联立这四个方程得到的方程组对应的行列式应该形如下面的形式:
不过我们发现这样询问四个角的做法是错误的,原因是系数矩阵中有线性相关的行向量,因此我们需要重新选取恰当的四个询问点
注意到询问左上角和右上角得到的两个向量是线性无关的,因此保留询问左上角和右上角的过程可以保留下来
设询问左上角得到回答
那么我们把
此时我们还剩下两个向量没确定,显然在剩下的两个方程中,
假设
类似计算第三个方程的过程,我们在第
最后,我们联立这四个方程能够解出
不过注意到我们实际上不能得到
不过我们注意到目前只用了 DIG r1 c1,通过返回的结果是
时间复杂度
16. [1665D] - GCD Guess
- Rating:2000
- Status:Solve
- Evaluate:Medium
注意到
不过我们每次询问一个
因此我们考虑如何压缩状态,比如对于
所以直接将
假设我们选用的所有质数乘积为
但是如果
显然,存在一种方法使得
注意到我们只询问了
给一组合法的构造:
这样我们就可以在恰好
时间复杂度
17. [1659E] - AND MEX Walk
- Rating:2000
- Status:Hint
- Evaluate:Medium
注意到如下的观察:
对于任意的节点对
,其答案只有可能是 中的一个 对于任意的路径
记 注意到 ,那么显然 中不可能同时出现 和 故对于任何一条路径其
所以我们只需要解决两个问题:
- 是否存在一条路径
- 是否存在一条路径
先解决第一个问题:
显然,假如
因此我们可以对于每个
考虑第二个问题:
由于此时所有路径
考虑
- 在
因此对于每个问题我们维护
时间复杂度
18. [1656E] - Equal Tree Sums
- Rating:2200
- Status:No Solve
- Evaluate:Hard
不妨记节点
对于每个节点
那么对于所有
因此对于每个
我们对于一个叶子
根据这样的观察,我们可以大胆假设
对于叶子结点,显然有
,这是成立的 接下来我们按照深度序进行归纳:对于任意一个节点
,设其所有儿子 都满足
- 如果
,那么 - 如果
,那么
那么从任意一个点作为根 dfs 一遍整棵树即可
时间复杂度
19. [1646D] - Weight the Tree
- Rating:2000
- Status:Hint
- Evaluate:Medium
注意到如下的观察:
观察:
对于任意
,树上不会有任何两个相邻的好节点 假设树上有一条边
,由于 ,因此至少有一个点的度数 ,设 此时若
和 均为好节点,由于 ,而由于 ,所以 ,同理由于 是好节点,所以 ,故矛盾 特别地,若
则 度数均为 ,所以 时可以选择两个好节点相邻
简单讨论剩下的情况:
- 若
- 若
可以证明这样的方案是最优的,注意到只要确定所有非好节点的权值就可以确定所有的节点的权值,假如某个非好节点权值改变使得
剩下确定每个点是不是好节点的过程可以考虑使用 dp,令
而最小化权值只需要在比较两个方案优劣的时候作为比较的第二关键字顺便转移一下即可
构造方案时按照转移顺序计算每个节点是由子节点的
时间复杂度
20. [1641B] - Repetitions Decoding
- Rating:2000
- Status:No Solve
- Evaluate:Hard
显然,如果有元素出现次数为奇数,则必定无解
考虑如何用题目中的操作复制一个序列 1 2 3 4,显然每次在序列中间插入下一个数可以得到序列 1 2 3 4 4 3 2 1
考虑
代码实现用 vector 每次调用 reverse 函数和 erase 函数即可
时间复杂度
21. [1638D] - Big Brush
- Rating:2000
- Status:Solve
- Evaluate:Easy
考虑从结果入手,每次选择一个
由于每个位置只会被最后一个操作覆盖,那么倒序操作时已经被操作的格子可以重复操作
因此每次选择一个合法的同色方格清空一定没有后效性,注意到每个格子至多被清空一次,所以操作次数一定在
不过如果暴力找操作位置是
注意到清空一个方格后,只有可能影响与其相交的
如果 BFS 结束后还有位置没被清空则输出无解
时间复杂度
22. [1635E] - Cars
- Rating:2200
- Status:Solve
- Evaluate:Easy
注意到确定位置的过程是和每个点的方向有关的,因此考虑先确定方向
注意到如果
注意到这里的 2-SAT 只存在
- 合并所有
- 如果存在
- 讨论每个块的 01 情况,用一个标记维护每个块是否确定了 01 情况,对于每个
- 如果
- 如果
- 如果
这样我们能够确定一组合法的
因此我们可以建立一个差分约束系统,注意到这个系统的所有边权都是
不过我们需要保证对于任何一组合法的
我们只能通过每次对一个块内所有节点取反来修改
,注意到如果差分系统中存在一个环,那么这个环中的节点一定是在一个块内的,假如我们对这个块内所有节点的 取反,等价于对这个差分系统里这些节点之间的边取反,显然这样的操作是不可能消掉差分系统里的环的
因此只要求解出随意一组合法的
时间复杂度
23. [1634D] - Finding Zero
- Rating:2000
- Status:Solve
- Evaluate:Medium
同样的序列交互找特殊位置的问题,感觉上和 1762D 有点相似,那么考虑能否借鉴这道题的思路来求解
在 1762D 中,我们每次用
那么由于操作限制为
此时考虑进行排除的四个数
观察到结果中有两个
不过由于题目不保证非
不过由于我们每次排除
计算一下操作次数:
因此这个策略是可以通过本题的
时间复杂度
24. [1624F] - Interacdive Problem
- Rating:2000
- Status:Solve
- Evaluate:Easy
假设每次询问操作不会改变
显然,对于一个询问 + c,返回
接下来考虑这道题,假设初始
时间复杂度
25. [1621D] - The Winter Hike
- Rating:2000
- Status:Hint
- Evaluate:Medium
显然右下部分所有积雪必定清空,而我们注意到如下的观察:
观察:
对于任何一种操作方案,至少会经过右上部分的四个顶点或左下部分的四个顶点之一
假如我们操作左上部分,的第
行、第 行、第 列、第 列中的任何一个,左上部分的 个端点中必有一个接触到这 个顶点之一
而且我们发现这
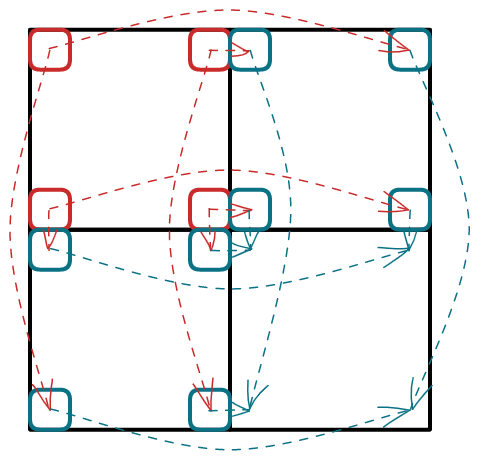
其中红色的边为每个学生走到积雪上的可能路径,而蓝色的边表示从这
因此我们只需要这
时间复杂度
26. [1620D] - Exact Change
- Rating:2000
- Status:Data
- Evaluate:Easy
设
有一个显然的策略:选
可以证明当
- 如果
- 如果
- 如果
因此根据上面的规则简单模拟即可
时间复杂度
27. [1619F] - Let's Play the Hat?
- Rating:2000
- Status:Solve
- Evaluate:Easy
考虑一个显然的贪心:按
事实上这个贪心的正确性很好证明:
对于任意
,这样的贪心总是满足 对
采用归纳法:容易证明 时 ,因此我们只需要考虑对于一个满足的限制的 操作即可 记此时
中 的有 个,而大桌子能坐的总人数为 ,有以下三种情况:
:此时一部分 变成 ,此时 和 都不变 :此时所有 都 变成 ,此时 , 不变 :此时所有 变成 ,此时一部分 变成 ,此时 , 显然以上三种情况都不会增加
的大小,因此这个贪心是正确的
可以考虑用排序或者优先队列维护
时间复杂度
28. [1605D] - Treelabeling
- Rating:2100
- Status:Hint
- Evaluate:Medium
记
考虑
- 证明
考虑
的第 位,显然为 ,因此 ,所以
- 证明
不妨设
,考虑其逆否命题 考虑
的第 位,显然为 ,因此 ,所以
设
注意到如下的观察:
观察:
总存在一种染色方案使得无论从哪个点出发,Sushi 都无法进行任何一次移动
考虑对图黑白染色,我们只需要保证对于
个类,不存在一个类中同时包含黑色点和白色点上的数 那么我们需要把这
个类划分到黑色或者白色里面去 注意到前
个 类的大小恰好是 ,因此可以表示出 之间的所有数 由于我们可以证明黑色点集和白色点集中较小的一个的大小一定
,因此我们可以用前 类权值表示其中一个点集,剩下的表示另外一个点集即可
按照上面所述的构造求解即可,时间复杂度
29. [1593D] - Changing Brackets
- Rating:2200
- Status:No Solve
- Evaluate:Hard
由于题目数据进行了保证,以下的讨论均在
记
注意到 [ 和],( 和 ) 没有区别,因为它们可以在不花费代价的情况下互相转化
所以我们只需要防止形如 ([)] 的情况出现即可
观察一个合法的序列,我们发现任意一对匹配的 [] 中间都有一个合法的括号序列,而这个括号序列的长度一定是偶数
因此每一对匹配的 [ 和 ],这两个字符在原串的下标一定是一奇一偶的
假设在串
观察:
对于任意
, 考虑对
归纳: 当
的时候,若 ,那么显然 可以通过把前一半小括号变成 (,后一半小括号变成)来满足题目要求如果
,此时可以证明任意两个中括号间的字符数量都是奇数,因此这中间不存在任何一对可以配对的中括号 由于在一个合法的括号匹配序列中,任取一段匹配的子串删去仍然是一个合法的括号匹配
那么当
我们必然可以找到一对相邻的,分别处于奇偶位置上的中括号,我们取出这两个中括号和其中间的所有字符构成的子串 容易发现其中间恰好有偶数个小括号,而有且仅有两侧的中括号,显然这个子串可以在
的代价内处理成一个匹配括号序列,因此将这个序列从 中删去,容易发现 ,那么根据归纳假设即得证
因此我们能够大胆猜想,对于任意
证明:
考虑对每个代价为
的操作,显然可以通过枚举分讨证明一次修改只会对 产生 的贡献,所以想要使得 ,至少需要 次代价为 的操作
显然每次将
中较大的那个数对应的那些下标中选一个操作成小括号即可得到一个代价为 的操作方案,所以 因此结合两个方向的不等号得到
因此每次计算一个子段的答案只需要预处理出
时间复杂度
30. [1583E] - Moment of Bloom
- Rating:2200
- Status:No Solve
- Evaluate:Hard
考虑一个点周围的边覆盖次数的综合,对于一条
因此我们记录
考虑所有
观察:
在保证所有
都是偶数的情况下,任取一棵原图的生成树,对于所有 取 的树上简单路径,此时构造满足题目要求 对树的大小进行归纳:
考虑树的任意一个叶子
,由于 ,注意到此时根据构造有 ,因此我们可以删去 到其父亲的边 所以此时我们把从
出发的 条路径扔到 上,即令 ,此时由于 ,因此新的 仍然是偶数 然后我们在树中删除节点
和边 ,此时得到的新树的一个合法的解也对应原树的一个合法的解,然后在新树上运用归纳假设即可证明原命题
所以求出图中的一棵生成树然后对于每个询问用朴素算法求 LCA 并且输出路径即可
时间复杂度
31. [1567D] - Expression Evaluation Error
- Rating:2000
- Status:Solve
- Evaluate:Easy
考虑对
首先考虑对 1 数码给到一个不同的
对于每次分拆找
时间复杂度
32. [1566E] - Buds Re-hanging
- Rating:2000
- Status:No Solve
- Evaluate:Hard
首先注意到,每一次把一个 bud 节点放到一个叶子上,会使得叶子结点的总数
假如我们已经把所有的 bud 节点都提取出来了,那么接下来考虑按照提取的顺序依次加入剩下的节点构成的剩余树上
假设我们有
而在求所有 bud 节点的时候,我们记录下每个点是否为 bud 节点,如果一个节点所有儿子中有一个不是 bud 节点,那么这个节点一定是 bud 节点,否则则不是 bud 节点,因此我们把“是不是 bud 节点”作为 dfs 的返回值即可
时间复杂度
33. [1560F2]- Nearest Beautiful Number (hard version)
- Rating:2100
- Status:Solve
- Evaluate:Easy
考虑直接进行 dp,记
由于其取得最小数值一定要先让高位尽可能小,因此查到一组解可以直接 break
时间复杂度
34. [1558C] - Bottom-Tier Reversals
- Rating:2000
- Status:Hint
- Evaluate:Medium
首先,我们注意到对于每次操作,每个值所在下标的奇偶性并不会改变,因此我们得到了一个有解的必要条件:对于任意
在剩下的情况中,由于总限制是
- 在
- 递归求解剩下的
这样只要保证在求解 剩下的
注意到我们有如下的
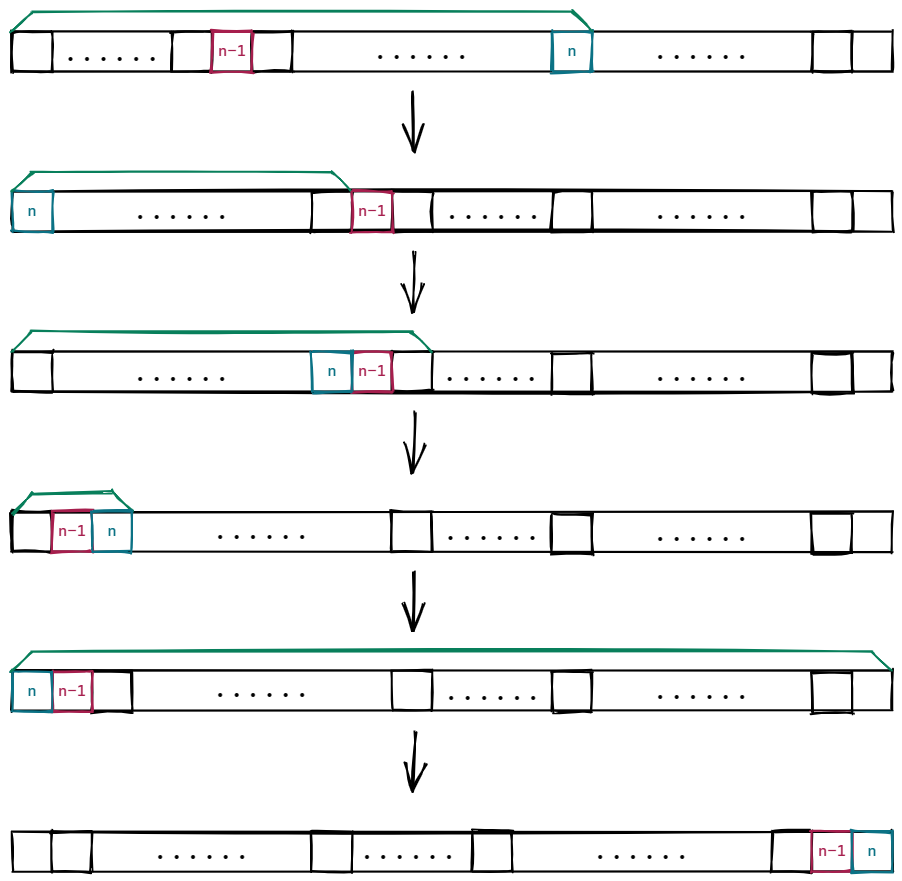
因此按照这个构造我们能够在
每次操作暴力找到
时间复杂度
35. [1553E] - Permutation Shift
- Rating:2100
- Status:Hint
- Evaluate:Medium
通过交换元素使一个排列
由于我们发现对
注意到每次检查一个
观察:
对于任意的
,合法的 的数量不超过 个 对于一个排列
,每次操作至多使 个 复位,因此在原本的 中至多只有 个 失配,所以满足 的至少 个 回到原问题上,对于某个位置
,有且仅有一个 使得 左移 位后得到 ,因此对于所有 ,匹配的 的数量总和为 通过抽屉原理,我们得到:合法的
的数量不超过
根据观察,又因为数据范围中保证
所以我们只需要对于每个
时间复杂度
36. [1552E] - Colors and Intervals
- Rating:2300
- Status:Hint
- Evaluate:Medium
记
注意到每个点至多被覆盖
首先,根据贪心观察知道,对于每个颜色
对于一个给定的
所以对于每个颜色
此时我们可以这样想:由于每个颜色有
假如每个序列中的颜色段互不相交,则对于每个序列,每个位置至多被覆盖一次,此时的构造方案是满足要求的
注意到每次生成一个序列不好做,那么考虑从一次取出所有选择了第
因此我们要做的就是对于每个
考虑在解“选出尽可能多的不相交线段”这一问题的方法,我们在处理第
事实上这个做法是正确的:
证明:
采用反证法:假设这样选择后存在两个区间
和 相交,其中 那么不妨假设
由于颜色
并没有被选做第 段,那么我们知道 由于
,所以 ,所以 ,因此这样相交的区间不存在,所以原命题得证
因此对于每个
时间复杂度
37. [1551D] - Domino (easy version) & (hard version)
- Rating:1700 & 2000
- Status:Data
- Evaluate:Easy
显然考虑把
由于题目已经保证了
此时最右边一列用竖着的骨牌填满,假如竖着的骨牌不足
剩下的列考虑用
显然先把一行用横着的骨牌填满,假如横着的骨牌不足
剩下的一样考虑构造方块,类似上一种情况,当且仅当剩下的的骨牌数为偶数时有解
此时直接构造方块,有解当且仅当
根据上面的分析,我们能够得到判定条件和构造方案,模拟即可
时间复杂度分别为
38. [1543D] - RPD and Rap Sheet (easy version) & (hard version)
- Rating:1700 & 2200
- Status:Solve
- Evaluate:Easy
先从 easy version 入手考虑:
先假设每次操作完不改变
那么在改变
注意到每次询问
时间复杂度
接下来考虑
定义
我们可以证明运算
每当我们询问
假设第
因此我们分别维护前面的
时间复杂度
39. [1537F] - Figure Fixing
- Rating:2200
- Status:Hint
- Evaluate:Medium
显然我们可以把原问题转化成下面的形式:
对于每条边
,指定一个整数权值 ,使得对于每个节点 ,所有与 相邻的边的权值和为
此时假如我们把每个
先判定原方程是否有解,那么我们考虑一组系数
由于每个
对整个图进行黑白染色,黑点系数为
接下来考虑判定原方程是否有一组整数解,同样考虑一组系数
但这样的判定只能在二分图上进行,且判定结果与上面的判定是等价的
对于非二分图,我们只能考虑
因此总结一下:
- 对于二分图,判断其左部点的
- 对于非二分图,判断其所有点的
对整张图进行黑白染色并分类按照判定条件判断即可
时间复杂度
40. [1530E] - Minimax
- Rating:2100
- Status:Hint+Data
- Evaluate:Medium
记
假设我们对字符串里的字符从小到大重新标号为
对
-
显然,此时所有
-
-
假如
此时
-
假如
猜测对于任意
记
-
可以以
此时
因此
因此此时的
-
只能以
此时应该有
-
能以
只需使
此时
-
只能以
此时应该有
此时
-
-
-
先对
时间复杂度
41. [1526D] - Kill Anton
- Rating:2200
- Status:No Solve
- Evaluate:Hard
记
首先考虑在给定了
观察一:
满足对于任意字符串 满足 均有 证明很简单,考虑
的实际意义,即 的最少操作次数,而 则表示了 的一种操作方案,其代价为 由于
需要满足其操作数最小,因此对于任意一种合法的 操作方案, 应该不大于其操作数,而 的方案显然也是一种 的合法操作方案,所以得到
注意到如下的观察:
观察二:
对于
的最后一个字符 ,设 在 中最后一次出现是在位置 上,那么 考虑在计算两个排列的距离的方法,每次复原最后一个字符,然后解决前面长度
的子串 对于此处,我们也可以从后到前依次复位,不过每次把哪个
放到 上是我们需要解决的问题 考虑贪心,每次选取最后的一个
放到 上,此时代价为 ,而剩下的字符串复位的代价就是 现在我们要证明这个贪心的正确性,那么不妨考虑一个下标
满足 且 那么我们只需证明
,事实上这等价于证明 而我们又注意到
,因此根据观察一,原命题得证
为了维护
事实上,考察上面计算
不过在这题中,
而我们注意到如下的观察:
观察三:
最大化
的 中相同的字符一定连续 考虑任意一个
,计算 ,考虑两个字符相同的位置 和 ,为了简化讨论,我们假设 且 中没有与 相等的字符,显然根据 的定义有 此时我们只需要证明总存在一种方式使
相邻且不减少 的逆序对数 由于要让这两个相邻,一种显然的方法就是循环移位,而根据移动的字符分成如下两种情况:
- 让
的字符全部向后移动 位,并把 移动到 上 - 让
的字符全部向前移动 位,并把 移动到 上 考虑区间
中的每一个 ,考虑修改后 对答案的贡献
- 对于第一种方式,若
,那么逆序对数 ,如果 ,那么逆序对数 - 对于第二种方式,若
,那么逆序对数 ,如果 ,那么逆序对数 记
表示 中 的数的个数,而 表示 中 的数的个数 根据上面的分析,我们得到第一种方式对逆序对数的贡献为
,第二种方式对逆序对数的贡献为 假如
,那么直接选择第一种操作就可以使得 相邻且 逆序对数量不减 假如
,即 由于
,我们知道 ,与 联立得到: 因此此时
,所以第二种操作的代价 ,此时选择第二种操作可以使得 相邻且 逆序对数量不减 根据上面的分析,我们知道对于任何一对字符相同的
,若 中没有与其相同的字符,总存在一种方式使得 相邻并且 不减少
根据上面的观察,我们只需要枚举
时间复杂度
42. [1521C] - Nastia and a Hidden Permutation
- Rating:2000
- Status:Solve
- Evaluate:Easy
首先考虑通过指定
假设在第一种操作中,我们令 ? 1 i j n-1 的结果会变成
那么原问题转化成找到
接下来我们应该考虑采用第二种操作,我们令 ? 2 i j 1 的结果会变成
注意到此时我们剩下的操作数大约为
而我们记录下所有让返回答案
考虑交换 ? 2 j i 1,那么对于每对可能的
所以我们再对于每个可能的
43. [1520F] - Guess the K-th Zero (easy version) & (hard version)
- Rating:1600 & 2200
- Status:Hint+Data
- Evaluate:Medium
简单版本是非常容易解决的,直接在原序列上进行二分,每次检查
时间复杂度
接下来考虑困难版本,最显然的做法是复制容易版本
考虑优化,假设每次猜到
而每次修改
- 修改
- 询问
? 1 x的答案为
因此我们要维护
计算一下记忆化后的询问次数,我们可以把二分的过程转成在线段树上逐步向下的过程,那么询问次数就是在一棵动态开点线段树中插入
时间复杂度
44. [1513E] - Cost Equilibrium
- Rating:2300
- Status:Hint+Data
- Evaluate:Medium
记
首先求出
考虑将每个
若
对于每次操作,看成从某个源点
考虑对于给定的
所以根据上面的分析,当
而
当
因此处理出
时间复杂度
45. [1513D] - GCD and MST
- Rating:2000
- Status:Hint
- Evaluate:Medium
容易把第一种连边条件转化为
此时生成森林一定是若干个连续的区间构成一棵树,把剩下的边用
但是这种做法对于每个
考虑优化,注意到如下的观察:
观察:
当遇到一个
使 构成环后,再往后的 一样会生成环,在这个地方直接 break掉即可我们只需要证明,每次
break后区间已经是联通的 考虑数学归纳法,当前所有区间
已经考虑完毕并联通,考虑下一个区间 ,只需要证明 不会越过这个区间去连接,即不存在 满足 或 ,注意到这种 只会在 时发生,此时有 ,因此这样的 不存在,故原命题得证
这样每个点至多同时作为某个区间的左端点和右端点,访问次数不会超过
时间复杂度
46. [1495C] - Garden of the Sun
- Rating:2300
- Status:No Solve
- Evaluate:Hard
首先考虑的思路应该是对于奇数行都全部变成 X,偶数行就自动和上下的奇数行连接,但是这样可能会形成多个环
一个比较自然的思路是按行号 X,这样第
注意到任意一个 X 周围 .,因此对于某个在 X,.,因此我们直接把 X,能连通第 X 也一样,把 X 即可
假如不存在这样的 .,那么任取同一列的两个位置变成 X 即可
注意一个需要特判的边界情况:若 X 都是独立的,其间两两都不联通,因此对于每个为 X 的 X 即可
时间复杂度
47. [1494D] - Dogeforces
- Rating:2300
- Status:Data
- Evaluate:Medium
看到父亲的权值大于儿子的权值,首先想到 Kruskal 重构树
显然两个点 LCA 处的权值就是合并这两个点所在连通块时的那条边的边权,因此我们把所有
但是这题略有不同,这题要求父亲的权值严格大于儿子的权值,因此我们要进行一定的分类讨论,假设当前我们需要新建一条边,连接
-
最基本的情况,用 Kruskal 重构树原本的处理方案,新建一个节点
-
此时假如我们新建
-
同上一种情况,设
-
非常有趣的情况,我们应该要把
时间复杂度
48. [1493C] - K-beautiful Strings
- Rating:2000
- Status:Hint
- Evaluate:Medium
字符串下标从
观察到
若
为了让字典序尽量小,我们可以从大到小枚举
对于每个前缀
接下来我们枚举
根据题意能够计算出
记
虽然构造一个
综上所述,总时间复杂度为
49. [1486E] - Paired Payment
- Rating:2200
- Status:Solve
- Evaluate:Easy
注意到
对于每次移动
因此对于每个边
此时在这张图上求一遍最短路即可
时间复杂度
50. [1485D] - Multiples and Power Differences
- Rating:2200
- Status:Hint
- Evaluate:Medium
假设
不过本题要求
由于
时间复杂度


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
· SQL Server 2025 AI相关能力初探
· 为什么 退出登录 或 修改密码 无法使 token 失效