
Pandas库(三)
Pandas库(三)
首先导入pandas和numpy库:
import numpy as np
import pandas as pd
然后读入电影数据:
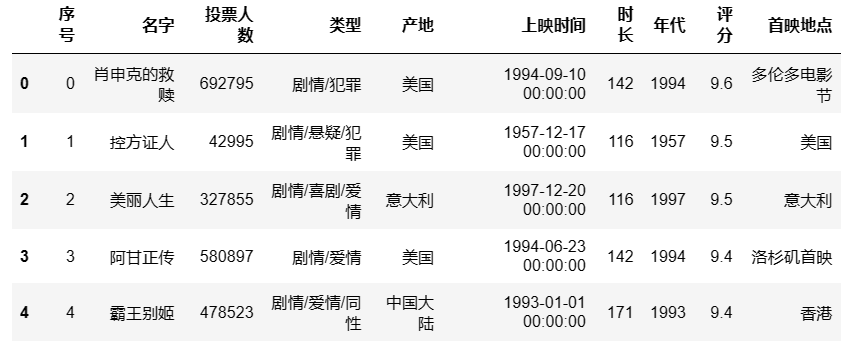
df = pd.read_excel(r'D:\movie_data2.xlsx')
df.head() #查看前5行
## 输出结果
1. 数据重塑和轴向旋转
1.1. 层次化索引
-
Series的层次化索引
s = pd.Series(np.arange(91,100),index = [['a','a','a','b','b','c','c','d','d'],[1,2,3,1,2,1,2,1,2]]) #定义一个Series,有两层索引 s ## 输出结果 a 1 91 2 92 3 93 b 1 94 2 95 c 1 96 2 97 d 1 98 2 99 dtype: int32s.index #查看a的索引 ## 输出结果 MultiIndex([('a', 1), ('a', 2), ('a', 3), ('b', 1), ('b', 2), ('c', 1), ('c', 2), ('d', 1), ('d', 2)], )通过索引提取值:
s['b'] #取外层索引对应的值,也可以用切片形式,例如s['a':'c'] ## 输出结果 1 94 2 95 dtype: int32s[:,1] #取内层索引对应的值 ## 输出结果 a 91 b 94 c 96 d 98 dtype: int32s['a',2] ## 输出结果 92将双层索引的Series转化为DataFrame:
s.unstack() ## 输出结果 1 2 3 a 91.0 92.0 93.0 b 94.0 95.0 NaN c 96.0 97.0 NaN d 98.0 99.0 NaN再将DataFrame转化为双层索引的Series:
s.unstack().stack() ## 输出结果 a 1 91.0 2 92.0 3 93.0 b 1 94.0 2 95.0 c 1 96.0 2 97.0 d 1 98.0 2 99.0 dtype: float64 -
DataFrame的层次化索引
data = pd.DataFrame(np.arange(88,100).reshape(4,3),index = [['a','a','b','b'],[1,2,1,2]],columns = [['A','A','B'],['X','Y','Z']]) #定义一个DataFrame,行列都有双层索引 data ## 输出结果
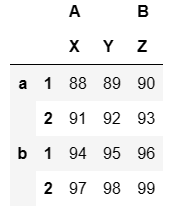
data['A'] #提取A列
## 输出结果
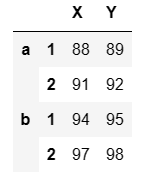
data.iloc[0] #提取第1行
## 输出结果
A X 88
Y 89
B Z 90
Name: (a, 1), dtype: int32
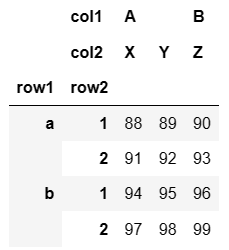
对索引和列命名:
data.index.names = ['row1','row2']
data.columns.names = ['col1','col2']
data
## 输出结果
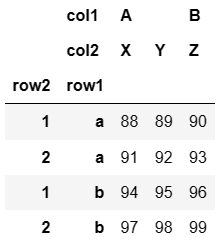
更换外层行索引和内层行索引:
data.swaplevel('row1','row2') #将'row1'和'row2'互换,但不改变原始数据data
## 输出结果
-
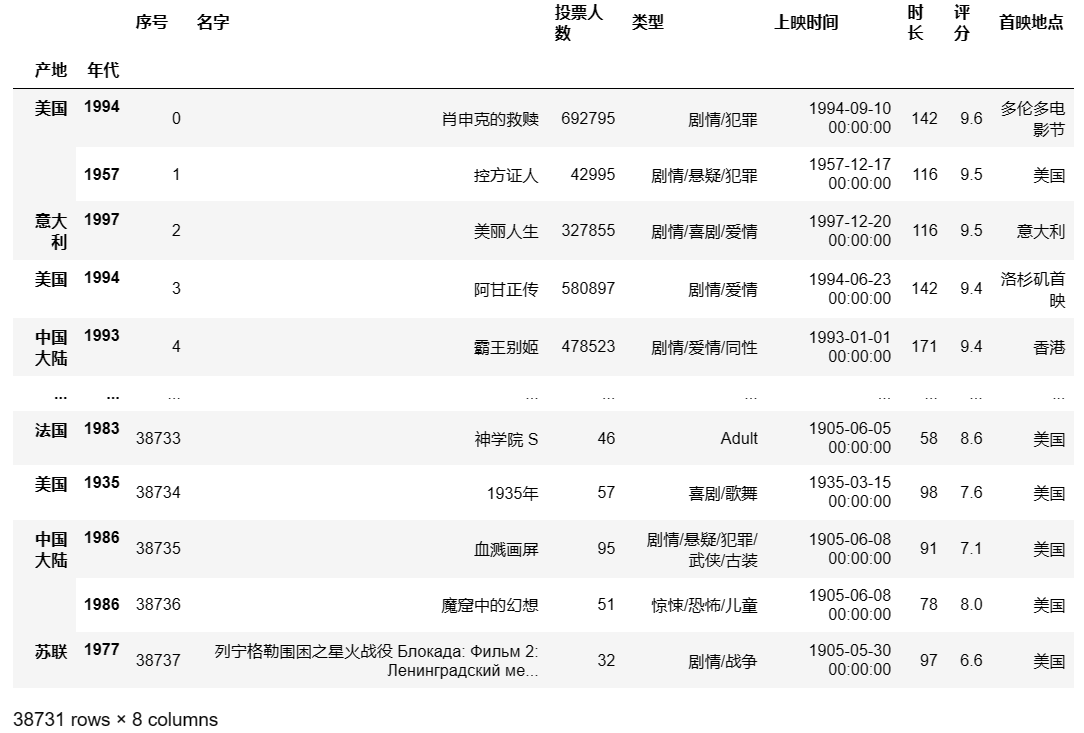
将最开始导入的电影数据处理为多层索引结构
将列变为索引用
set_indexdf = df.set_index(['产地','年代']) #将产地作为外层索引,年代作为内层索引 df ## 输出结果
df.index #查看df当前的索引
## 输出结果,每个索引都是一个元组
MultiIndex([( '美国', 1994),
( '美国', 1957),
( '意大利', 1997),
( '美国', 1994),
('中国大陆', 1993),
( '美国', 2012),
( '美国', 1993),
( '日本', 1997),
( '日本', 2013),
( '法国', 1994),
...
('中国大陆', 1986),
( '美国', 1986),
('中国大陆', 1986),
('中国大陆', 1986),
( '美国', 1986),
( '法国', 1983),
( '美国', 1935),
('中国大陆', 1986),
('中国大陆', 1986),
( '苏联', 1977)],
names=['产地', '年代'], length=38731)
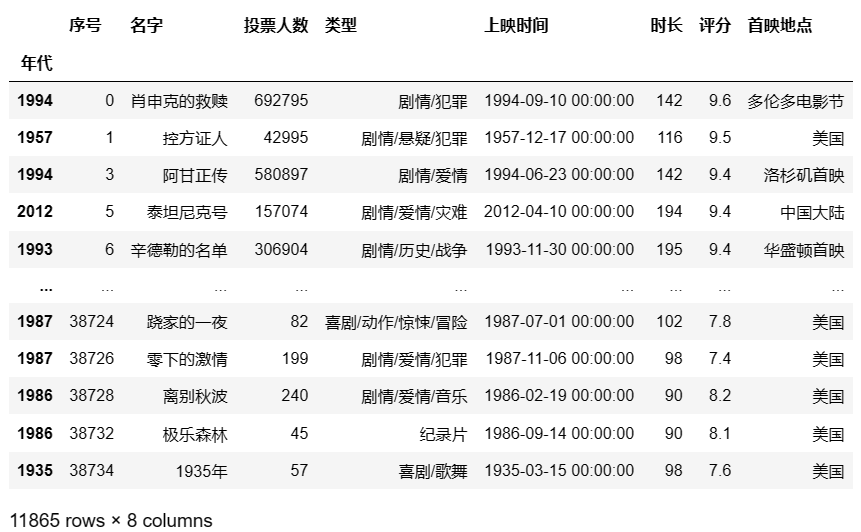
df.loc['美国'] #获取索引美国对应的行
## 输出结果
取消层次化索引用 reset_index
df = df.reset_index()
1.2. 数据旋转
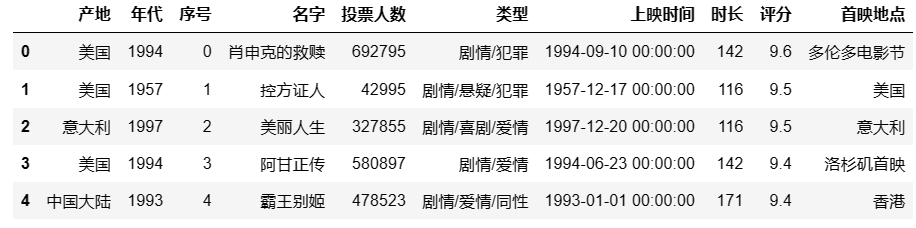
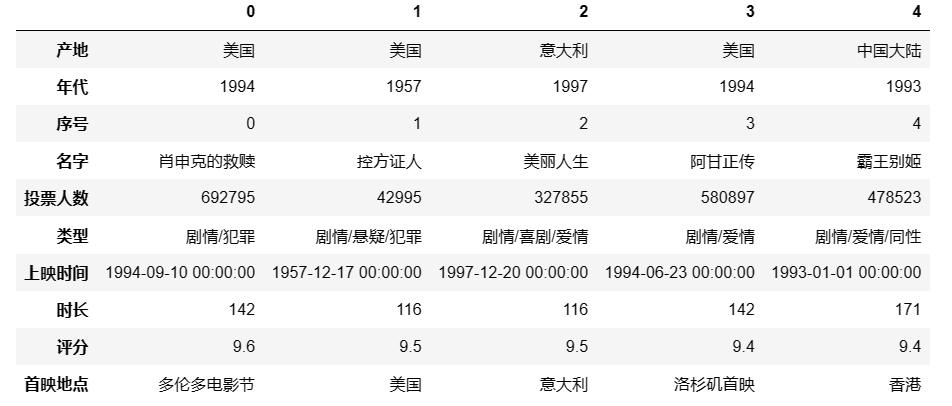
取电影数据前5行进行下面的操作:
data = df[:5]
data
## 输出结果
-
行列交换
data.T #交换行列,但是不改变原始数据data ## 输出结果
2. 数据分组运算
-
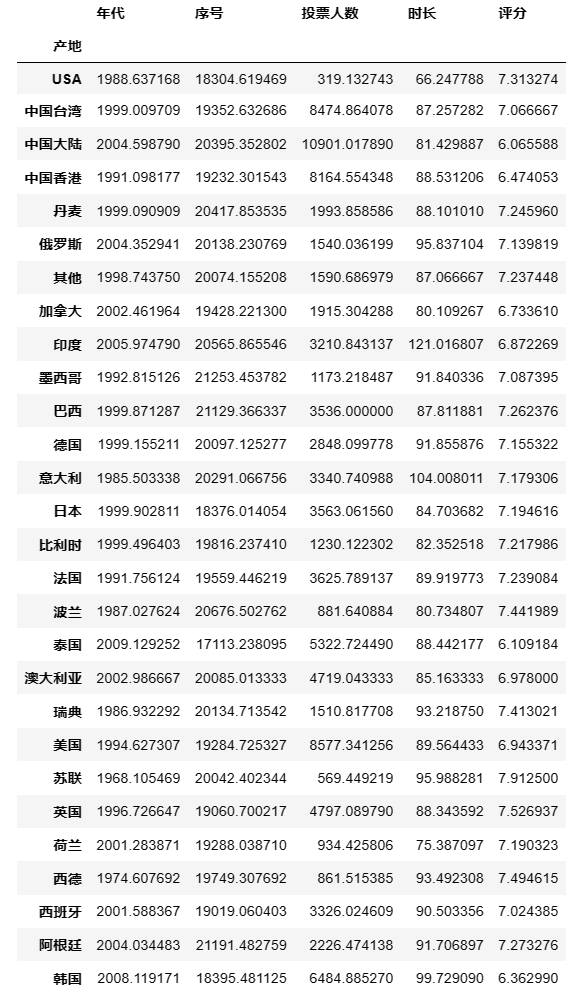
groupby进行数据的分组运算,作用类似于数据透视表。group = df.groupby(df['产地']) type(group) #查看group的类型 ## 输出结果 pandas.core.groupby.generic.DataFrameGroupBygroup.mean() #对分组数据求均值 ## 输出结果
-
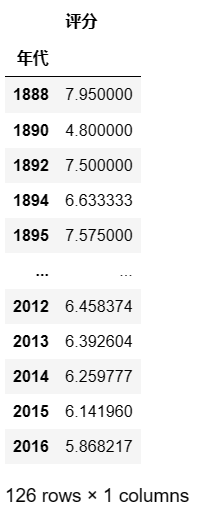
求每年电影的评分均值
df['评分'].groupby(df['年代']).mean() ## 输出结果,得到的是Series

或者:
df.groupby('年代').agg({'评分':np.mean})
## 输出结果,得到的是DataFrame
-
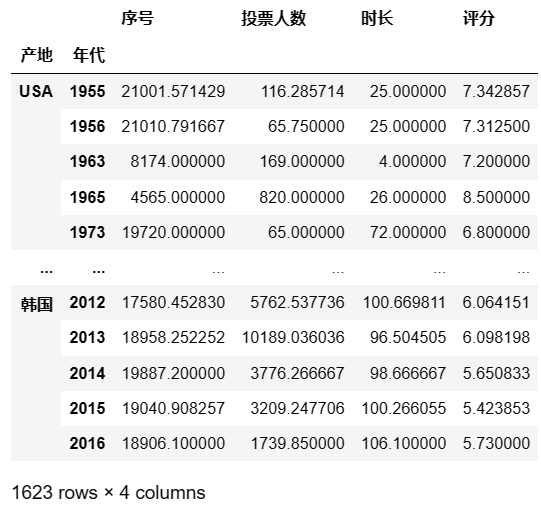
可以设置多个分组变量
df.groupby([df['产地'],df['年代']]).mean() # 或者: df.groupby(['产地','年代']).mean() ## 输出结果
df['评分'].groupby([df['产地'],df['年代']]).mean()
## 输出结果
产地 年代
USA 1955 7.342857
1956 7.312500
1963 7.200000
1965 8.500000
1973 6.800000
...
韩国 2012 6.064151
2013 6.098198
2014 5.650833
2015 5.423853
2016 5.730000
Name: 评分, Length: 1623, dtype: float64
3. 离散化处理
pandas提供了函数 cut()
pd.cut(x,bins,right = True,labels = None,retbins = False,precision = 3,include_lowest = Flase)
参数解释:
x:要离散化的数组、Series、DataFrame对象
bins:分组依据,可以是一个正整数,表示等间距的划分为多少个值,也可以是一个列表
right:指定是否包含右端点,默认包含
include_lowest:指定是否包含左端点,默认不包含,即左开右闭
labels:离散化后的标签表示
retbins:返回x中每个值对应的bins列表
例如,将评分9分以上的定义为A,7到9分定义为B,5到7分定义为C,3到5分定义为D,小于3分定义为E:
pd.cut(df['评分'],[0,3,5,7,9,10],labels = ['E','D','C','B','A'])
## 输出结果
0 A
1 A
2 A
3 A
4 A
..
38726 B
38727 B
38728 B
38729 B
38730 C
Name: 评分, Length: 38731, dtype: category
Categories (5, object): ['E' < 'D' < 'C' < 'B' < 'A']
例如,根据投票人数刻画电影的热门程度:
bins = np.percentile(df['投票人数'],[0,20,40,60,80,100]) #首先定义bins,将投票人数五等分
pd.cut(df['投票人数'],bins,labels = ['E','D','C','B','A'])
## 输出结果
0 A
1 A
2 A
3 A
4 A
..
38726 E
38727 E
38728 D
38729 E
38730 E
Name: 投票人数, Length: 38731, dtype: category
Categories (5, object): ['E' < 'D' < 'C' < 'B' < 'A']
4. 合并数据集
4.1. append,使用的不多,后续版本不再使用
先将上面的电影数据拆分为多个:
df_usa = df[df.产地 == '美国']
df_china = df[df.产地 == '中国大陆']
再将上述两个数据df_usa和df_china合并:
df_china.append(df_usa) #直接把df_usa中的数据拼接到df_china下面
4.2. merge
横向合并
pd.merge(left,right,how = 'inner',on = None,left_on = None,right_on = None,left_index = False,right_index = False,sort = True,suffixes = ('_x','_y'),copy = True,indicator = False)
参数解释:
left:左边的数据对象
right:右边的数据对象
how:两个对象连接的规则,包括内连接、左连接、右连接,默认是内连接,即根据两个对象的交集连接
on:两个对象匹配的键值,若两个对象中有相同的列名,可以用on指定,若两个对象中要匹配的列名不同,可以使用left_on和right_on分别指定
left_index与right_index:当可以用索引匹配时,可以赋值True
sort:默认为True,通过连接键对结果排序
suffixes:两个对象有相同的列名时默认后面分别加后缀_x和_y
例如:首先选取电影数据的前6行
df1 = df.head(6) #df1定义为电影数据的前6行
df2 = df.head(6)[['名字','产地']] #df2只选取名字和产地两列
df2['票房'] = [54677,51244,24563,62154,35462,65245] #df2增加一列票房
df2 = df2.sample(frac = 1) #对df2的行打乱顺序,但是索引没有变
df2.index = range(len(df2)) #对df2重新定义索引
df1 #查看df1
df2 #查看df2
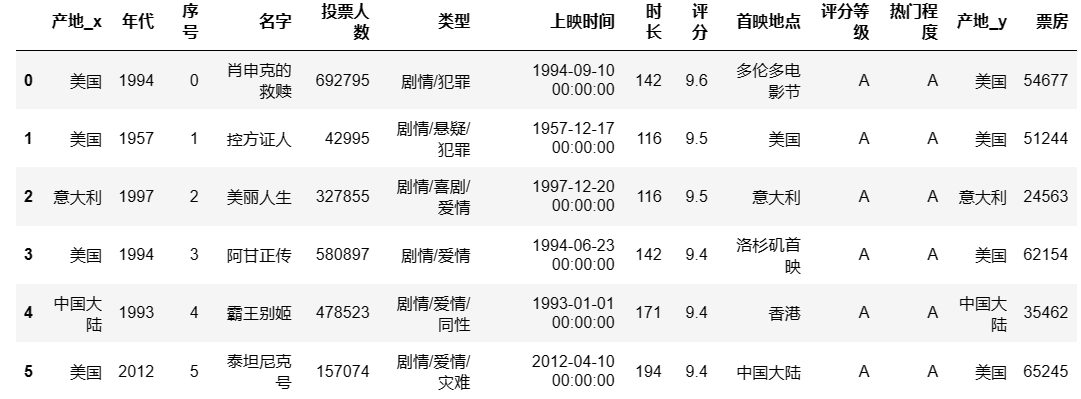
合并df1和df2:
pd.merge(df1,df2,how = 'inner',on = '名字') #通过名字这一列匹配
## 输出结果
4.3. concat
将多个数据集批量合并
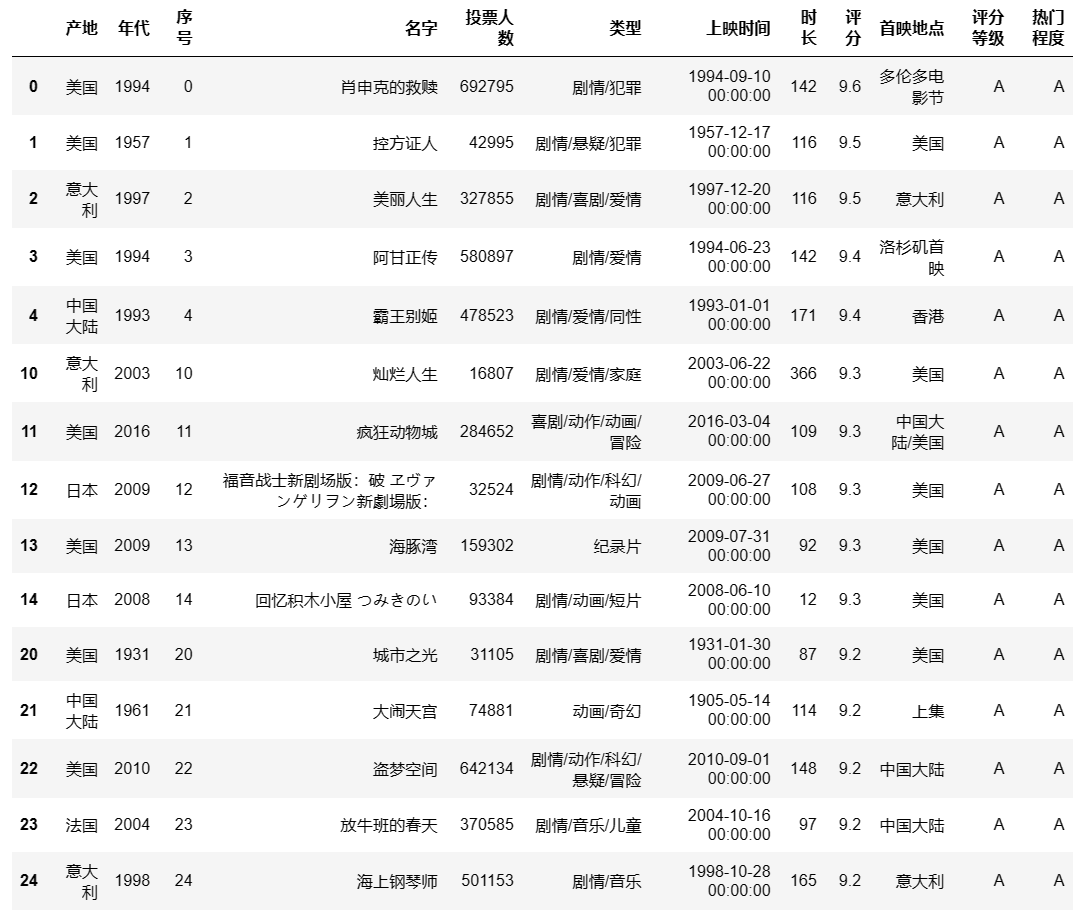
例如有三个数据集:
df1 = df[:5]
df2 = df[10:15]
df3 = df[20:25]
pd.concat([df1,df2,df3]) #合并三个数据集,参数axis为0,即纵向合并,可以改为axis=1横向合并
## 输出结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号