Raft一致性算法
所有的分布式系统,都面临的一个问题是多个节点之间的数据共享问题,这个和团队协作的道理是一样的,成员可以分头干活,但总是需要共享一些必须的信息,比如谁是 leader, 都有哪些成员,依赖任务之间的顺序协调等。所以分布式系统要么自己实现一个可靠的共享存储来同步信息(比如 Elasticsearch ),要么依赖一个可靠的共享存储服务,而 Etcd 就是这样一个服务。
Etcd 如何实现一致性的?
说到这个就不得不说起raft协议。
有关Raft协议和工程实现可以参考这个链接https://raft.github.io/,里面包含了大量的论文,视屏已经动画演示,非常有助于理解协议。
概念与术语
leader:领导者,提供客户提供服务(生成写日志)的节点,任何时候raft系统中只能有一个leader。
follower:跟随者,被动接受请求的节点,不会发送任何请求,只会响应来自leader或者candidate的请求。如果接受到客户请求,会转发给leader。
candidate:候选人,选举过程中产生,follower在超时时间内没有收到leader的心跳或者日志,则切换到candidate状态,进入选举流程。
termId:任期号,时间被划分成一个个任期,每次选举后都会产生一个新的termId,一个任期内只有一个leader。termId相当于paxos的proposalId。
RequestVote:请求投票,candidate在选举过程中发起,收到quorum(多数派)响应后,成为leader。
AppendEntries:附加日志,leader发送日志和心跳的机制
election timeout:选举超时,如果follower在一段时间内没有收到任何消息(追加日志或者心跳),就是选举超时。
Raft协议主要包括三部分,leader选举,日志复制和成员变更。
Raft协议的原则和特点
a.系统中有一个leader,所有的请求都交由leader处理,leader发起同步请求,当多数派响应后才返回客户端。
b.leader从来不修改自身的日志,只做追加操作
c.日志只从leader流向follower,leader中包含了所有已经提交的日志
d.如果日志在某个term中达成了多数派,则以后的任期中日志一定会存在
e.如果某个节点在某个(term,index)应用了日志,则在相同的位置,其它节点一定会应用相同的日志。
f.不依赖各个节点物理时序保证一致性,通过逻辑递增的term-id和log-id保证。
e.可用性:只要有大多数机器可运行并可相互通信,就可以保证可用,比如5节点的系统可以容忍2节点失效。
f.容易理解:相对于Paxos协议实现逻辑清晰容易理解,并且有很多工程实现,而Paxos则难以理解,也没有工程实现。
g.主要实现包括3部分:leader选举,日志复制,复制快照和成员变更;日志类型包括:选举投票,追加日志(心跳),复制快照
leader选举流程
关键词:随机超时,FIFO
服务器启动时初始状态都是follower,如果在超时时间内没有收到leader发送的心跳包,则进入candidate状态进行选举,服务器启动时和leader挂掉时处理一样。为了避免选票瓜分的情况,比如5个节点ABCDE,leader A 挂掉后,还剩4个节点,raft协议约定,每个服务器在一个term只能投一张票,假设B,D分别有最新的日志,且同时发起选举投票,则可能出现B和D分别得到2张票的情况,如果这样都得不到大多数确认,无法选出leader。为了避免这种情况发生,raft利用随机超时机制避免选票瓜分情况。选举超时时间从一个固定的区间随机选择,由于每个服务器的超时时间不同,则leader挂掉后,超时时间最短且拥有最多日志的follower最先开始选主,并成为leader。一旦candidate成为leader,就会向其他服务器发送心跳包阻止新一轮的选举开始。
发送日志信息:(term,candidateId,lastLogTerm,lastLogIndex)
candidate流程:
1.在超时时间内没有收到leader的日志(包括心跳)
2.将状态切换为candidate,自增currentTerm,设置超时时间
3.向所有节点广播选举请求,等待响应,可能会有以下三种情况:
(1).如果收到多数派回应,则成为leader
(2).如果收到leader的心跳,且leader的term>=currentTerm,则自己切换为follower状态,
否则,保持Candidate身份
(3).如果在超时时间内没有达成多数派,也没有收到leader心跳,则很可能选票被瓜分,则会自增currentTerm,进行新一轮的选举
follower流程:
1.如果term < currentTerm,说明有更新的term,返回给candidate。
2.如果还没有投票,或者candidateId的日志(lastLogTerm,lastLogIndex)和本地日志一样或更新,则投票给它。
注意:一个term周期内,每个节点最多只能投一张票,按照先来先到原则
日志复制流程
关键词:日志连续一致性,多数派,leader日志不变更
leader向follower发送日志时,会顺带邻近的前一条日志,follwer接收日志时,会在相同任期号和索引位置找前一条日志,如果存在且匹配,则接收日志;否则拒绝,leader会减少日志索引位置并进行重试,直到某个位置与follower达成一致。然后follower删除索引后的所有日志,并追加leader发送的日志,一旦日志追加成功,则follower和leader的所有日志就保持一致。只有在多数派的follower都响应接受到日志后,表示事务可以提交,才能返回客户端提交成功。
发送日志信息:(term,leaderId,prevLogIndex,prevLogTerm,leaderCommitIndex)
leader流程:
1.接收到client请求,本地持久化日志
2.将日志发往各个节点
3.如果达成多数派,再commit,返回给client。
备注:
(1).如果传递给follower的lastLogIndex>=nextIndex,则从nextIndex继续传递
.如果返回成功,则更新follower对应的nextIndex和matchIndex
.如果失败,则表示follower还差更多的日志,则递减nextIndex,重试
(2).如果存在N>commitIndex,且多数派matchIndex[i]>=N, 且log[N].term == currentTerm,
设置commitIndex=N。
follower处理流程:
1.比较term号和自身的currentTerm,如果term<currentTerm,则返回false
2.如果(prevLogIndex,prevLogTerm)不存在,说明还差日志,返回false
3.如果(prevLogIndex,prevLogTerm)与已有的日志冲突,则以leader为准,删除自身的日志
4.将leader传过来的日志追加到末尾
5.如果leaderCommitIndex>commitIndex,说明是新的提交位点,回放日志,设置commitIndex =
min(leaderCommitIndex, index of last new entry)
备注:默认情况下,如果日志不匹配,会按logIndex逐条往前推进,直到找到match的位置,有一个简单的思路是,每次往前推进一个term,这样可以减少了网络交互,尽快早点match的位置,代价是可能传递了一些多余的日志。
快照流程
避免日志占满磁盘空间,需要定期对日志进行清理,在清理前需要做快照,这样新加入的节点可以通过快照+日志恢复。
快照属性:
1.最后一个已经提交的日志(termId,logIndex)
2.新的快照生成后,可以删除之前的日志和以前的快照。
删日志不能太快,否则,crash后的机器,本来可以通过日志恢复,如果日志不存在,需要通过快照恢复,比较慢。
leader发送快照流程
传递参数(leaderTermId, lastIndex, lastTerm, offset, data[], done_flag)
1.如果发现日志落后太远(超过阀值),则触发发送快照流程
备注:快照不能太频繁,否则会导致磁盘IO压力较大;但也需要定期做,清理非必要的日志,缓解日志的空间压力,另外可以提高follower追赶的速度。
follower接收快照流程
1.如果leaderTermId<currentTerm, 则返回
2.如果是第一个块,创建快照
3.在指定的偏移,将数据写入快照
4.如果不是最后一块,等待更多的块
5.接收完毕后,丢掉以前旧的快照
6.删除掉不需要的日志
日志最终可能被覆盖掉,比如下图:
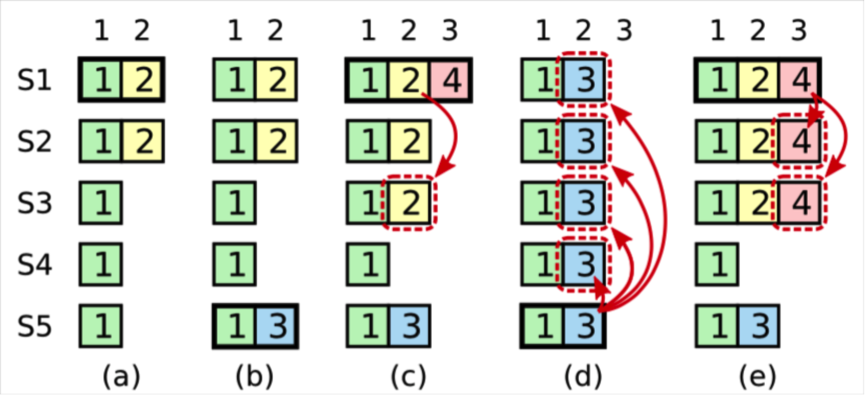
(a).S1是leader,termId是2,写了一条日志到S1和S2,(termId,logIndex)为(2,2)
(b).S1 crash,S5利用S3,S4,S5当选leader,自增termId为3,本地写入一条日志,(termId,logIndex)为(3,2)
(c).S5 crash,S1 重启后重新当选leader,自增termId为4,将(2,2)重新复制到多数派,提交前crash
(d).S1 crash,S5利用S2,S3,S4当选leader,则将(3,2)的日志重新复制到多数派,并提交,这样(2,2)这条日志曾经虽然达成多数派也会被覆盖。
(e).假设S1在第一个任期内,将(2,2)达成多数派,则后面S3不会成为leader,也就不会出现覆盖的情况。
参考自:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号