基于Python的机器学习算法——sklearn模块
基于Python的机器学习算法
安装包:
pip install numpy #安装numpy包
pip install sklearn #安装sklearn包
import numpy as np #加载包numpy,并将包记为np(别名)
import sklearn #加载sklearn包
python中的基础包:
numpy:科学计算的基础库,包括多维数组处理、线性代数等
pandas:主要用于数据处理分析,提供了简单高效的dataframe对象,可以完成数据清洗预处理可视化
scikit-learn:基于python语言的机器学习算法库,建立在numpy、scipy、matplotlib之上,基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。导入该包:import sklearn
scikit-learn包中包含的算法库
.linear_model:线性模型算法族库,包含了线性回归算法, Logistic 回归算法
.naive_bayes:朴素贝叶斯模型算法库
.tree:决策树模型算法库
.svm:支持向量机模型算法库
.neural_network:神经网络模型算法库
.neightbors:最近邻算法模型库
1. 使用sklearn实现线性回归
-
线性回归一般用于预测
-
使用sklearn包中的linear_model模块,linear_model中的LinearRegression函数
基本框架
import sklearn #加载sklearn包
from sklearn import linear_model #导入线性回归算法库
model = linear_model.LinearRegression() #线性回归模型
model.fit(x_train, y_train) #训练模型
model.predict(x_test) #预测
代码(生成数据拟合线性回归模型并预测)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
x = np.linspace(3,6,30) #生成3到6之间的等间隔的30个数,x是包含30个元素的一维数组
y_train = 3*x+2 #根据x和y之间的函数关系式生成一维数组y
x_train = x+np.random.rand(30) #增加波动,np.random.rand是生成0到1之间的随机数
plt.scatter(x_train,y_train) #画散点图
x_train = [[i] for i in x_train] #将x转化为n*1维,即30个样本,每行一个样本,fit函数需要输入二维矩阵
y_train = [[i] for i in y_train] #将y转化为n*1维,即30个样本,每行一个样本
model = linear_model.LinearRegression() #线性回归模型
model.fit(x_train,y_train) #用x和y的数据拟合线性回归模型
print("系数为:",model.coef_) #输出线性回归模型的系数
print("截距为:",model.intercept_) #输出线性回归模型的截距
x_test = np.array([[4],[5],[6]]) #定义测试集的x值
y_predict = model.predict(x_test) #预测测试集对应的y值
print(y_predict) #输出y的预测值
plt.plot(x_test,y_predict,color = "red")
plt.show() #输出图
输出结果
系数为: [[2.76169992]]
截距为: [1.54437963]
[[12.59117932]
[15.35287925]
[18.11457917]]

2. 使用sklearn实现logistic回归
-
logistic回归一般用于二分类问题,是有监督的分类学习算法
-
使用sklearn包中的linear_model模块,linear_model中的LogisticRegression函数
代码(使用sklearn中自带的鸢尾花数据集拟合模型并分类)
from sklearn.linear_model import LogisticRegression #导入logistic回归算法
from sklearn.datasets import load_iris #导入sklearn中自带的鸢尾花数据集
from sklearn.model_selection import train_test_split #导入划分样本的方法
iris_dataset = load_iris() #载入鸢尾花数据集
print("数据类型是:{}".format(type(iris_dataset['data'])))
print("数据集的前5个样本是:\n{}".format(iris_dataset['data'][:5]))
#划分训练集和测试集,'target'是分类变量,random_state用来复现随机划分结果,参数shuffle控制是否打乱顺序(默认True),默认训练集比例75%
x_train,x_test,y_train,y_test = train_test_split(iris_dataset['data'],iris_dataset['target'],test_size = 0.3,random_state = 1)
log_reg = LogisticRegression(max_iter = 3000) #设置最大迭代次数3000,默认是1000
log_reg.fit(x_train,y_train) #模型拟合
print("对测试集的类别预测:",log_reg.predict(x_test))
print("预测正确的样本数占测试集总样本数的比例:",log_reg.score(x_test,y_test))
输出结果
数据类型是:<class 'numpy.ndarray'>
数据集的前5个样本是:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
对测试集的类别预测: [0 1 1 0 2 1 2 0 0 2 1 0 2 1 1 0 1 1 0 0 1 1 2 0 2 1 0 0 1 2 1 2 1 2 2 0 1 0 1 2 2 0 2 2 1]
预测正确的样本数占测试集总样本数的比例: 0.9777777777777777
3. LASSO回归与岭回归
-
代码
###lasso from sklearn.linear_model import Lasso,LassoCV #导入模型 from sklearn.metrics import r2_score #导入衡量指标 import numpy as np #导入numpy包 import pandas as pd #导入pandas包 import matplotlib.pyplot as plt #导入绘图包 ###通过画图确定lambda范围 lambdas = np.logspace(-5,2,200) lasso_coff = [] for i in lambdas: lasso = Lasso(alpha = i,normalize = True,max_iter = 10000) #构建模型,数据标准化 lasso.fit(x_train,y_train) #数据拟合 lasso_coff.append(lasso.coef_) #系数 plt.figure(dpi = 200) plt.style.use('ggplot') plt.plot(lambdas,lasso_coff) plt.xscale('log') #对x轴做对数处理 plt.xlabel('Log10(lambda)') plt.ylabel('coef') plt.show() ###交叉验证确定最优的lambda lasso_cv = LassoCV(alphas = lambdas,fit_intercept = True,normalize = True, cv = 10,n_jobs = 1,max_iter = 10000) #fit_intercept是否包含截距,n_jobs指明是否并行运行,默认值为1不并行,等于-1时将全部CPU用于运算,max_iter是最大迭代次数,默认是1000次 lasso_cv.fit(x_train,y_train) #训练数据 best_lambda = lasso_cv.alpha_ #找到最优的lambda ###模型预测 lasso = Lasso(alpha = best_lambda,normalize = True,max_iter = 10000) #normalize的默认值是False lasso.fit(x_train,y_train) #数据训练 pd.Series(index = ['intercept']+x_train.columns.tolist(),data = [lasso.intercept_]+lasso.coef_.tolist()) #获取系数和截距 y_predict = lasso.predict(x_test) #预测测试集的y值 print('模型得分为:{}'.format(r2_score(y_test,y_predict)))岭回归与lasso的用法一样,只需把Lasso换为Ridge
4. KNN算法
-
KNN(K-Nearest-Neighbor)算法主要用于多分类问题,是有监督的分类学习算法。
-
基本原理:要判断未知类别的样本所属的类别,可以计算该样本与其余所有已知类别样本之间的距离,找到距离该未知样本最近的K个已知样本,根据少数服从多数的原则,将未知样本与K个最近邻样本中所属类别最多的归为一类。
-
KNN算法不需要估计参数,不需要训练模型;
-
若出现样本不平衡时,如一个类的样本数很多,其它类的样本数很少时,可以采用对样本取权值的方法来改进KNN算法。
-
sklearn提供了neighboors模块,可用来实现KNN算法
-
neighboors模块中包含下列方法:
类方法 说明 KNeighborsClassifier KNN算法解决分类问题 KNeighborsRegressor KNN算法解决回归问题 RadiusNeighborsClassifier 基于半径来查找最近邻的分类算法 NearestNeighbors 基于无监督学习实现KNN算法 KDTree 无监督学习下基于 KDTree 来查找最近邻的分类算法 BallTree 无监督学习下基于 BallTree 来查找最近邻的分类算法 -
代码(使用sklearn中的红酒数据集进行KNN分类预测)
from sklearn.datasets import load_wine #从sklearn的数据库中载入红酒数据 from sklearn.neighbors import KNeighborsClassifier #导入KNN分类函数 from sklearn.model_selection import train_test_split #导入分割数据集的方法 import numpy as np #导入numpy wine_dataset = load_wine() #加载数据集 print("红酒数据集的键:\n{}".format(wine_dataset.keys())) print("数据集描述:\n{}".format(wine_dataset['data'].shape)) ###分割数据集,训练集占80% x_train,x_test,y_train,y_test = train_test_split(wine_dataset['data'],wine_dataset['target'],test_size = 0.2,random_state = 0) KNN_m = KNeighborsClassifier(n_neighbors = 10) #构建KNN分类模型,并指定k值,默认是5 KNN_m.fit(x_train,y_train) #训练模型 score = KNN_m.score(x_test,y_test) #预测正确的样本数占测试集总样本数的比例 print("预测正确的样本数占测试集总样本数的比例为:{}".format(score)) ###给出一组数据预测类别 x_wine_test = np.array([[11.8,4.39,2.39,29,82,2.86,3.53,0.21,2.85,2.8,.75,3.78,490]]) predict_result = KNN_m.predict(x_wine_test) print("该红酒的预测类别为:{}".format(wine_dataset['target_names'][predict_result])) -
输出结果
红酒数据集的键: dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names']) 数据集描述: (178, 13) 预测正确的样本数占测试集总样本数的比例为:0.7222222222222222 该红酒的预测类别为:['class_1']
5. 朴素贝叶斯
-
朴素贝叶斯是一种有监督学习的分类算法
-
贝叶斯定理
\(P(A|B)=\frac{P(B|A)P(A)}{P(B)}\)
-
朴素贝叶斯可以分为三种:多项式朴素贝叶斯(MultinomialNB)、伯努利分布朴素贝叶斯(BernoulliNB)、高斯分布朴素贝叶斯(GaussianNB)。分别适用于特征服从多项式分布、伯努利分布、正态分布的数据
-
代码(通过朴素贝叶斯分类算法对sklearn中的鸢尾花数据进行分类)
from sklearn.datasets import load_iris #导入鸢尾花数据集 from sklearn.naive_bayes import GaussianNB #导入朴素贝叶斯模型,选用高斯分类器 from sklearn.model_selection import train_test_split #导入分割数据集的方法 X,y = load_iris(return_X_y = True) #载入鸢尾花数据集 x_train,x_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state = 0) #分割数据集,测试集占20% bayes_model = GaussianNB() #构建分类器模型 bayes_model.fit(x_train,y_train) #训练数据 result = bayes_model.predict(x_test) #预测 print("预测的测试集中样本的分类结果是:\n{}".format(result)) model_score = bayes_model.score(x_test,y_test) #模型得分 print("测试集中预测正确的样本数占总样本数的比例为:{}".format(model_score)) -
输出结果
预测的测试集中样本的分类结果是: [2 1 0 2 0 2 0 1 1 1 1 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0] 测试集中预测正确的样本数占总样本数的比例为:0.9666666666666667
6. 决策树
-
决策树是一类有监督的分类学习算法
-
依据纯度选择决策树每一步的决策条件。纯度是对单一类别的样本在样本子集中所占比重的度量。我们要找到一个特征,使得通过该特征进行判别以后,划分出来的样本子集的纯度越高越好。某个分支节点下所有样本都属于同一个类别,纯度达到最高值;某个分支节点下样本所属的类别一半是正类一半是负类时,纯度取得最低值。
-
决策树算法的分类:ID3、C4.5、CART
- ID3通过信息增益选择判别条件
- C4.5通过信息增益比选择判别条件
- CART通过基尼系数选择判别条件
-
信息熵
-
信息熵是用于衡量不确定性的指标,越混乱信息熵越高。
-
信息熵的计算:\(H(X)=-\sum_{k=1}^Np_klog_2(p_k)\)
\(N\)表示类别数,\(p_k\)表示第\(k\)类在总样本中所占的比重。
-
-
信息增益(特征为离散型变量)
\(Gain(S,t)=H(S)-\sum_{k=1}^K\frac{|S^k|}{|S|}H(S^k)\)
\(Gain(S,t)\)表示以特征\(t\)作为判别条件时的信息增益,\(H(S)\)表示判别前总样本的信息熵,\(K\)表示判别后划分的子集个数,\(|S^k|\)表示第\(k\)个子集中的样本个数,\(|S|\)表示总样本个数,\(H(S^k)\)表示第\(k\)个子集的信息熵。
选取使得信息增益最大的特征作为当前的判别条件。
-
基尼系数
- 基尼值:\(Gini(S)=1-\sum_{k=1}^Np_k^2\)
- 基尼系数:\(Gini\_index(S,t)=\sum_{k=1}^K\frac{|S^k|}{|S|}Gini(S^k)\)
选取使得基尼系数最小的特征作为当前的判别条件。
-
决策树停止分裂的条件
- 子节点都属于同一类别
- 特征属性已用完
- 自己设置停止条件,可以通过设置决策树的最大深度或最大叶子结点个数
-
剪枝(为了防止过拟合)
- 预剪枝:在划分前就判断是否要剪枝,若判断为需要剪枝,则不进行划分
- 后剪枝:在决策树的各个判断分支形成以后再进行是否剪枝的判断
-
代码(sklearn.tree模块)
-
.DecisionTreeClassifier()
经典的决策树分类算法,参数
criterion有两个参数值,分别是gini(基尼系数)、entropy(信息增益),默认值是gini -
.DecisionTreeRegressor()
用决策树算法解决回归问题,也有
criterion参数 -
.ExtraTreeClassifier()
决策树分类,比.DecisionTreeClassifier()更具有随机性,首先从特征集中随机抽取n个特征构建新的集合,然后再从新的集合中选取判别条件
-
.ExtraTreeRegressor()
与.ExtraTreeClassifier()一样具有随机性,用于回归
##对sklearn中的红酒数据集进行分类 from sklearn.tree import DecisionTreeClassifier #导入分类器 from sklearn.datasets import load_wine #导入红酒数据集 from sklearn.model_selection import train_test_split #导入分割数据集的方法 import numpy as np #导入numpy模块 wine_data = load_wine() #加载红酒数据集 x_train,x_test,y_train,y_test = train_test_split(wine_data['data'],wine_data['target'],test_size=0.2,random_state=0) #将数据集划分为训练集和测试集,测试集比例20% tree_model = DecisionTreeClassifier(criterion='entropy') #创建决策树分类器,使用CART算法 tree_model.fit(x_train,y_train) #训练数据 score = tree_model.score(x_test,y_test) #模型得分 print('模型得分为:%f'% score) wine_test = np.array([[11.8,4.39,2.39,29,82,2.86,3.53,0.21,2.85,2.8,.75,3.78,490]]) predict_result = tree_model.predict(wine_test) print('预测的分类结果是:{}'.format(wine_data['target_names'][predict_result])) -
-
输出结果
模型得分为:0.916667 预测的分类结果是:['class_1']
7. 支持向量机(SVM)
-
有监督分类学习算法
-
支持向量机将样本点映射到高维空间,使得高维空间中的数据是线性可分的
-
sklearn.svm中包含的类
方法 描述 LinearSVC 基于线性核函数的支持向量机分类算法 LinearSVR 基于线性核函数的支持向量机回归算法 SVC 通过“kernel”参数可选择多种核函数的支持向量机分类算法
linear:选择线性函数;
polynomial:选择多项式函数;
rbf:选择径向基函数(默认值);
sigmoid:选择 Logistics 函数作为核函数;
precomputed:使用预设核值矩阵SVR 可选择多种核函数的支持向量机回归算法 NuSVC 与 SVC 相似,但可通过参数“nu”设置支持向量的数量 NuSVR 与 SVR 相似,但可通过参数“nu”设置支持向量的数量 OneClassSVM 用支持向量机算法解决无监督学习的异常点检测问题 在不知道使用哪种核函数最优时,可以使用径向基核函数。
-
代码(对sklearn中的红酒数据集分类)
from sklearn.datasets import load_wine #导入红酒数据集 from sklearn.svm import SVC #导入SVM模型 from sklearn.model_selection import train_test_split #导入分割数据集的方法 wine_data = load_wine() #载入红酒数据 x_train,x_test,y_train,y_test = train_test_split(wine_data['data'],wine_data['target'],test_size = 0.2,random_state = 1) #将数据集分为训练集和测试集 clf = SVC(kernel = 'rbf') #构建模型 clf.fit(x_train,y_train) #训练模型 score = clf.score(x_test,y_test) #模型得分 print('模型得分为:{}'.format(score)) y_predict = clf.predict(x_test) #预测测试集类别 print('测试集类别为:{}'.format(y_predict)) -
输出结果
模型得分为:0.6388888888888888 测试集类别为:[2 1 2 2 0 1 1 0 1 1 0 2 1 0 1 1 1 0 1 0 0 1 1 0 2 1 0 0 0 1 1 1 1 0 1 1]
8. K-means聚类
-
无监督学习算法
-
随机选择K个质心,分为K个类,计算每类的均值,作为新的质心,反复迭代下去,当质心不再变化时停止。
-
sklearn.cluster中包含的聚类方法
方法 描述 KMeans KMeans聚类 MiniBatchKMeans K-measn算法的变形算法,使用 mini-batch(一种采样数据的思想) 来减少一次聚类所需的计算时间,mini-batch 也是深度学习常使用的方法。 DBSCAN DBNSCAN 算法是一种比较有代表性的基于密度的聚类算法,它的主要思想是将聚类的类视为被低密度区域分割的高密度区域。与划分聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇。 MeanShift MeanShift 算法,以任意点作为质心的起点,根据距离均值将质心不断往高密度的地方移动,也即所谓均值漂移,当不满足漂移条件后说明密度已经达到最高,就可以划分成簇。 AffinityPropagation AffinityPropagation 算法(简称 AP 算法),该算法是层次聚类的典型应用,聚类实现过程是一个“不断合并同类项”的过程,用类似于归纳法思想来完成聚类。 -
代码(对sklearn中的鸢尾花数据集聚类)
from sklearn.cluster import KMeans #导入聚类方法 from sklearn.datasets import load_iris #导入鸢尾花数据集 import matplotlib.pyplot as plt #导入绘图包 iris_data = load_iris() #载入鸢尾花数据 k = 3 #设置簇的个数 x = iris_data['data'][:,:2] #使用鸢尾花数据的前两个特征进行聚类 km = KMeans(n_clusters = k) #创建聚类模型 km.fit(x) #对数据聚类 label_pred = km.labels_ #获得每个样本的类别编号 centroids = km.cluster_centers_ #获取簇的质心 ##绘图 plt.rcParams['font.sans-serif'] = ['SimHei'] #图中可以正常显示中文 plt.rcParams['axes.unicode_minus'] = False #图中可以正常显示负号 plt.subplot(131) #第一个子图 plt.scatter(x[:,0],x[:,1],s = 50) #绘制聚类前的散点图,点的大小设置为50 plt.title('聚类前') plt.subplots_adjust(wspace=0.5) #用于调整边距和子图间距 plt.subplot(132) #第二个子图 plt.scatter(x[:,0], x[:,1], c = label_pred, s = 50) #以聚类标签划分颜色 plt.scatter(centroids[:,0], centroids[:,1], c = 'red', s = 100) #画出质心点 plt.title('聚类结果') plt.subplot(133) #第三个子图 plt.scatter(x[:,0], x[:,1], c = iris_data['target'], s = 50) #以真实标签划分颜色 plt.title('真实类别') plt.show()
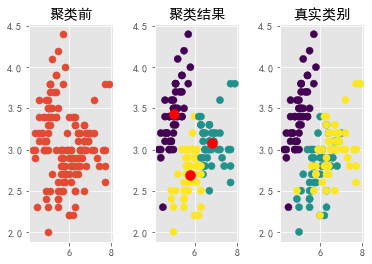
9. 神经网络
-
神经网络是一种有监督学习算法
-
神经网络分类的步骤
- 初始化神经网络中所有神经元节点的权值
- 根据输入层接收的输入值以及各个节点的权值,通过正向传播产生输出
- 根据输出的预测值与真实值,计算输出误差
- 通过反向传播算法更新所有节点的权值(通过梯度下降法更新,输出层的误差对权重求偏导,找出梯度下降的方向)
- 重复第2步到第4步,直到输出层误差最小
-
sklearn.neural_network提供了三种神经网络算法
- sklearn.neural_network.BernoulliRBM 伯努利受限玻尔兹曼机算法
- sklearn.neural_network.MLPClassifier 神经网络分类算法
- sklearn.neural_network.MLPRegression 神经网络回归算法
-
代码
from sklearn.neural_network import MLPClassifier #导入模型 from sklearn.datasets import make_classification #导入分类数据生成方法 from sklearn.model_selection import train_test_split #导入分割数据集方法 x,y = make_classification(n_samples = 100,random_state = 1) #生成数据 x_train,x_test,y_train,y_test = train_test_split(x,y,random_state = 2) #分割数据集 ##构建模型,hidden_layer_sizes设置隐藏层节点数,用列表或元组表示,默认是(100,); ## activation设置激活函数,默认是'relu'; ## solver设置权值优化方法,'lbfgs'在小数据集上可以更快更好的收敛,'adam'是默认值,在较大数据集上运行很好; ## alpha设置正则化项参数,默认是0.0001; ## max_iter设置最大迭代数,默认值200; ## tol设置迭代停止的阈值,默认值1e-4 clf = MLPClassifier(hidden_layer_sizes = (3,2),activation = 'logistic',solver = 'lbfgs',random_state = 1,max_iter = 500) clf.fit(x_train,y_train) #模型训练 y_predict = clf.predict(x_test[:5,:]) #预测测试集中前5个样本 print('测试集中前5个样本的预测类别是:{}'.format(y_predict)) pro = clf.predict_proba(x_test[:1]) #预测测试集中第一个样本属于各个类别的概率 print('测试集中第一个样本属于各个类别的概率是:{}'.format(pro)) score = clf.score(x_test,y_test) #模型得分 print('模型得分为:{}'.format(score)) -
输出结果
测试集中前5个样本的预测类别是:[0 0 1 0 1] 测试集中第一个样本属于各个类别的概率是:[[9.99910350e-01 8.96503715e-05]] 模型得分为:0.92
10. 集成学习算法
-
集成学习可以理解为一个组合了多种机器学习算法模型的框架,它关注的是框架内各个模型之间的组织关系,而不是某个模型的具体内部结构。
-
集成学习的组织方法
-
并联组织关系
并联的学习器之间是独立的,各自根据输入的数据完成训练,最终汇总所有单个模型的结果,作为输出。
-
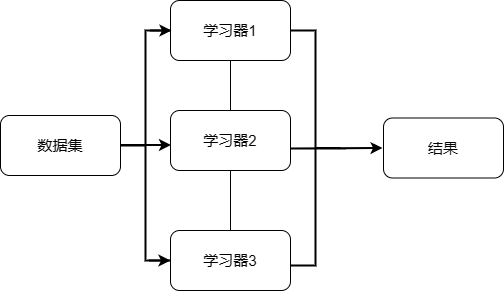
-
串联组织关系
几个学习器串联起来,第一个学习器拿到数据以后完成预测,将预测结果与数据都传输给第二个学习器,第二个学习器完成预测后将结果与数据继续传递下去,直到传到最后一个学习器。

-
汇总结果的方法
- 平均法(多用于回归)
- 简单平均法
- 加权平均法
- 投票法(多用于分类)
- 简单多数投票法
- 绝对多数投票法(最多的结果必须超过半数)
- 加权投票法
- 平均法(多用于回归)
10.1. 集成学习的主要实现方法
-
Bagging算法(并行式学习的典型代表)
该算法采用的数据集使用放回重抽样的方式获得,对于每个学习器,都采用这种方法获得采样集,一般会随机采集和训练样本数一样个数的样本,这样每个学习器得到的采样集个数相同,但样本内容不同。
-
Boosting算法(串行式集成学习算法)
-
Stacking算法(分层模型)
-
sklearn.ensemble模块包含了集成学习算法,主要有以下算法:
算法 说明 RandomForestClassifier 使用随机森林算法解决分类问题,它选择以 CART 决策树算法作为弱学习器 RandomForestRegressor 使用随机森林算法解决回归问题 ExtraTreesClassifier 使用极端随机树算法解决分类问题,极端随机树算法可以看作随机森林算法的一种变种,主要原理非常类似,但在决策条件选择时采用了随机选择的策略 ExtraTreesRegressor 使用极端随机树算法解决回归问题 AdaBoostClassifier 使用AdaBoost算法解决分类问题,AdaBoost算法是最知名的Boosting算法之一 AdaBoostRegressor 使用AdaBoost算法解决回归问题 GradientBoostingClassifier 使用Gradient Boosting算法解决分类问题,Gradient Boosting算法常常搭配CART决策树算法使用,这就是有名的梯度提升树(Gradient Boosting Decision Tree,GBDT)算法 GradientBoostingRegressor 使用Gradient Boosting算法解决回归问题
10.2. 随机森林算法示例
-
随机森林是是通过Bagging算法+决策树算法实现的,采用随机且有放回的方式抽样,每棵决策树之间相互独立,并且每棵决策树都从所有特征中随机选择部分特征进行分类或回归。
from sklearn.datasets import load_iris #导入鸢尾花数据集 from sklearn.ensemble import RandomForestClassifier #导入随机森林分类器 from sklearn.model_selection import train_test_split #导入分割数据集的方法 x,y = load_iris(return_X_y = True) #载入鸢尾花数据集 x_train,x_test,y_train,y_test = train_test_split(x,y) #分为训练集和测试集 clf = RandomForestClassifier() #创建随机森林模型,criterion参数可以选择'gini'或'entropy',选择使用哪种决策树,默认是基尼系数 clf.fit(x_train,y_train) #训练 print('模型预测准确率为',clf.score(x_test,y_test)) print('对测试集的预测结果为',clf.predict(x_test))###输出结果 模型预测准确率为 0.9473684210526315 对测试集的预测结果为 [2 2 1 2 2 1 0 2 1 2 1 1 2 0 2 1 2 0 1 0 1 0 2 0 2 0 0 1 1 0 1 1 1 0 0 0 0 2]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号