关于tensorflow的数据输入的有关问题(一)
作为新手,最近看完了一本有关tensorflow的课本,打算自己拿一些练习题来练练手,没想到在第一步的数据输入就着实卡了好几天。于是,今天来记录一下自己在解决这个问题中学习到的新知识。
tensorflow数据读取机制
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责计算任务,所需数据直接从内存队列中获取。tf在内存队列之前,还设立了一个文件名队列,文件名队列存放的是参与训练的文件名,要训练 N个epoch,则文件名队列中就含有N个批次的所有文件名。
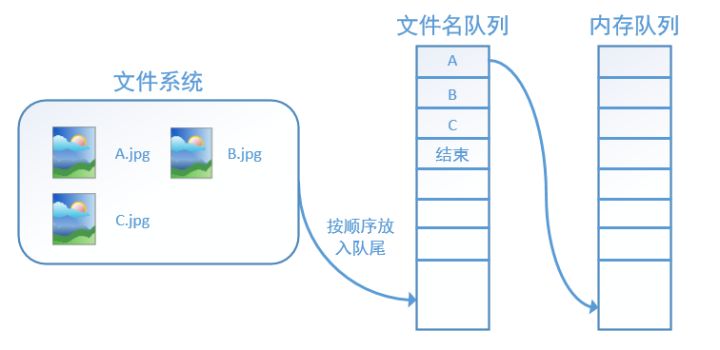
【好处:
内存队列,使得系统先在内存中对数据进行缓存,将硬盘的数据不断的向内存中开辟的buffer中进行搬运。对于计算设备,采用另一个数据读取的线程,每次计算时候,直接从内存中的buffer中读取数据。以此达到同步进行的目的,彼此之间不会发生阻塞,提高了对资源的利用率,也一定程度上加快了网络的训练。
而文件名队列,则使得我们对epoch有了更好的管理。对于硬盘上存放的数据,首先将硬盘上的数据文件名存放在文件名队列中,内存队列从文件名队列中进行数据的读取,计算设备之间从内存中读取运算所需数据。】
在N个epoch的文件名最后是一个结束标志,当tf读到这个结束标志的时候,会抛出一个 OutofRange 的异常,外部捕获到这个异常之后就可以结束程序了。而创建tf的文件名队列就需要使用到 tf.train.slice_input_producer 函数。
tf.train.slice_input_producer
这个函数是一个tensor生成器,其作用是按照设定,每次从一个tensor列表中按顺序随机抽出一个tensor放入队列。
特别需要强调的是tf.train.slice_input_producer只是定义了样本放入文件名队列的方式,包括迭代次数,是否乱序等,要真正将文件放入文件名队列,还需要调用tf.train.start_queue_runners函数来启动执行文件名队列填充的线程,之后计算单元才可以把数据读出来,否则文件名队列为空的,计算单元就会处于一直等待状态,导致系统阻塞。
tf.train.start_queue_runners
QueueRunner类用来启动tensor的入队线程,可以用来启动多个工作线程同时将多个tensor(训练数据)推送入文件名称队列中,具体执行函数是 tf.train.start_queue_runners , 只有调用tf.train.start_queue_runners 之后,才会真正把tensor推入内存序列中,供计算单元调用,否则会由于内存序列为空,数据流图会处于一直等待状态。
tf.train.batch函数
tf.train.batch是一个tensor队列生成器,其作用是按照给定的tensor顺序,把batch_size个tensor推送到文件队列,作为训练一个batch的数据,等待tensor出队执行计算。
具体可参考:(6条消息) 详解tensorflow的slice_input_producer、string_input_producer和tf.train.batch函数_Accelerating的博客-CSDN博客
tf.train.string_input_producer()
跟tf.train.slice_input_producer()类似,不过是针对文件的生成器,传入文件路径列表,每次吐出一个文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号