
PTA题目集1~3的总结
一、前言
1.题目集1:
在此次作业中,初步了解了java的语言特性,了解了封装的概念。第一次作业较为简单,前四题的仅需设计一或两个合理的类便能迎刃而解。最后一题的逻辑较为复杂,需设计多个类完成整个功能的实现,并且需要对输入的格式进行处理,此时采用正则表达式便可完成对输入字段的提取。
2.题目集2
第二次作业中,前三题的难度与题目集1差不多。而最后一题则是在题集1最后一题的基础上添加了更多的需求,而此时才发现第一次的设计并不合理,导致无法在原有的基础上进行修改,只能重新推倒重来。在最后一道题中,采用了如哈希表、链表等数据结构进行存储与优化,有效的增强了程序的可读性与维护性。
3.题目集3
这是最后一次作业,同时也是难度最大的一次作业,尽管只有三道题,但完成此次作业的时间却远远大于前两次。在第二题中,起初并没有使用任何的日期类,而是自己编写了一个日期类,但自行编写会导致程序十分复杂,随后了解到LocaDate类,能够很好的适配于该题。而此次作业的第三题,又在第二次作业的基础上添加了新的功能与要求,并且存在大量的非法输入需要检测,因此花了大量时间来排查bug。
二、设计与分析
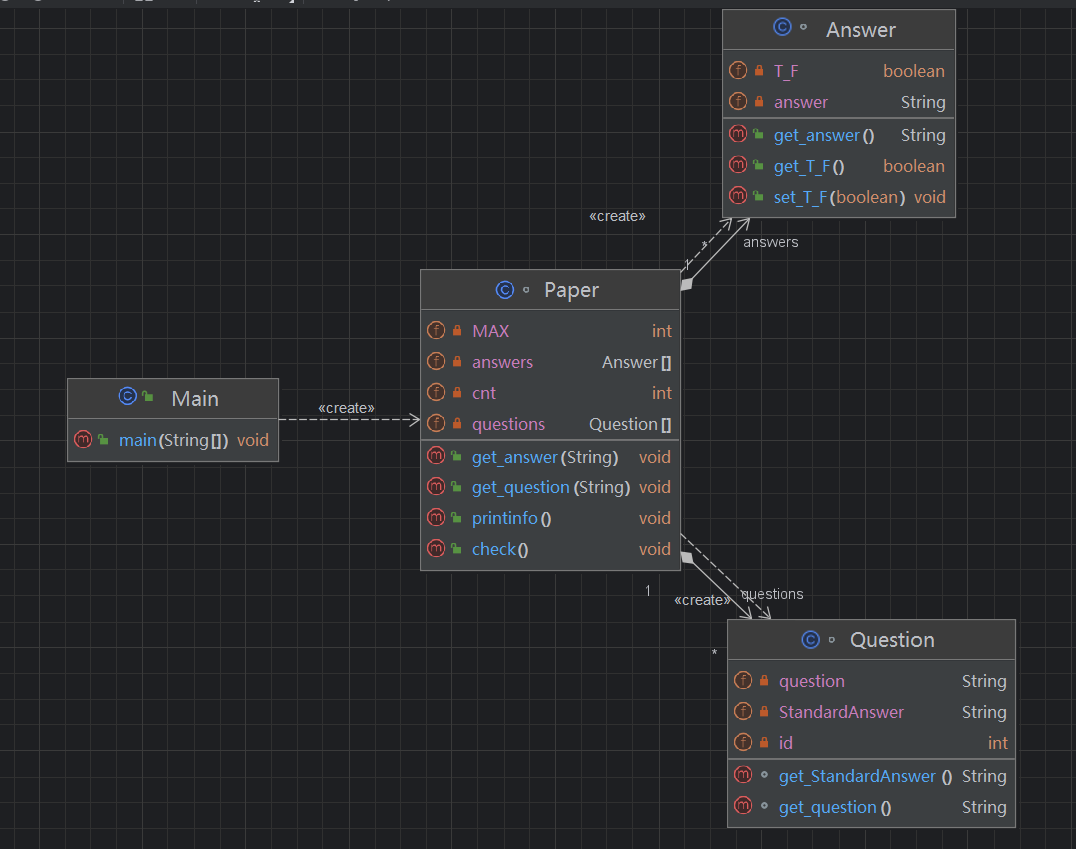
1.答题判题程序1
第一次大作业的设计较为简单,使用三个类即可解决,分别是试卷类、题目类、答卷类。在此次作业中,由于仅有两种格式的输入(题目,答案),因此可认为试卷只有一张,所以直接在试卷类中集成了题目类与答卷类的数组(这同时也是我第二次作业无法在此基础上进行更改的原因),而题目类与答卷类中仅作为存储数据的容器。
正则表达式
输入采用正则表达式进行提取信息:
//题目正则表达式
String regex = "#N:\s*(\d+)\s*#Q:\s*(.*?)\s*#A:\s*([\w]+)\s*";
//答案正则表达式
String regex = "#A:\s*([\w]+)\s*";
答卷批改函数
批改试卷部分代码,通过String类的equals方法直接对答案的正确性属性进行赋值:
public void check(){
for(int i = 1;i <= cnt;i++){
answers[i].set_T_F (questions[i].StandardAnswer.equals(answers[i].get_answer()));
}
}
相关类图
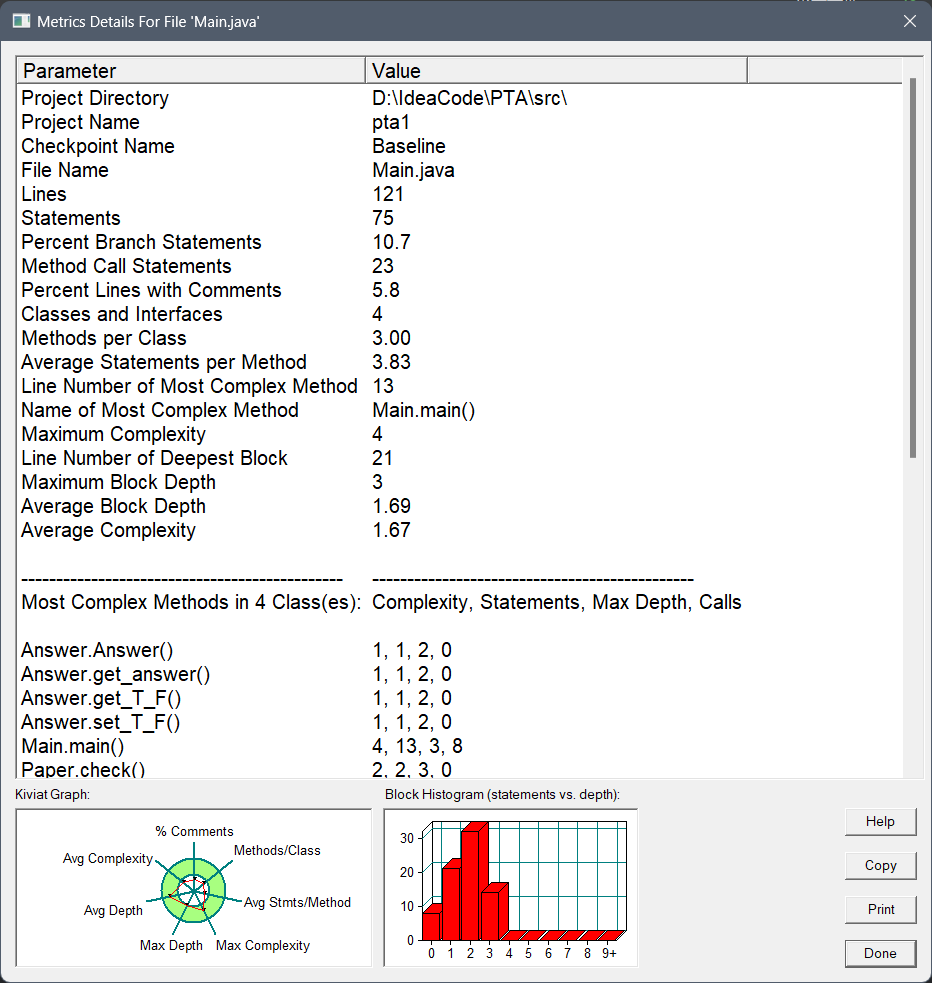
SourceMontor的生成报表
2.答题判题程序2
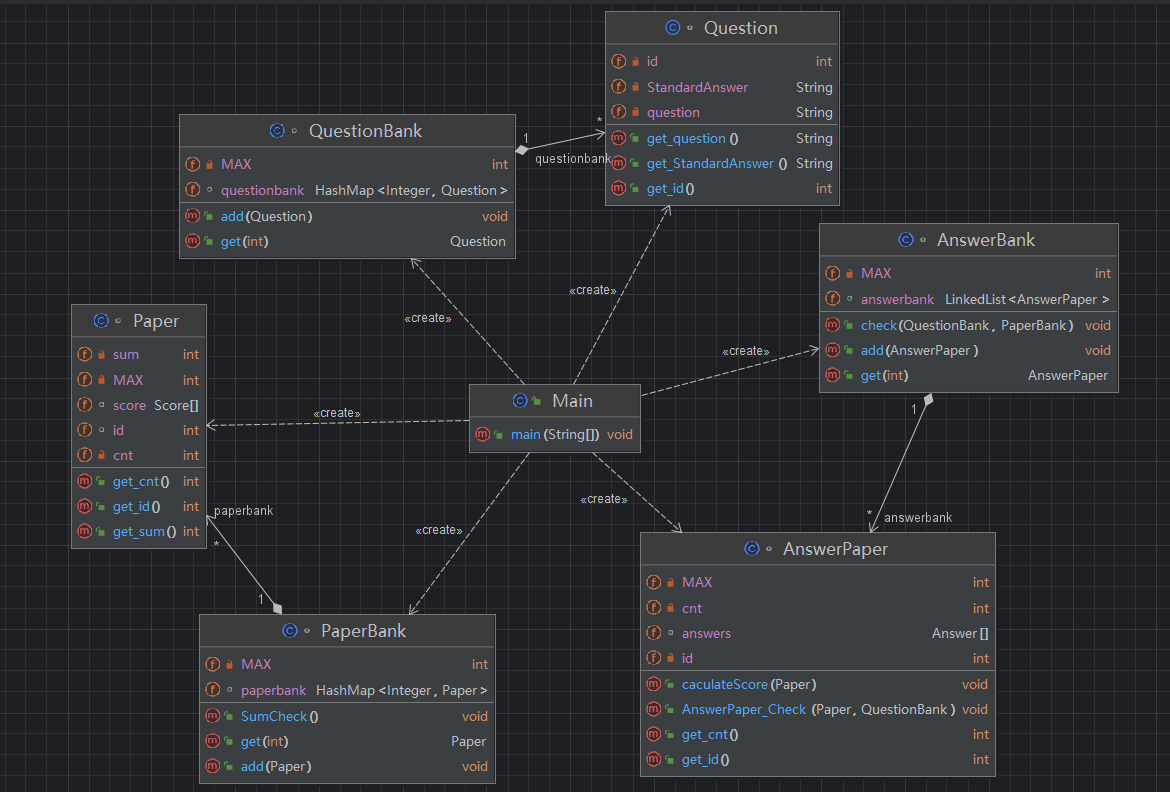
第二次大作业的难度大大提升,因第一次的设计不合理,导致难以在其基础上进行更改。在此次题目中,新增了试卷信息,并且三种信息的输入无序,因此无法实时进行判断,需要将信息全部接收并存储后再进行处理。于是设计了题库类,试卷类以及答卷类进行存储数据,其中题库与试卷库采用哈希表维护,以便在答卷批改时进行查询操作,而答卷库采用链表维护,答卷并不需要进行查询操作,仅需进行遍历、插入操作,并且在批改答卷时需要保持输入的顺序,而哈希表会对内部数据进行排序操作,导致输入顺序被打乱,因此使用链表维护答卷库更加适合。
正则表达式:
输入采用正则表达式进行提取信息:
//题目正则表达式
String regex = "#N:\\s*(\\d+)\\s*#Q:\\s*(.?)\\s#A:\\s*([\\w]+)\\s*";
//答案正则表达式
String regex1 = "#S:\\s*(\\d+)";
String regex2 = "#A:\\s*([\\w]+)\\s*";
//试卷正则表达式
String regex1 = "#T:\\s*(\\d+)\\s*";
String regex2 = "\\s*(\\d+)-(\\d+)\\s*";
计算试卷总分函数
在此次作业中,新增了对试卷总分的判断,因此在批改答卷之前,需要对试卷的总分进行计算。
public void SumCheck(){ //检查总分是否等于100
for(Integer i : paperbank.keySet()){ //遍历试卷库
if(paperbank.get(i).get_sum() != 100)
System.out.println("alert: full score of test paper"+paperbank.get(i).get_id()+" is not 100 points");
}
}
答卷库遍历函数:
由于答卷全部存储在答卷库中,遍历答卷库,进行相关的查询操作,并调用答卷批改函数。
public void check(QuestionBank q,PaperBank p){
for (AnswerPaper answerpaper : answerbank) { //遍历答卷库
int PaperId = answerpaper.get_id(); //试卷id
Paper paper = p.get(PaperId); //取得该试卷
answerpaper.AnswerPaper_Check(paper, q); //批改该答卷
}
}
答卷批改函数:
答卷在批改过程中,首先应对试卷的存在性进行判断,再进行后续操作。试卷若存在,则遍历试卷上的题目并进行判分,由于答卷上的答案与试卷的题目顺序对应,因此当试卷上题目的顺序编号大于答案数量时,便可认为该题目的答案为空,并输出相关信息。
public void AnswerPaper_Check(Paper paper,QuestionBank q){
if(paper != null){
for(int j = 0; j < paper.get_cnt();j++){
int QuestionId = paper.score[j].id; //问题id
Question question = q.questionbank.get(QuestionId); //取得该题
if(get_cnt() <= j){ //试卷以外的题目输出answer is null
System.out.println("answer is null");
continue;
}
answers[j].T_F = question.get_StandardAnswer().equals(answers[j].answer_content); //设置答案正确性
System.out.println(question.get_question()+"~"+answers[j].answer_content+"~"+answers[j].T_F);
}
caculateScore(paper); //计算总分并输出
}
else
System.out.println("The test paper number does not exist"); //不存在该试卷id
}
相关类图
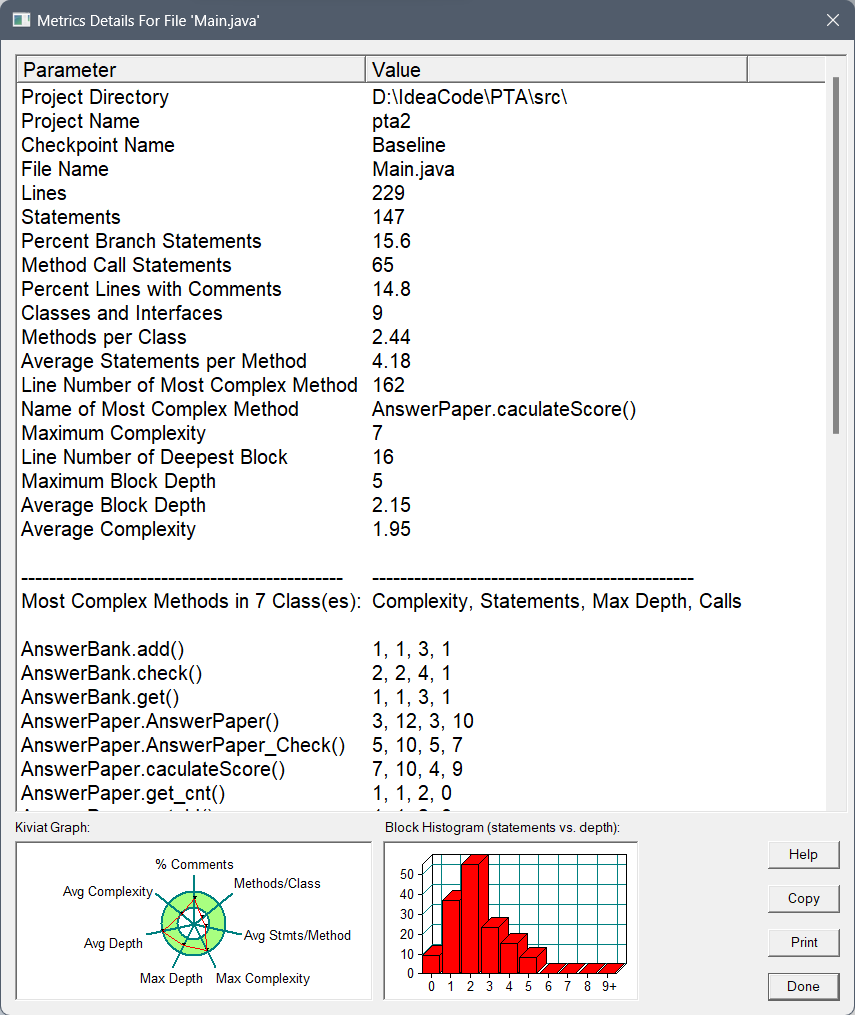
SourceMontor的生成报表
3.答题判题程序3
第三次大作业在第二次的基础上又新增了两种输入,分别是学生信息以及题目删除信息,因此添加了学生类以及学生库类,并且在题目类添加是否被删除的属性。此次作业增加了许多非法输入的判断,需根据不同的情况输出不同的信息,导致在写代码时思路非常乱,在经过一段时间的整理后才理清思路。
-
首先是判断输入格式是否正确,格式错误则抛弃此次输入并输出相关信息。
-
判断试卷是否为100分,这里与上一题相同(不多赘述)。
-
遍历答卷库进行答卷批改,判断答卷作答的试卷是否存在,不存在则输出相关信息。
-
遍历试卷题目,判断题目是否存在,不存在则输出相关信息。
-
判断答卷是否对该题进行作答,不存在则输出相关信息。
-
判断该题是否被删除,已删除则输出相关信息。
-
对该题进行批改。
-
批改完该答卷后,判断是否存在该学生,不存在则输出相关信息。
-
按要求输出该答卷的得分信息等。
正则表达式
输入采用正则表达式进行提取信息:
//题目正则表达式
String regex = "#N:\\s*(\\d+)\\s*#Q:\\s*(\\S.*?)\\s*#A:\\s*(\\S.*?)\\s*$";
//试卷正则表达式
String regex1 = "#T:\\s*(\\d+)";
String regex2 = "(\\d+)-(\\d+)";
//答卷正则表达式
String regex1 = "#S:\\s*(\\d+) (\\d+)";
String regex2 = "#A:(\\d+)-(.*?)(?=\\s+#A:|\\s*$)";
//学生正则表达式
String regex = "\\s*(\\d+)\\s*([\\w]+)\\s*";
//题目删除正则表达式
String regex = "#D:N-\\s*(\\d+)";
格式判断
在经过几十次的提交后,发现格式错误的样例仅有题目错误以及试卷错误,但还是对所有输入进行了格式判断。对于试卷、答卷以及学生的输入,一行中存在多个信息,无法通过正则表达式是否提取到内容来判断格式是否错误,因此可以采用字符串拼接的方式将提取的信息以及固定格式进行拼接,将结果与原字符串进行比较,从而判断出格式错误。
这里仅给出试卷格式判断的相关代码
String compare = "#T:";
String regex = "#T:\\s*(\\d+)"; //提取试卷的正则表达式
if(matcher.find()){
... //提取信息省略
compare = compare + matcher.group(1);
}
else{
System.out.println("wrong format:"+str);
return ;
}
regex = "(\\d+)-(\\d+)";
while(matcher.find()){
.... //提取信息省略
compare = compare + matcher.group(1)+"-"+matcher.group(2);
}
if(!s.equals(compare)){
System.out.println("wrong format:" + str);
return;
}
答卷批改函数
此次作业的批改函数大体上与上次相同,只是加入了许多错误信息的判断(这里便不再给出源码,详细见上一题的答卷批改函数),但有一点需要注意的是,答卷答案添加了试卷题目的顺序id,不再是像第二题一样顺序对应,因此需要从答卷中寻找与题目顺序id对应的答案,为了方便查询,我在答卷类中添加了存贮答案的哈希表。
相关类图
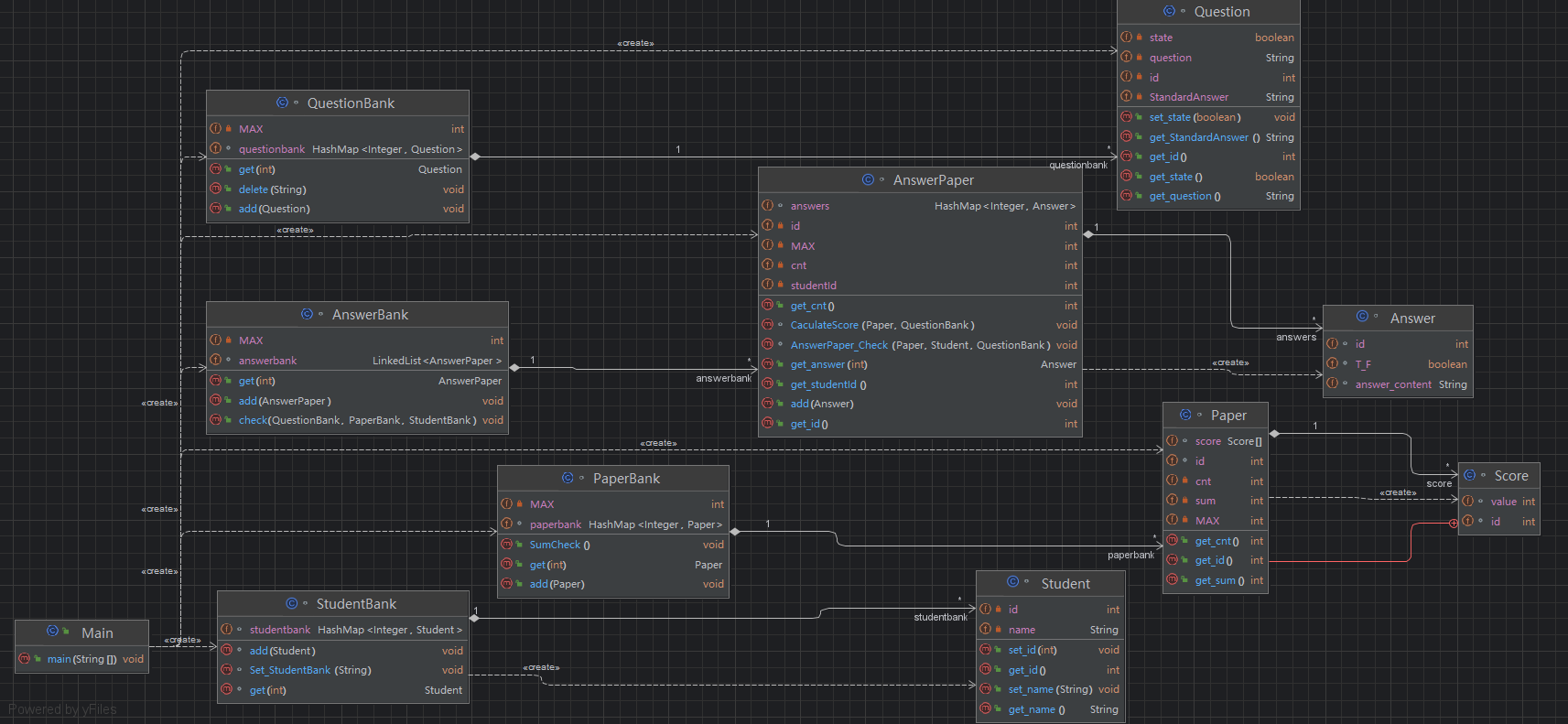
SourceMontor的生成报表
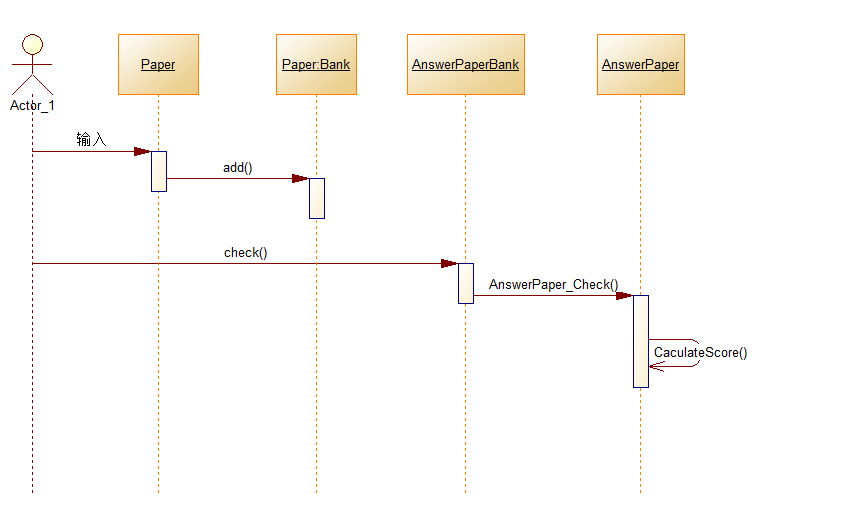
顺序图
三、 踩坑心得
在这三次作业中,大量使用到了正则表达式,而输入的数据中,会存在空格字符,需要识别并去除空白字符,第一二次作业的测试样例能够全部通过,导致第三次作业掉以轻心,继续沿用之前的正则表达式,没有仔细查看,导致一些极端案例没有通过。
第三次作业中增加了删除题目的输入,起初以为是将题目切切实实地从存储的容器中删除,导致花费了大量时间来检查,实际上仅需给题目类增添一个是否删除的属性即可解决。
第二三次作业中,试卷类采用的存储容器为哈希表,作业中需要输出试卷是否为100分的信息,并且需要按照试卷的输入顺序进行输出。如果遍历哈希表的话,无法保证输出的顺序仍为输入顺序,在查阅相关资料后,了解到HashMap的子类LinkedHashMap,LinkedHashMap通过内部维护一个双向链表来实现内部数据按照输入顺序排列。
四、改进建议
在第二三次作业中,题目、试卷、答卷等都采用对应的库类存储,而每个库实际只创建了一个,因此,为了减少各种库对象作为实参在函数中进行传参的次数,可将各个库类中的存储容器与方法都设为静态方法,无需再依赖于对象,直接调用其方法即可。
其实第三次作业中的正则表达式仍存在问题需要改正,或许只有提取题目的正则表达式可以真正的去除每一个空白字符,但由于其他正则表达式在测试的过程中并未发现错误,因此并没有纠正过来。
五、 总结
经过这三次大作业的洗礼,对于java语言这种面向对象的编程方式有了更加深入的理解,在面对逻辑复杂,以及需要不断更改需求的业务中,面向对象的优势完全是大于面向过程的,但前提是类的设计合理,不然就会像我编写的第一次大作业一样,无法应用到后续的作业中。
这三次大作业的输入都存在相应的格式,采用正则表达式可以有效的完成信息的提取,起初我对于正则表达式并不感冒,认为其编写方式过于抽象,不仅需要理解各类字符代表的含义,而且存在部分字符需要进行转义,最后写出来的也是晦涩难懂,但经过深入的学习之后才发现,正则表达式对于字符串的处理极其方便,正确的正则表达式能够从乱七八糟的输入中提取符合条件的信息。
第三次大作业给我的印象尤为深刻,各种各样的非法输入都快给我整😡红😡温😡了!已经深刻理解到了对于那些在酒吧点炒饭、炒粉、蒸羊羔、蒸熊掌、蒸鹿尾儿、烧花鸭、烧雏鸡、烧子鹅,卤猪、卤鸭、酱鸡、腊肉、松花、小肚儿、晾肉、香肠儿,什锦苏盘儿、熏鸡白肚儿、清蒸八宝猪.......的人的痛恨了。
意见
希望在题目集结束后能够讲解一下解题思路,大家对于自己实实在在写过的题的讲解的兴致应该会更高,写出来的同学说不定可以学到更好的设计与思路,没写出来的同学也能了解到自己的设计缺陷。
题目集结束后能够公布测试案例,看到自己离满分还差一步之遥还是挺可惜的(不过似乎会有泄露给下一届的风险😋)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号